




SAM3开创视觉AI新范式:用「概念」重构视觉识别系统

2024年4月,Meta AI发布了首个图像分割基础模型Segment Anything Model(SAM)。 SAM的目标是让计算机「能分割任何东西」。 2024年7月,Meta推出SA
2024年4月,Meta AI发布了首个图像分割基础模型Segment Anything Model(SAM)。
SAM的目标是让计算机「能分割任何东西」。
2024年7月,Meta推出SAM 2,将模型扩展到视频分割并显著提升性能。

如今,SAM模型即将迎来第三次升级。

ICLR 2026会议盲审论文《SAM3:用概念分割一切》https://openreview.net/pdf?id=r35clVtGzw
论文《SAM 3: Segment Anything with Concepts》,也许可以带我们解锁这次SAM新升级的内幕。
该论文目前处于ICLR 2026会议盲审阶段,作者暂未公布身份,但从题目中不难推测其内容为SAM第三代的升级。
SAM3最大的突破在于它强调「基于概念的分割」,即不只是按像素或实例,而是可能按「语义概念」来理解和分割图像:
只要给出一个提示,比如「黄色校车」或一张参考图片,SAM 3就能在不同场景里找到并分割出对应的物体。
麻 将该功能被定义为可提示的概念分割(Promptable Concept Segmentation,PCS)。
为了支撑PCS,研究团队还构建了一个可扩展的数据引擎,生成了涵盖图像与视频的高质量数据集,包含约400万个不同的概念标签。
将「概念分割」引入SAM架构
SAM架构引入了「可提示分割」任务,可通过交互式提示分割图像与视频中的目标。
然而,早期的SAM 1和SAM 2更侧重视觉提示,并且每个提示仅分割单个对象实例。
这无法解决更普遍的问题:在任意图像或视频中,自动找到所有属于同一概念的对象。
比如,你输入「猫」,不仅是要找出一只猫,而是找出所有的猫。SAM 3正是为解决这一问题而推出的。
它相比较前代模型,不仅改进了可提示视觉分割(PVS),还开创了新的标准——可提示概念分割(PCS)。
PCS可以完成这样的任务:
模型可以根据提示(文字或图像),找出图像或视频中所有符合这个「概念」的对象,并保持每个对象的身份一致。
比如输入「红苹果」,模型会在不同帧中追踪每一个红苹果。
在实际使用中,用户还能通过交互方式(比如添加更多提示)逐步细化结果,解决模糊或歧义情况。
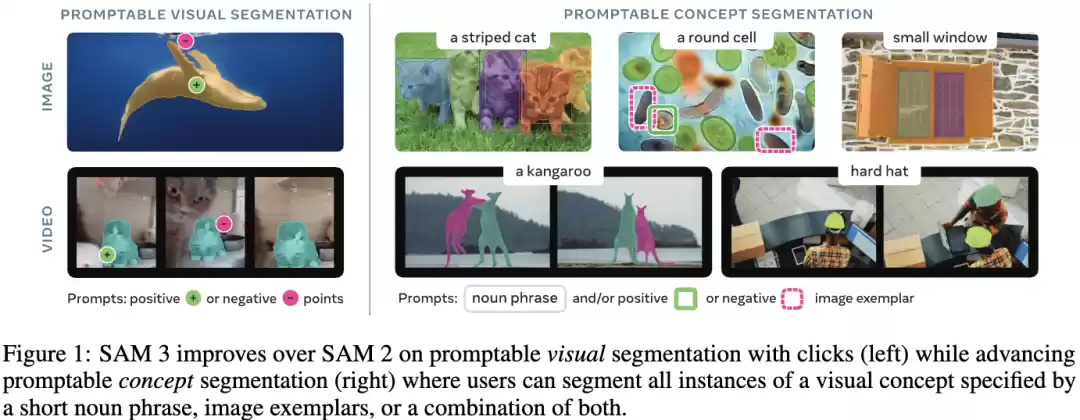
图1对比展示了SAM 3与SAM 2的核心区别,说明了从「可提示视觉分割」(PVS)到「可提示概念分割」(PCS)的进化。
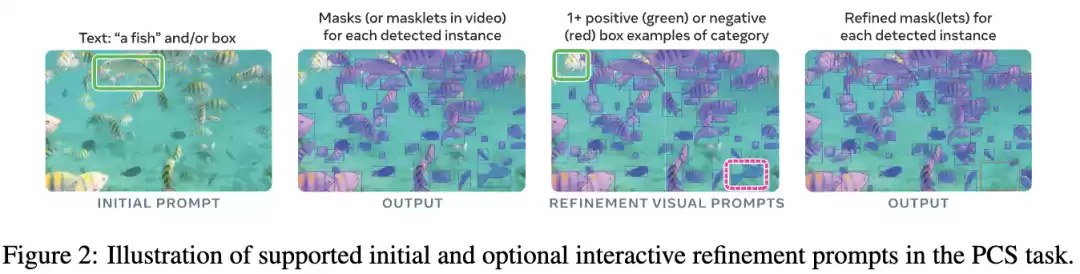
图2中展示了SAM 3如何从「理解一个提示」到「交互式细化分割结果」的全过程,它体现了PCS任务的核心特征——可提示、可交互、可概念化。
SAM 3系统实现了三大创新:
1. 更广的媒体域:不局限于同质化网页来源,涵盖更丰富的图像和视频场景;
2. 智能标签生成:使用多模态大模型(MLLM)作为「AI标注员」,生成更多样且有挑战性的概念标签;
3. 标签验证:通过微调MLLM使其成为高效的「AI验证员」,达到接近人类的表现,从而将标注吞吐量翻倍。
麻 将研究团队构建了一个包含400万唯一短语与5200万掩码的高质量训练数据集,以及一个包含3800万短语与14亿掩码的合成数据集,还推出了一个新的测试标准SA-Co基准。
实验结果显示,SAM 3在可提示分割上建立新SOTA,例如在LVIS数据集上,SAM 3的零样本分割准确度达到47.0(此前最佳为38.5)。
