




MIT新框架实现AI自主微调:无需人工生成数据,自动完成权重升级

大模型终于学会更新自己了!
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
MIT提出一种新的强化学习框架,让模型生成微调数据和自我更新指令,实现模型权重的更新。
无需人工参与,模型就可以自动进行梯度更新,自主学习获取新知识或适应新任务。

该框架名为SEAL(Self-Adapting LLMs),是一种内外两层嵌套的学习机制。
这种机制下,会根据更新后的模型在任务上的表现计算奖励,进一步优化自我更新指令的生成策略。
SEAL首次在权重层面赋予了大模型自我驱动的更新能力,摆脱了完全依赖外部监督数据的局限。
模型自动学习知识更新策略
SEAL在论文中通过两个主要实验任务验证其效果,分别是知识注入(knowledge incorporation)和小样本学习(few-shot learning)。
这两类任务分别对应模型进化中的两种基本情境——记住新知识,以及快速适应新任务。
知识注入
在知识注入实验中,研究者使用了Qwen2.5-7B模型和SQuAD数据集中的段落及对应问题。
每轮训练开始时,模型接收到一个新的段落作为输入上下文,但不会看到与之配套的问题答案。
模型首先根据这段输入生成训练数据,然后使用LoRA进行一次小规模微调,该过程仅基于生成后的数据,不包括原始段落或问题。
微调完成后,模型会在下游任务上接受评估,需要在没有原始段落作为输入的情况下,回答多个与该段落相关的问题。

