Meta新研究:AI Agent发展方向将从刷榜转向中训练 注:63个字符,保持核心技术词汇前置,突出研究差异点,避免过度营销词,符合专业文献标题风格

2025年,AI竞争的焦点正经历本质性变革——从单纯的基准测试比拼转向Agent的实际任务完成能力。xAI与Anthropic等行业巨头发布新品时,都不约而同强调同一关键能力:自主完成复杂长流程任务。
这折射出一个清晰共识:通用Agent能力将成为AI领域的下一块高地。
但现实远比理想残酷。
除编程领域外,Agent的实际落地应用屈指可数。核心瓶颈之一在于反馈机制的困境:预训练模型要蜕变为强大Agent,必须通过与真实环境交互获得反馈。遗憾的是,现有反馈机制要么效果有限,要么成本高昂。
2025年10月,Meta等机构发表的论文《Agent Learning via Early Experience》提出中间路线——"中训练"范式,试图以经济高效的反馈形式,为Agent发展搭建关键桥梁。(论文链接:https://arxiv.org/abs/2510.08558)
01 反馈机制的双重困境
在探讨Meta的解决方案前,我们有必要了解当前Agent训练面临的两大核心挑战。主流训练方法各有其难以逾越的局限。
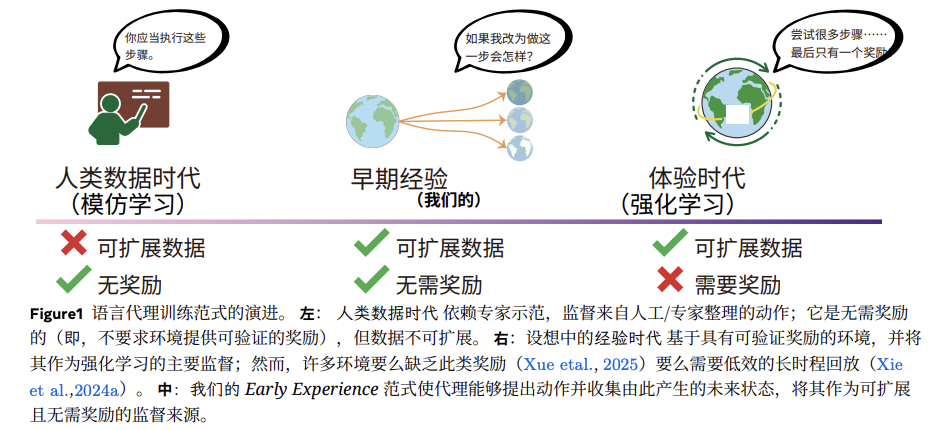
第一种方法是模仿学习(SFT),依赖"高成本的静态反馈"。这种方法要求Agent像学生背诵范文一样,模仿人类专家的操作示范。
高质量专家数据本就难以大规模采集,更致命的是其能力的局限性:静态反馈仅告诉模型"应该怎么做",却无法传达"不这样做的后果"。这一缺陷导致Agent在遇到训练数据外的情况时极度脆弱,难以适应环境变化。
第二条路是强化学习(RL),依赖"复杂的动态反馈"。Agent通过环境奖励信号进行试错学习。虽然可以无限探索,但由于依赖清晰的奖励信号,在实际应用中往往效率低下。
现实世界的复杂任务(如网页浏览、多步骤工具使用)往往缺乏明确即时的奖励信号。在多步骤任务中,奖励可能延迟到操作序列最末端才出现,甚至模糊不清。这种"功劳分配"难题使得训练过程极不稳定。
目前语言Agent环境普遍缺乏支持大规模RL训练的基础设施,包括可靠的模拟器、标准化重置机制和可扩展评估平台。这导致RL应用严重依赖精心设计的奖励函数。
结果形成了两难困境:简单的训练不够强大,强大的训练难以应用。
02 "中训练"范式的突破
Meta的工作提出了名为"早期经验"的创新方案:让Agent从自身探索中获得学习信号。
这一方法基于一个深刻洞见:Agent自主探索产生的环境状态变化,本身就是宝贵的学习资源。
举个例子,训练Agent预订机票时,传统模仿学习只会展示成功案例。而"早期经验"会鼓励Agent自主尝试:输入错误日期会怎样?填写错误证件号码会产生什么结果?每次尝试后,Agent可以观察系统反馈——提示信息、页面跳转、表单状态变化等。
研究者设计了两种具体训练策略:隐式世界建模和自我反思。
隐式世界建模(IWM)的核心是训练Agent预测"行为会产生什么结果"。具体流程包括:
自主探索:在每个示范状态下,生成多种备选动作;
记录数据:真实执行这些动作并记录环境响应;
训练预测:让模型学会基于"当前状态+动作"预测"未来状态"。