在SA-Co基准上表现提升至少2倍,并在PVS基准上优于SAM 2。
在一张H200GPU上,SAM 3只需30毫秒就能在单张图中识别上百个对象,视频场景中也能保持接近实时的处理速度。
可提示概念分割(PCS)
研究人员将PCS定义为如下任务:
给定一张图片或一段不超过30秒的视频,让模型根据一个概念提示(可以是文字、示例图像,或两者结合),去检测、分割并跟踪所有符合该概念的对象。
这些「概念」一般是由简单名词短语(noun phrase,NP)组成的,包含一个名词和可选修饰语,比如「红苹果」或「条纹猫」。
文字提示会对整张图片或整段视频都生效,而图像示例(例如框选某个目标)则可以用于细化结果,帮助模型更精确地理解「我说的就是这个」。
PCS的一个难点在于我们面对的「概念」范围几乎无限,这带来了很多歧义性。
这些歧义即使在封闭类别(如LVIS数据集)中也存在。
SAM3采取以下措施应对歧义:
多专家标注:每个测试样本由三位独立专家标注,确保结果更客观;
评估协议优化:评估时允许多种「合理答案」共存;
标注规范与数据清洗:在数据收集和指南中尽量减少歧义;
模型层面处理:在SAM 3中设计了专门的「歧义模块」,帮助模型理解并容忍这些模糊边界。
麻 将让分割模型能够理解「概念」
同时还要看得见、记得住
SAM 3是对前一代SAM 2的拓展与泛化。
它同时支持两类任务:
可提示视觉分割(PVS):根据几何或视觉提示(点、框、掩码)圈出指定物体;
可提示概念分割(PCS):根据概念提示(简短的文字或示例图像)识别并分割所有符合该概念的目标。
换句话说,SAM 3既能理解「我点的这个东西」,也能理解「我说的这个概念」。
下图3中展示了SAM 3架构,由一个双编码器-解码器Transformer组成:
检测器(Detector):负责在图像级别检测并分割目标;
跟踪器(Tracker):跟踪器继承了SAM 2的Transformer架构,负责在视频中跟踪已检测的目标。
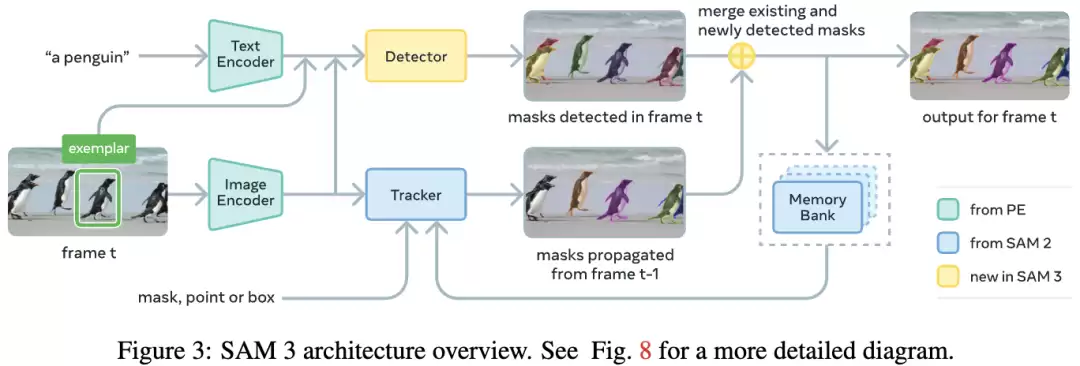
检测器和跟踪器分开运作,检测器只管发现目标,跟踪器才关注它们的身份,为了避免以上两种任务相互干扰,SAM 3引入了一个新的「存在性Token」,将识别与定位解耦。
人机协同的数据引擎
让模型实现「概念分割」能力
为了让SAM 3在可提示概念分割(PCS)上实现跨越式提升,它必须在更广泛的概念范围和更多样的视觉数据上进行训练。
为此,研究团队构建了一个高效的数据引擎,让人类标注员、AI标注员和SAM 3模型本身组成一个闭环系统,推动模型不断从自己的失败案例中学习。
通过这种方式,AI在一些标注环节上已经能达到甚至超过人类的准确度,使得整个数据生成效率提升了约一倍。
研究人员将数据引擎的建设分为四个阶段:
第1–3阶段仅针对图像,第4阶段扩展至视频。
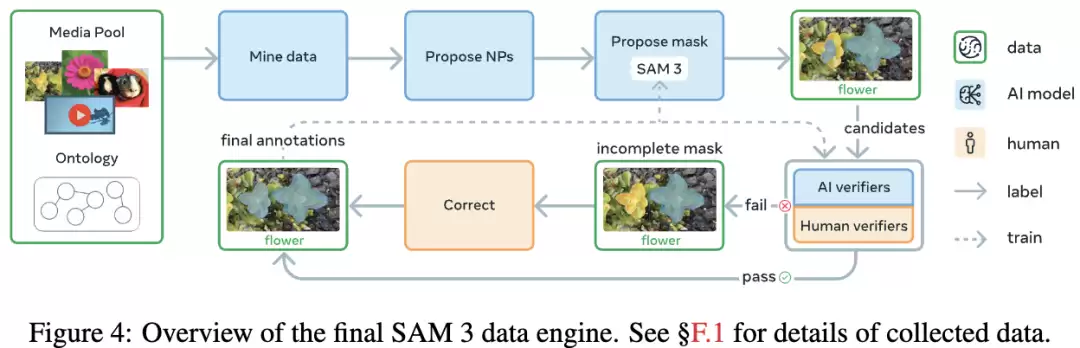
阶段1:人类验证。
初期阶段完全依靠人类验证。
研究者使用随机图像和简单文本描述器生成概念短语,掩码由SAM2与开放词汇检测器提供。
阶段2:人类+AI验证。
利用第一阶段积累的人类标签,团队微调Llama 3.2模型,让它学会自动执行MV与EV验证。
AI验证员可以直接判断「这个掩码对不对、全不全」,从而把人力解放出来,专注于最棘手的样本。
此时,AI已能自动发现对模型具有挑战性的「困难负样本」。
阶段3:扩展视觉领域
第三阶段把数据覆盖扩展到15个不同视觉域(例如自然场景、工业、艺术等)。
通过从alt-text(图像描述文本)和基于Wikidata的本体库(约2240万个概念节点)中提取新短语,系统进一步补充了长尾类与细粒度类别。