实验对比了以下几种方案:
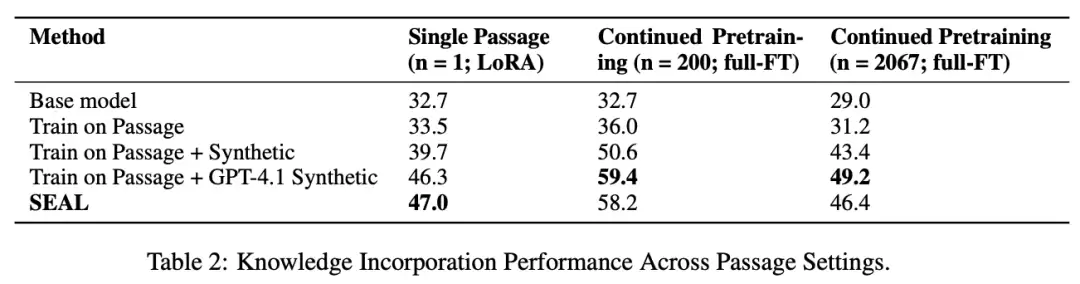
仅用原始段落微调; 使用GPT-4.1生成的implication句子辅助训练; 用SEAL自身生成的数据微调。在单段落场景下,Qwen原始模型的准确率为32.7%,使用原文微调提升至33.5%;加入GPT-4.1合成数据后达到46.3%;而使用SEAL方法进行微调后,准确率进一步提升至47.0%。
这说明SEAL不仅优于使用原文或非优化的生成数据,甚至能超越由GPT-4.1生成的高质量提示数据,表现出较强的知识整合能力。
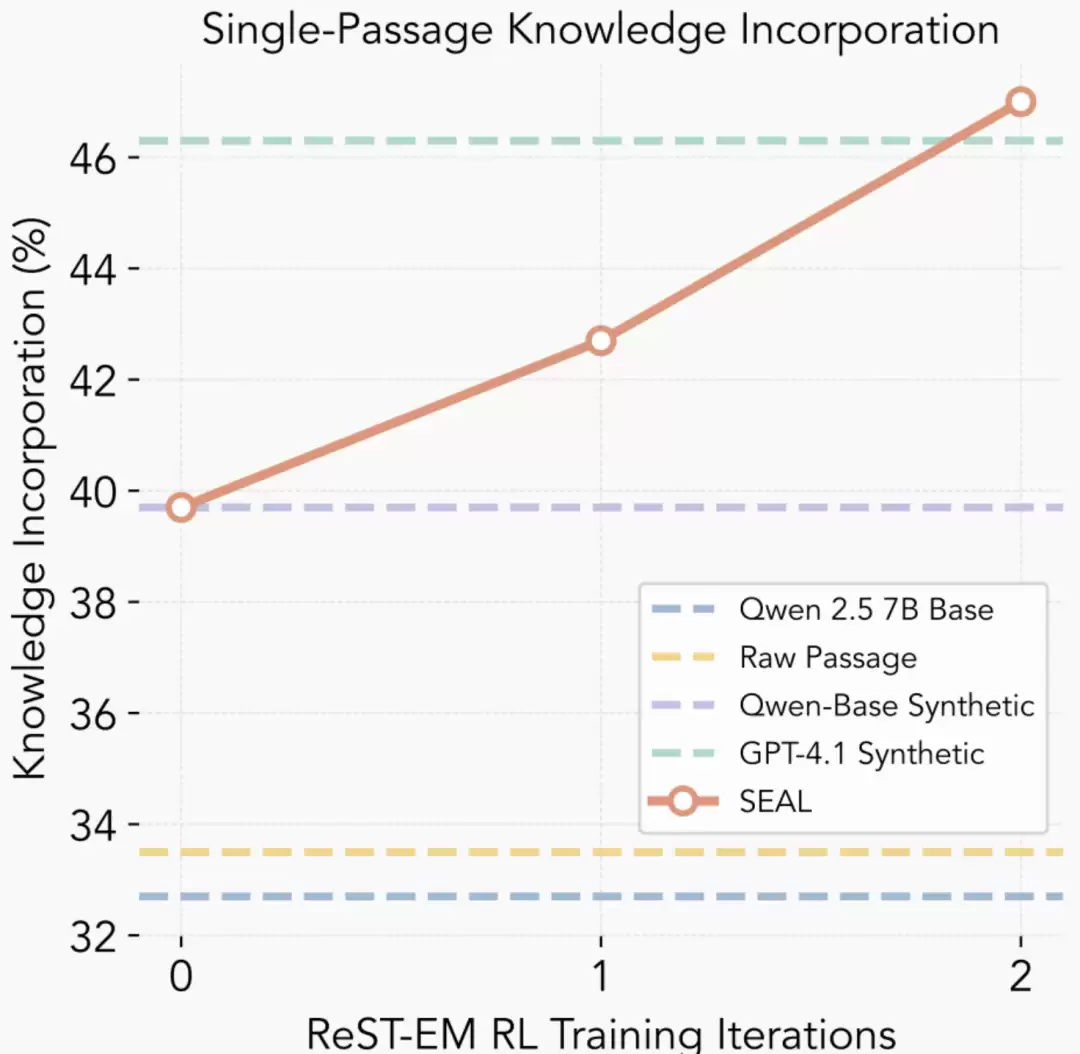
此外,研究者还使用了篇幅更长的段落进行了测试,包括200段落和完整SQuAD验证集(2067段落),SEAL在200段落设置下达到了58.2%的准确率,显著高于未优化版本,说明SEAL可以泛化到更大规模的数据整理任务。
小样本学习
在小样本学习实验中,研究者使用LLaMA-3.2-1B-Instruct模型和ARC-AGI数据集中经过筛选的任务子集。
ARC任务通常包括若干个示例的图形变换(以文本形式表达)输入输出对,目的是从中学习规律并对一个新输入做出预测。
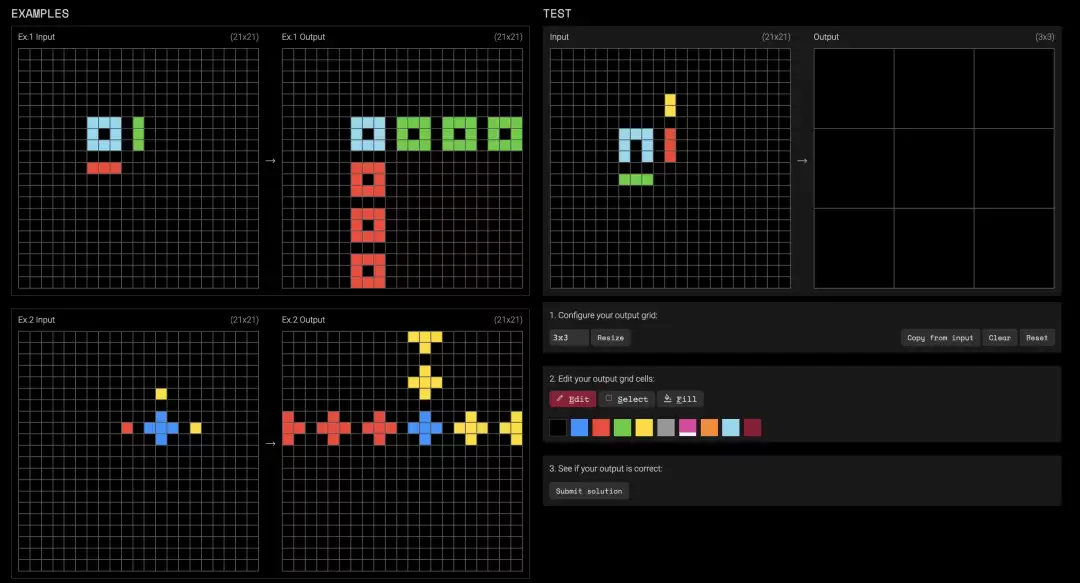
SEAL接收到这些示例后,不会直接推理,而是生成一个训练配置,并执行LoRA微调,随后模型在该任务的测试输入上进行预测。
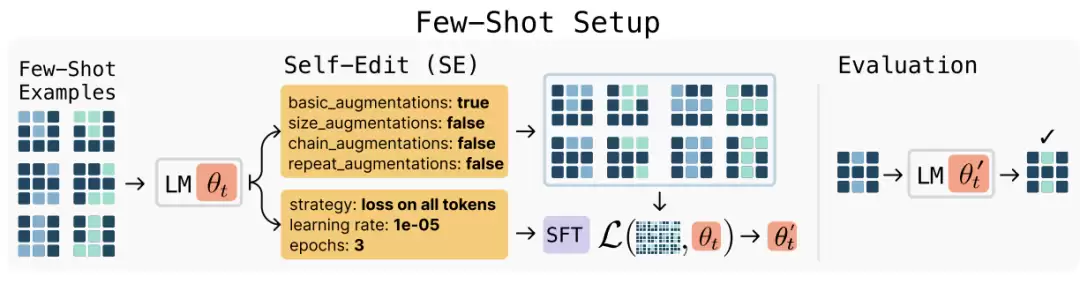
结果显示,SEAL训练出的策略使得任务成功率达到72.5%,远高于仅使用固定few-shot提示的0%,也明显优于随机采样策略下的20%。
虽然不及人工设定的最优策略(Oracle TTT)的100%,但作为由模型自主摸索出的学习路径,这一成功率已充分说明SEAL具备较强的任务适应能力。

