




如何用perf和火焰图快速定位CPU性能瓶颈

排查线上服务性能问题,最让人头疼的场景莫过于:CPU占用率居高不下,但代码逻辑看上去一切正常。加日志、看监控、凭经验猜测,几个小时过去,问题依旧悬而未决。
其实,在Linux系统里,有一个堪称“性能排查终极武器”的组合:内核自带的perf工具,配上直观的火焰图。它最大的优势在于,无需修改一行代码,也无需重启服务,只需对正在运行的程序执行一条命令,几分钟内就能告诉你,CPU时间究竟花在了哪些函数上。

一、perf 是什么?一句话说清楚
perf的原理非常直接,属于采样分析(Sampling Profiler)。它每隔一个固定时间(例如10毫秒)中断一次CPU,记录下此刻正在执行的函数及其完整的调用栈。采样结束后,统计每个函数被“抓到”的次数——次数越多,自然意味着CPU花在它身上的时间越长。
这种方法完全无侵入,不需要在代码中插入任何探针,也无需重新编译程序,直接对任何运行中的进程都有效。
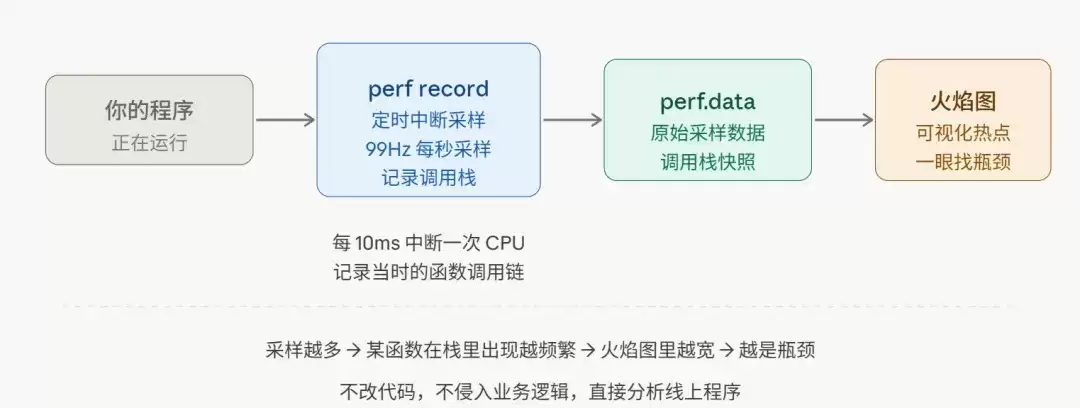
上图清晰地展示了标准流程:perf record进行采样,生成perf.data数据文件,最后将其转换为可视化的火焰图。
二、先装好工具
首先,确保系统已安装perf工具:
# Ubuntu/Debian
sudo apt install linux-tools-common linux-tools-generic
# CentOS/RHEL
sudo yum install perf
# 验证安装
perf version接着,获取业界标准的火焰图生成脚本:
git clone https://github.com/brendangregg/FlameGraph.git
# 建议将此目录加入PATH环境变量,方便后续直接调用三、最常用的三个命令
掌握以下三个命令,足以应对80%的性能分析场景。
(1) 分析一个正在运行的程序(最常用)
# 对 PID 为 1234 的进程采样 30 秒,采样频率为 99Hz
sudo perf record -F 99 -p 1234 -g -- sleep 30
# -F 99 : 每秒采样 99 次(避开100Hz的系统定时器,避免采样偏差)
# -p 1234 : 指定目标进程的PID
# -g : 记录完整调用栈(生成火焰图的关键)
# sleep 30: 控制采样持续时间为30秒(2) 直接启动程序并分析
sudo perf record -F 99 -g ./myprogram arg1 arg2(3) 生成火焰图(三步走,固定套路)
# 第一步:将 perf.data 转换为文本格式
perf script > out.perf
# 第二步:折叠调用栈(聚合相同的栈)
./FlameGraph/stackcollapse-perf.pl out.perf > out.folded
# 第三步:生成 SVG 格式的火焰图
./FlameGraph/flamegraph.pl out.folded > flame.svg
# 用浏览器打开查看
# Linux 上可以使用
xdg-open flame.svg
# 或者直接指定浏览器
firefox flame.svg
google-chrome flame.svg完成这三步,你将得到一张交互式的SVG火焰图,鼠标悬停可以查看函数名,点击任意色块可以放大查看细节。
四、怎么看火焰图?
初次接触火焰图可能会感到困惑,其实看懂它只需记住三条核心规则:
(1) 横轴代表时间占比,越宽越慢
一个函数在图上占据的横向宽度,直接反映了CPU花费在其上的时间比例。寻找最宽的色块,就是定位性能瓶颈的关键。
(2) 纵轴代表调用深度,从下往上读
最底层通常是main()或线程入口函数,往上是它调用的函数,再往上则是更深层的调用。火焰的“尖端”就是最终消耗CPU的函数。
(3) 颜色是随机的,不代表任何意义
火焰图的颜色仅用于区分不同的函数块,没有特殊含义,不必过度解读。
