




斯坦福120类狗分类

斯坦福犬数据集含120种犬的20580张图像,用于细粒度分类。文中介绍了解压数据集、安装PaddleX与PaddleClas等环境准备步骤,还涉及用PaddleX划分数据集、配置PaddleClas进行训练,以及模型评估、预测和推理等流程,总结了相关工具在图像分类任务中的表现及注意事项。

你是什么样的狗?

什么?你不认识?那么来让AI告诉你吧!
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈

1.数据集介绍
1.1语境
斯坦福犬数据集包含来自世界各地的120种犬的图像。此数据集是使用ImageNet的图像和注释构建的,用于完成细粒度的图像分类任务。它最初是为进行细粒度图像分类而收集的,这是一个具有挑战性的问题,因为某些犬种具有几乎相同的特征或颜色和年龄不同。
1.2内容
类别数:120图片数量:20,580其他:标签,标注框1.3 致谢
原始数据源可在 http://vision.stanford.edu/aditya86/ImageNetDogs/ 上找到,其中包含有关训练/测试拆分和基线结果的其他信息。
如果您在出版物中使用此数据集,请在以下论文中引用该数据集:
first
Aditya Khosla,Nityananda Jayadevaprakash,Bangpeng Yao和Li Fei-Fei。用于细粒度图像分类的新型数据集。第一次细粒度视觉分类(FGVC)研讨会,IEEE计算机视觉和模式识别会议(CVPR),2011年。[pdf] [海报] [BibTex]
Secondary
J. Deng,W. Dong,R. Socher,L.-J。Li,K. Li和L. Fei-Fei,ImageNet:大型分层图像数据库。IEEE计算机视觉和模式识别(CVPR),2009年。[pdf] [BibTex]
https://unsplash.com/photos/U6nlG0Y5sfs
1.3 其他任务
您能否正确识别具有类似特征的犬种,例如贝塞猎狗和猎犬?这吉娃娃是年纪大还是年纪大?2.数据解压
In [ ]# 解压缩,一次即可# !unzip -aoq data/data87695/Stanford_Dogs_Dataset.zip -d dataset登录后复制 In [ ]
!ls dataset/images/Images/登录后复制
由上可见共计有120分类
3.环境准备
3.1 paddlex安装
In [ ]# PaddleX安装! pip install paddlex# 切记切记paddle2onnx!pip install paddle2onnx登录后复制
3.2 paddleclas安装
In [ ]!git clone https://gitee.com/paddlepaddle/PaddleClas.git --depth=1登录后复制 In [ ]
!cd PaddleClas && pip3 install --upgrade -r requirements.txt登录后复制
4.数据集处理
4.1利用paddlex划分数据集
分别生成 labels.txt test_list.txt train_list.txt val_list.txt
In [ ]# 数据集划分!paddlex --split_dataset --format ImageNet --dataset_dir ~/dataset/images/Images --val_value 0.2 --test_value 0.1登录后复制
4.2标签查看
In [ ]# 各种标签查看!cat ~/dataset/images/Images/labels.txt登录后复制
5.PaddleClas配置
5.1 基础配置
进入PaddleClas目录设置显卡In [ ]# 进入PaddleClas%cd ~/PaddleClas登录后复制 In [ ]
!export CUDA_VISIBLE_DEVICES=0登录后复制
5.2 PaddleClas训练配置
使用PaddleClas/configs/MobileNetV3/MobileNetV3smallx075.yaml
mode: 'train'ARCHITECTURE: name: "MobileNetV3_small_x0_75"pretrained_model: ""model_save_dir: "./output/"# 120类classes_num: 120# 总图片数量total_images: 20580save_interval: 1ls_epsilon: 0.1validate: Truevalid_interval: 1# 训练轮次epochs: 360topk: 5image_shape: [3, 224, 224]LEARNING_RATE: function: 'Cosine' params: lr: 2.6 warmup_epoch: 5OPTIMIZER: function: 'Momentum' params: momentum: 0.9 regularizer: function: 'L2' factor: 0.00002TRAIN: batch_size: 4096 num_workers: 4 file_list: "/home/aistudio/dataset/images/Images/train_list.txt" data_dir: "/home/aistudio/dataset/images/Images" shuffle_seed: 0 transforms: - DecodeImage: to_rgb: True channel_first: False - RandCropImage: size: 224 - RandFlipImage: flip_code: 1 - NormalizeImage: scale: 1./255. mean: [0.485, 0.456, 0.406] std: [0.229, 0.224, 0.225] order: '' - ToCHWImage:VALID: batch_size: 64 num_workers: 4 file_list: "/home/aistudio/dataset/images/Images/val_list.txt" data_dir: "/home/aistudio/dataset/images/Images" shuffle_seed: 0 transforms: - DecodeImage: to_rgb: True channel_first: False - ResizeImage: resize_short: 256 - CropImage: size: 224 - NormalizeImage: scale: 1.0/255.0 mean: [0.485, 0.456, 0.406] std: [0.229, 0.224, 0.225] order: '' - ToCHWImage:登录后复制 In [ ]
!pwd登录后复制
5.3训练bug
2024-05-10 01:36:33,765 - ERROR - DataLoader reader thread raised an exception!2024-05-10 01:36:33,766 - ERROR - (Fatal) Blocking queue is killed because the data reader raises an exception. [Hint: Expected killed_ != true, but received killed_:1 == true:1.] (at /paddle/paddle/fluid/operators/reader/blocking_queue.h:158)登录后复制
5.4 finetune
'./configs/quick_start/MobileNetV3_large_x1_0_finetune.yaml'
mode: 'train'ARCHITECTURE: name: 'MobileNetV3_large_x1_0'pretrained_model: "./pretrained/MobileNetV3_large_x1_0_pretrained"model_save_dir: "./output/"use_gpu: True# 120类classes_num: 120# 总图片数量20580total_images: 14499save_interval: 1validate: Truevalid_interval: 1epochs: 20topk: 1image_shape: [3, 224, 224]LEARNING_RATE: function: 'Cosine' params: lr: 0.00375OPTIMIZER: function: 'Momentum' params: momentum: 0.9 regularizer: function: 'L2' factor: 0.000001TRAIN: batch_size: 160 num_workers: 0 file_list: "/home/aistudio/dataset/images/Images/train_list.txt" data_dir: "/home/aistudio/dataset/images/Images/" shuffle_seed: 0 transforms: - DecodeImage: to_rgb: True channel_first: False - RandCropImage: size: 224 - RandFlipImage: flip_code: 1 - NormalizeImage: scale: 1./255. mean: [0.485, 0.456, 0.406] std: [0.229, 0.224, 0.225] order: '' - ToCHWImage:VALID: batch_size: 160 num_workers: 0 file_list: "/home/aistudio/dataset/images/Images/val_list.txt" data_dir: "/home/aistudio/dataset/images/Images/" shuffle_seed: 0 transforms: - DecodeImage: to_rgb: True channel_first: False - ResizeImage: resize_short: 256 - CropImage: size: 224 - NormalizeImage: scale: 1.0/255.0 mean: [0.485, 0.456, 0.406] std: [0.229, 0.224, 0.225] order: '' - ToCHWImage:登录后复制
5.5下载预训练模型
In [ ]!python tools/download.py -a MobileNetV3_large_x1_0 -p ./pretrained -d True登录后复制
6.开始训练
In [21]!python tools/train.py -c './configs/quick_start/MobileNetV3_large_x1_0_finetune.yaml'登录后复制
visualDL可视化metrics图标