那么,SEAL框架是如何工作的呢?
双循环系统自动生成训练指令
SEAL的工作过程简单说就是读取新信息,用自己的语言重写,并进行梯度更新,实际上是进行自主学习。
结构上,SEAL的整个系统由两部分构成——一个强化学习驱动的外部循环和一个用于执行参数更新的内部循环。

在外层,模型面对一个新的输入上下文(比如一段文本或任务示例),首先生成一条self-edit指令。
这是一段自然语言组成的“微调指令”,描述模型应如何基于当前输入来更新自己,包括提取什么样的信息、生成哪些训练样本、使用什么训练参数(例如学习率、训练轮数、损失函数策略)等。
这一行为本质上是模型在设计自己的训练流程。
随后进入内层,模型按照self-edit的指令,执行一次微调。
这一步会构造合成训练数据,可能包括推理句、问答对、重述信息,或者针对任务的具体样本变换,并以指定的优化策略进行权重更新。
更新后得到的新模型将被立即用于解决相应任务(比如回答相关问题或完成预测),评估其效果,得出一个表现评分。
这个评分(reward)反映了该self-edit对性能提升的效果,进而用于生成下一步的self-edit策略。
为了完成这个策略优化,SEAL使用的是一种非传统的强化学习方法,称为ReSTEM(Reinforcement Learning with Sampled Trajectories and Expert Mimicry)。

其关键思路不是直接对reward进行梯度回传,而是采取一种行为克隆+过滤采样的方式。
具体来说,在每个上下文中,模型会生成多个self-edit候选,每个候选会被分别应用,执行一次微调,得到一个新模型。
然后会对新模型在任务上的表现进行评估,只有带来性能提升的self-edit才会被保留。
接着用这批“有效”的self-edit作为训练数据,对生成策略进行一次有监督微调(行为克隆),然后反复迭代,使得模型越来越倾向于生成有效的self-edit。
ReSTEM本质上是一个期望最大化过程,相比PPO等策略梯度方法,ReSTEM结构更简单,训练更稳定,同时也更适用于大模型的生成行为学习任务。
通过这一套机制,SEAL实现了“学会如何让自己学得更好”。
模型不仅能通过已有数据完成任务,更能主动设计训练方式、构造训练数据,并不断通过反馈优化这种“自学习”的策略。最终表现为一种具备自我编辑与持续进化能力的语言模型结构。
论文地址:https://arxiv.org/abs/2506.10943
项目主页:https://jyopari.github.io/posts/seal

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

AI能从单份血样检出多种神经疾病
来源:科技日报科技日报讯 (记者刘霞)由瑞典隆德大学领衔的国际研究团队,研发出一款新的人工智能(AI)模型。该模型仅需一份血液样本,便能精准识别多种神经退行性疾病。团队期望,该AI模型未来能实现“一
褪去虚火,脑机接口方能释放长远价值
来源:科技日报2026年开年,马斯克宣称脑机接口产品将于年内启动量产,引爆全球市场情绪。国内资本随即扎堆追捧,脑机接口相关概念股大幅走高,行业短期炒作虚火蔓延。进入3月,脑机接口迎来多重利好:脑机接
黎万强、洪锋退出小米科技股东名单
人民财讯4月7日电,企查查APP显示,近日,小米科技有限责任公司发生工商变更,原股东小米联合创始人黎万强、洪锋退出,同时,注册资本由18 5亿元减至约14 8亿元。 企查查信息显示,该公司成立于20
新闻分析|“阿耳忒弥斯2号”任务为何只绕月不登月
新华社北京4月7日电 新闻分析|“阿耳忒弥斯2号”任务为何只绕月不登月 新华社记者张晓茹 美国东部时间6日18时40分许(北京时间7日6时40分许),执行美国“阿耳忒弥斯2号”载人绕月飞行任

“链接未来·智汇静安”区块链创新应用优秀场景分享(四)| 信医基于区块链与隐私计算的真实世界研究数据产品
聚焦数字技术,释放创新动能。为集中展示静安区区块链技术从“实验室”走向“应用场”的丰硕成果,挖掘一批可复制、可推广的行业解决方案,加速构建区块链产业生态闭环,静安区数据局特推出“静安区区块链创新应用








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程























 热门话题
热门话题