阶段4:视频标注
将数据引擎扩展至视频。
使用成熟的SAM 3模型,研究人员在运动、遮挡、跟踪失败等复杂场景中采集高质量标注,最终构建了SA-Co/VIDEO数据集,包含5.25万视频、2.48万唯一短语,总计13.4万视频-短语对。
这部分主要聚焦于模型容易出错的拥挤场景,以最大化学习效果。
SA-Co数据集
数据引擎最终生成了多层级的SA-Co数据集家族:
SA-Co/HQ:高质量人工与AI协作图像数据,包含520万张图像、400万个唯一短语;
SA-Co/SYN:全自动生成的合成数据;
SA-Co/EXT:整合15个外部数据集并补充困难负样本;
SA-Co/VIDEO:视频级标注数据集。
这些数据构成了目前世界上最大规模的开放词汇分割数据集体系。
为衡量模型在真实应用中的表现,研究人员设计了SA-Co基准(Benchmark),涵盖图像与视频共12.6万个样本、21.4万唯一短语,包含超过300万条标注。
经过研究人员评估,在图像和视频分割、少样本检测与多模态语言配合任务上,SAM 3全面超越现有系统,它在SA-Co的图像与视频PCS上将性能提升到以往系统的两倍。
与前代模型相比,SAM 3不再只是一个只会「按图索骥」的工具,而是逐步演变成一个能理解概念、识别类别、保持语义一致性的智能视觉系统。
它将图像分割从「点选式」操作提升到「概念级」理解,为下一代智能视觉和多模态系统奠定了基础。
也许,视觉AI的「GPT-3时刻」真的已经不远了。
参考资料:
https://openreview.net/forum?id=r35clVtGzw%20
https://openreview.net/pdf?id=r35clVtGzw