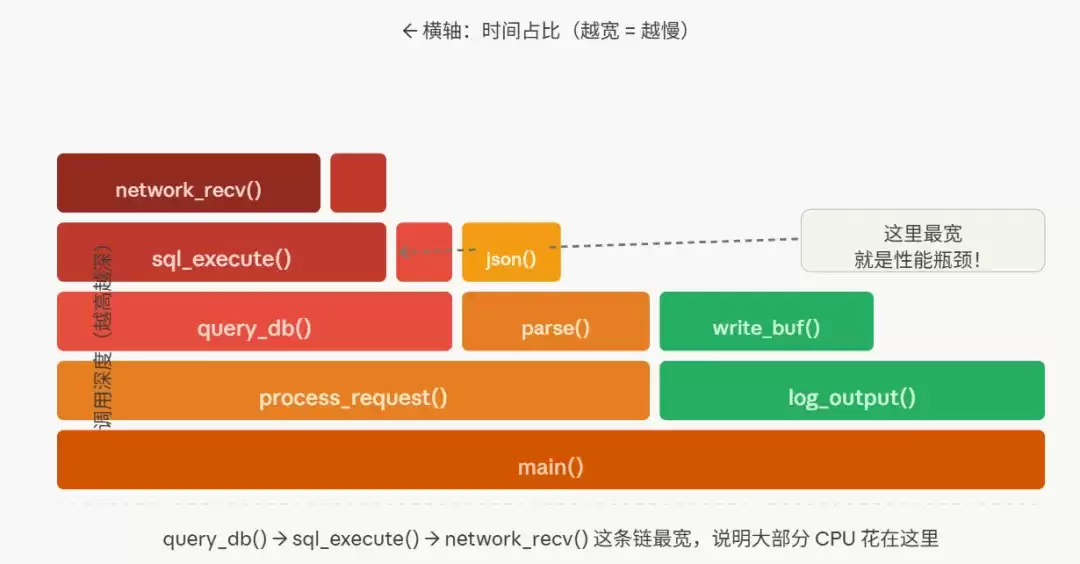
观察上图,规律一目了然:从底部开始,找到最宽的那一列“火焰”,其顶端的函数就是最需要优化的目标。
五、一次完整的排查实战
假设有一个C++程序启动后CPU持续占用90%,我们来模拟一次完整的排查过程。
第一步:找到目标进程的PID
ps aux | grep myserver
# 或者使用 pidof
pidof myserver第二步:进行30秒采样
sudo perf record -F 99 -p $(pidof myserver) -g -- sleep 30
# 采样完成后,当前目录会生成 perf.data 文件第三步:生成火焰图
perf script | ./FlameGraph/stackcollapse-perf.pl | ./FlameGraph/flamegraph.pl > flame.svg第四步:在浏览器中分析
打开生成的flame.svg文件。这张图是交互式的:鼠标悬停可查看完整函数名;点击任意色块可放大该层级的调用详情;使用Ctrl+F可以搜索特定函数名并高亮显示。
六、perf stat:先看全局,再找热点
在进行详细的火焰图分析之前,不妨先用perf stat快速浏览程序的整体性能指标,这有助于把握大致方向。
sudo perf stat -p 1234 sleep 10输出结果通常如下:
Performance counter stats for process id '1234':
12,345.67 msec task-clock # 12.3 CPUs utilized
1,234 context-switches # 0.1 K/sec
123 cpu-migrations # 0.010 K/sec
45,678 page-faults # 3.7 K/sec
32,100,456,789 cycles # 2.6 GHz
15,678,901,234 instructions # 0.49 insn per cycle ← 关键指标
3,456,789,012 branches
45,678,901 branch-misses # 1.32% of all branches这里有一个关键指标:insn per cycle (IPC),即每时钟周期执行的指令数。
- IPC 接近 1~4:程序属于计算密集型,CPU在高效工作。
- IPC 很低(如 0.3):CPU大量时间在“空转”等待——可能是等待内存访问、I/O操作或锁竞争。
IPC低的程序,瓶颈往往不在算法本身,而在于内存访问模式不佳或锁竞争激烈。
七、几个实用的进阶参数
# 只记录用户态调用栈(过滤内核调用,使热点更清晰)
perf record -F 99 -p 1234 -g --call-graph dwarf -- sleep 30
# --call-graph dwarf 对没有frame pointer的程序回溯更准确
# 同时追踪进程下的所有线程
perf record -F 99 -p 1234 -g -t -- sleep 30
# 只统计特定类型的事件(例如缓存未命中)
perf record -e cache-misses -p 1234 -- sleep 10关于编译选项,有一个关键点需要注意:为了在火焰图中看到清晰的函数名而非内存地址,建议在编译时加上调试信息和帧指针选项。
# 带调试信息编译
g++ -g -fno-omit-frame-pointer -O2 myapp.cpp -o myapp
# ^^^^^^^^^^^^^^^^^^^
# 此选项确保perf能正确回溯调用栈八、看火焰图时真正会遇到的四种情况
以下是实践中最常见的四种火焰图形状,每种都指向不同的性能问题根源。
1. 情况一:有一个又宽又平的顶——CPU 密集型热点
这是最理想、也最常见的情况。某个函数的色块在顶部异常宽阔,如同一片高原,明确指示CPU大量时间消耗于此。
处理方式:直接优化该函数。检查其算法复杂度、减少不必要的计算、或更换更高效的数据结构。