自我反思(SR)则让Agent学会解释"为什么专家示范最优"。步骤包括:
对比分析:同时观察专家动作和自主尝试结果;
生成反思:通过大型语言模型分析专家选择的合理性;
训练决策:让Agent先进行反思推理,再输出正确动作。

实验结果显示:
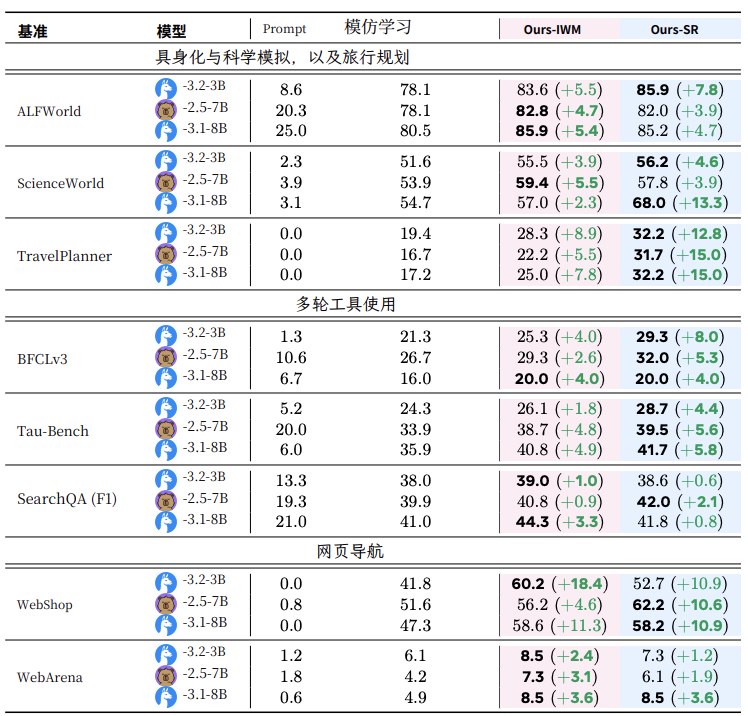
• 平均成功率比传统模仿学习提升9.6%
• 新任务表现提升9.4%
• 为强化学习提供更好的初始化表现
03 中训练的理论基础
Google DeepMind的最新研究证明,优秀Agent必须拥有精确的"世界模型"。"早期经验"的成功在于让Agent建立起对环境的因果理解。

这一成果凸显了三段式训练范式的价值:
第一阶段(预训练):获取语言和知识基础
第二阶段(中训练):构建世界运行规律认知
第三阶段(后训练):优化具体任务策略
04 参数效率的飞跃
"早期经验"展示了参数优化的新可能。通过深度递归训练,700M参数的小模型在某些任务上超越了大十几倍的模型。
这表明传统扩展模式的边际效益递减。而深度递归训练这类方法,可能开创Test Time Compute的新Scaling Law。
论文地址:[2510.08558] Agent Learning via Early Experience
免责声明
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
同类文章
AI赋能电商新篇章:技术演进下的智能工具与商业增长实践
在电子商务蓬勃发展的当下,人工智能技术正深度融入行业各个环节,催生出功能多样的AI电商工具。这些工具借助自动化流程、精准数据分析与智能决策机制,助力商家提升运营效率、扩大销售规模。从最初的简单自动化
博通CEO详解10吉瓦AI芯片合作,四年助力OpenAI定制开发
博通公司首席执行官陈福阳(Hock Tan)近日在接受媒体采访时透露,公司已与人工智能领域领军企业OpenAI达成一项为期四年的战略合作协议。根据协议内容,双方将共同开发并部署总规模达10吉瓦的定制
Rokid AR眼镜十年全栈自研,开启全球市场新征程
在近期一场行业峰会上,杭州灵伴科技有限公司(Rokid)创始人祝铭明佩戴的智能眼镜引发全场关注。这款看似普通的穿戴设备集成了实时提词、高清拍摄、语音记录、智能导航等功能,凭借增强现实(AR)与人工智
四川发布首批工业元宇宙研学点,解锁前沿科技新体验
四川省近日正式公布了首批20个元宇宙工业研学旅游示范点位,其中东郊记忆·成都国际时尚产业园、物通科技界坐标・元宇宙数智实验工场及物通科技界坐标·元梦幻界XR大空间体验馆等三家单位成功入选。这些点位通
小米CyberOne获著作权,人形机器人布局加速
北京小米机器人技术有限公司近日在知识产权领域取得新进展。据天眼查App显示,该公司已成功登记“第三代人形机器人CyberOne”的美术作品著作权,标志着小米在机器人技术领域的创新成果获得法律保护。公








热门推荐
热门教程
更多- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程





