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Meta扎克伯格坦承AI智能体发展不及预期,超级智能仍需时间
IT之家 7 月 3 日消息,据《商业内幕》今天报道,Meta 首席执行官马克 · 扎克伯格在上周四的一场内部全员会中表示,公司仍在努力实现“超级智能”(Superintelligence),但目前还需要投入更多时间和精力。据两位参会人士透露,扎克伯格表示,Meta 正在向人工智能领域投入大量资源,

Agentic AI重构影像创作,影石Insta360联
全民影像记录时代到来,全景相机、运动相机、航拍无人机走进大众生活,每个人都能随手拍摄海量视频素材,但剪辑繁琐、高光筛选耗时、全景素材适配难等行业痛点始终未能彻底解决。市面上主流剪辑工具大多只聚焦后期编辑,平台适配流程复杂、模板同质化严重,针对360°全景画面的智能制作能力更是长期空白。与此同时,全球

微软Teams加强第三方AI智能体权限管理,需会议组织者确认后放行
IT之家 7 月 6 日消息,微软发文,宣布为 Microsoft Teams 会议应用推出全新的 AI 机器人管理策略,当第三方 AI 机器人尝试加入会议时,必须先获得会议组织者批准后才能进入。据介绍,目前微软已在 Teams 管理中心新增“Manage external bots and the

小猿AI接入多模态AI能力,推动智能学习体验升级
小猿AI升级为全学科AI学习助手,强化多模态能力,支持图像识别、文本理解与题目解析;拍照后可智能分析题型、匹配知识点并推荐练习;语文英语模块新增语句纠错、单词解释及作文辅助功能。小猿AI近期在产品能力上迎来重要升级,正式强化多模态AI能力,使其在图像识别、文本理解与题目解析方面表现更加全面。据产品体

阶跃AI推动多模态AI发展:语音与内容生成能力持续增强
阶跃AI正加速构建多模态AI能力,重点布局语音识别与生成、跨模态内容理解;强化语音交互,支持自然语音输入输出;提升图文理解能力,拓展至营销文案、知识整理等智能写作场景;向全面智能助手演进。阶跃AI正在加速推进多模态AI能力建设,重点布局语音识别、语音生成以及跨模态内容理解能力。在最新技术方向中,阶跃








- 热门数据榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2026-07-13 14:19
2026-07-13 14:16
2026-07-13 13:55
2026-07-13 13:55
2026-07-13 13:55
2026-07-13 13:55
2026-07-13 13:55
2026-07-13 13:55
热门教程
2026-07-13 14:19
2026-07-13 14:16
2026-07-13 13:55
2026-07-13 13:55
2026-07-13 13:55
2026-07-13 13:55
2026-07-13 13:55
2026-07-13 13:55
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