2. 情况二:大量[unknown]或地址,看不到函数名
新手最容易踩的坑。火焰图中间出现大片[unknown]或十六进制地址,无法识别具体函数。
主要原因有两个:一是编译时使用了-fomit-frame-pointer优化(默认开启),导致帧指针被省略,perf无法回溯调用栈;二是分析的二进制文件被剥离(stripped)了符号表。
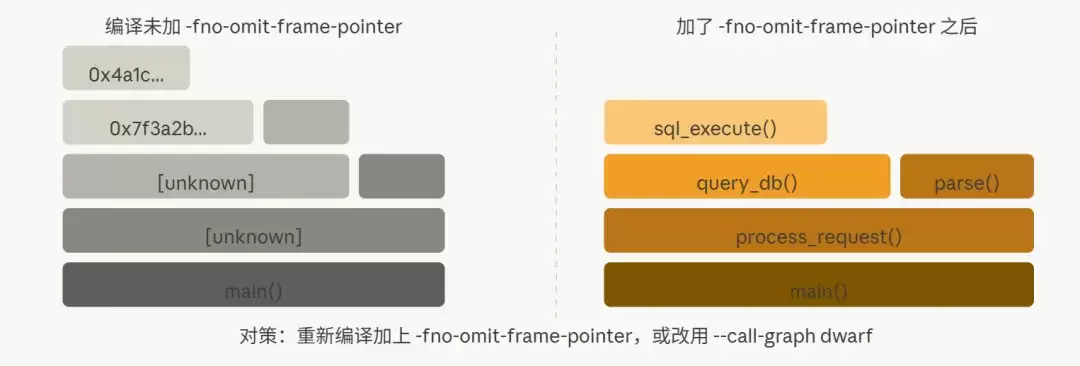
修复方法:
# 方法一:重新编译,保留帧指针
g++ -O2 -fno-omit-frame-pointer myapp.cpp -o myapp
# 方法二:不改编译选项,使用DWARF调试信息进行回溯(速度稍慢但准确)
perf record -F 99 -p 1234 --call-graph dwarf -- sleep 303. 情况三:大量时间在内核函数里——不是你的代码慢
火焰图中间出现大量如__memcpy、page_fault、futex_wait等内核函数,表明瓶颈不在应用层业务逻辑,而在系统层面。

几种常见内核热点的含义:
__memcpy_a vx很宽:程序在进行大量内存拷贝。考虑使用零拷贝技术或减少序列化/反序列化次数。do_page_fault很宽:缺页中断频繁,数据不在物理内存中,需要从磁盘换入。考虑使用大页(HugePage)、优化数据访问模式或增加内存。futex_wait很宽:线程大量时间在等待锁。考虑减小锁粒度、使用读写锁或无锁数据结构。
4. 情况四:火焰图又矮又平,没有明显热点
这种情况反而棘手。CPU时间分散在许多不同的函数中,没有突出的“热点”。这通常意味着程序并非计算瓶颈,而是大量时间在等待I/O、网络或外部资源,CPU本身处于空闲状态。
处理方式:此时perf可能无法直接给出答案。需要换用其他工具,如strace追踪系统调用,或使用perf record -e block:block_rq_issue专门分析I/O事件。
九、只想快速看 top 函数?perf report 更方便
如果不需要火焰图的直观展示,只想快速找出最耗CPU的几个函数,可以使用perf report。
sudo perf record -F 99 -p 1234 -g -- sleep 10
sudo perf report --stdio输出结果类似这样:
# Overhead Command Shared Object Symbol
# ........ ....... ................ ....................
45.23% myserver myserver [.] database::query
23.11% myserver libc.so.6 [.] malloc
12.05% myserver myserver [.] parse_json
8.34% myserver [kernel] [.] __memcpy_a vx_unalignedOverhead列就是CPU占用百分比。如上所示,database::query函数占用了45.23%的CPU时间,这无疑是首要的优化目标。
十、高频面试题精析
(1) Q:perf 和 gprof 有什么区别?
A:gprof需要在编译时添加-pg选项,对程序有侵入性,且无法分析已运行的程序。perf基于内核的性能监控单元(PMU),完全无侵入,可随时附加到任何运行中的进程,精度更高,非常适合生产环境使用。
(2) Q:perf 采样频率设 99 而不是 100,为什么?
A:这是为了避免与系统默认的100Hz定时器(CONFIG_HZ)发生共振。如果采样频率与系统定时器完全一致,采样点可能会系统性落在某些特定时刻(如定时器中断处理中),导致统计偏差。使用99Hz可以错开频率,使采样点更均匀地覆盖程序执行过程。
(3) Q:火焰图里看到大量[unknown],怎么处理?
A:两种可能。一是程序编译时省略了帧指针(-fomit-frame-pointer),解决方案是使用--call-graph dwarf参数,或重新编译加上-fno-omit-frame-pointer。二是分析的是JIT编译的代码(如Ja va、Node.js),需要配置运行时环境(如JVM的-XX:+PreserveFramePointer)来导出JIT符号表给perf。
(4) Q:为什么 perf 需要 root 权限?
A:默认情况下,perf需要读取/proc/kallsyms(内核符号表)并访问硬件性能计数器,这些操作需要特权。在生产环境中,可以通过调整内核参数来放宽限制:
# 允许非root用户使用大部分perf功能
echo 1 > /proc/sys/kernel/perf_event_paranoid十一、写在最后
回到最初的问题:CPU跑满却不知瓶颈何在。现在,答案已经清晰。
标准流程就是三步:perf record采样、perf script导出、flamegraph.pl生成火焰图。然后,在图中寻找最宽阔的色块,那就是性能瓶颈所在。
这个工具组合的原理并不神秘,本质就是通过高频采样来统计“CPU时间都花在了哪里”。相比需要插桩和重新编译的传统性能分析工具,perf的侵入性极低,堪称线上排查的利器。当然,使用时也需注意:采样本身会带来少量性能开销,建议控制采样时长;同时,为了获得清晰的函数名,编译时最好加上-fno-omit-frame-pointer选项。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

东软发布车载智能出行方案7.0与AI座舱平台
2026年北京国际车展于4月26日正式拉开帷幕。展会前夕,东软集团率先举办了智能汽车互联新品战略发布会,集中发布了其在智能汽车软件领域的一系列创新成果与战略布局。本次发布聚焦三大核心:全球车载智能出行解决方案OneCoreGo的重大版本迭代、全新AI座舱软件平台NAGIC AI的首次亮相,以及旗下子

比亚迪大唐预售首日订单破3万 D级旗舰SUV市场迎新标杆
24小时,3万台订单。比亚迪王朝网首款D级旗舰SUV“大唐”的预售成绩单,一公布就引发了市场热议。这个数字不仅刷新了品牌自身的预售纪录,更向整个高端新能源SUV市场投下了一枚重磅冲击波。 这款备受瞩目的新车,此前已披露了诸多硬核信息。作为王朝网的旗舰之作,大唐EV集成了比亚迪当前多项尖端技术,包括第

中国工业机器人出口激增 移动机器人海外市场加速拓展
近期,海关总署发布的一组数据在行业内引发热议。统计显示,今年我国工业机器人出口增长势头强劲,其中4月份单月出口量首次突破2 5万台,同比增长接近90%。在这轮出海热潮中,移动机器人(AGV AMR)的表现格外突出,已成为彰显“中国智造”实力的重要名片。 这一出口增长态势的背后,反映了全球市场需求的差

尚界Z7T顶棚问题引热议 博主现场拆解视频动机成焦点
2025年北京国际车展现场,一段关于尚界Z7内饰体验的短视频在各大社交平台引发热议。然而,这次传播的焦点并非产品亮点,而是一种极具争议的交互演示方式,迅速成为公众讨论与行业反思的焦点。 视频画面显示,某平台体验人员在拍摄过程中,用手部施加较大力量扒开了尚界Z7顶棚内饰的边缘接缝处。这一片段经网络快速

地平线推出全新智能驾驶底座方案车企会买单吗
地平线创始人余凯 在今年的北京车展上,地平线向业界传递了一个清晰的战略信号:它已不再满足于仅仅扮演产业链中的“部件供应商”角色。 这家以智能驾驶芯片著称的科技公司,集中发布了中国首款舱驾融合整车智能体芯片“星空”、整车智能体操作系统KaKaClaw咖咖虾,以及全场景辅助驾驶系统HSD V1 6。这一








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