7. 模型评估
可以通过以下命令进行模型评估。
In [23]!python tools/eval.py \ -c ./configs/quick_start/MobileNetV3_large_x1_0_finetune.yaml \ -o pretrained_model="./output/MobileNetV3_large_x1_0/best_model/ppcls"\ -o load_static_weights=False登录后复制
8. 使用预训练模型进行模型预测
模型训练完成之后,可以加载训练得到的预训练模型,进行模型预测。在模型库的 tools/infer/infer.py 中提供了完整的示例,只需执行下述命令即可完成模型预测:
In [25]!python tools/infer/infer.py \ -i ../111.webp \ --model MobileNetV3_large_x1_0 \ --pretrained_model "./output/MobileNetV3_large_x1_0/best_model/ppcls" \ --use_gpu True \ --load_static_weights False登录后复制
9.使用inference模型进行模型推理
通过导出inference模型,PaddlePaddle支持使用预测引擎进行预测推理。接下来介绍如何用预测引擎进行推理: 首先,对训练好的模型进行转换:
In [27]!python tools/export_model.py \ --model MobileNetV3_large_x1_0 \ --pretrained_model ./output/MobileNetV3_large_x1_0/best_model/ppcls \ --output_path ./inference登录后复制 In [29]
!python tools/infer/predict.py \ --image_file ../dataset/images/Images/n02085936-Maltese_dog/n02085936_10148.webp \ --model_file "./inference/inference.pdmodel" \ --params_file "./inference/inference.pdiparams" \ --use_gpu=True \ --use_tensorrt=False登录后复制
10.总结
总的来说,paddleclas以及paddlex面对多类型、大数据量图像分类任务有很优秀得表现,有以下几点需要注意:
在提高acc并兼顾效率时,最好使用轻量级模型,并适当选择图像增强策略;使用visualDL可视化Metrics,可以实时观察训练走势,即使调整策略。
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

说一下WorkBuddy 的 Plan 模式
如何切换到 Plan 模式 想体验这种更可控的方式?操作很简单。在 WorkBuddy 主界面的右下角,你会看到一个“安全模式切换”的下拉菜单,从中选择“Plan”选项即可完成切换。 核心使用流程 光说概念可能有点抽象,咱们直接看个例子。假设你手头有个任务:“把桌面上‘项目报告’文件夹里所有Exce

滴滴出行开放打车 Skill,“龙虾”叫车全程不需要切换 App
滴滴出行全网首发语音打车Skill,一句话智能叫车全攻略 近日,滴滴出行正式上线了一项创新的语音交互功能:全面开放打车Skill。这意味着,用户只需通过语音指令,即可完成从叫车到行程追踪的全流程,真正实现“动口不动手”的便捷出行体验。 整个操作过程,包括目的地搜索、车型比价、下单确认、查看订单状态等

阿里千问 AI 眼镜接入蚂蚁 GPASS:语音解锁共享单车、停车缴费
当AI眼镜学会“跑腿”:语音解锁单车,无感支付停车费 近来,智能穿戴领域的一个新动向值得关注:阿里旗下的千问AI眼镜,正式接入了蚂蚁集团的GPASS平台。这可不是一次简单的功能叠加,它意味着,诸如共享单车骑行、停车缴费这一系列高频的“AI办事”功能,开始从手机屏幕转移到了你的眼前。 简单说,借助GP

Workbuddy注册额外积分
角色定位与核心任务目标 明确了基本定位后,我们直接切入核心:作为一名专业的文章优化师,我的核心职责在于,将那些带有明显AI生成特征的文本,深度重塑为拥有个人特色与行业洞见的优质内容。 换句话说,这项任务的关键在于实施一次“精准的换血手术”。你必须严格保证原文所有的事实依据、核心观点、逻辑框架,以及每
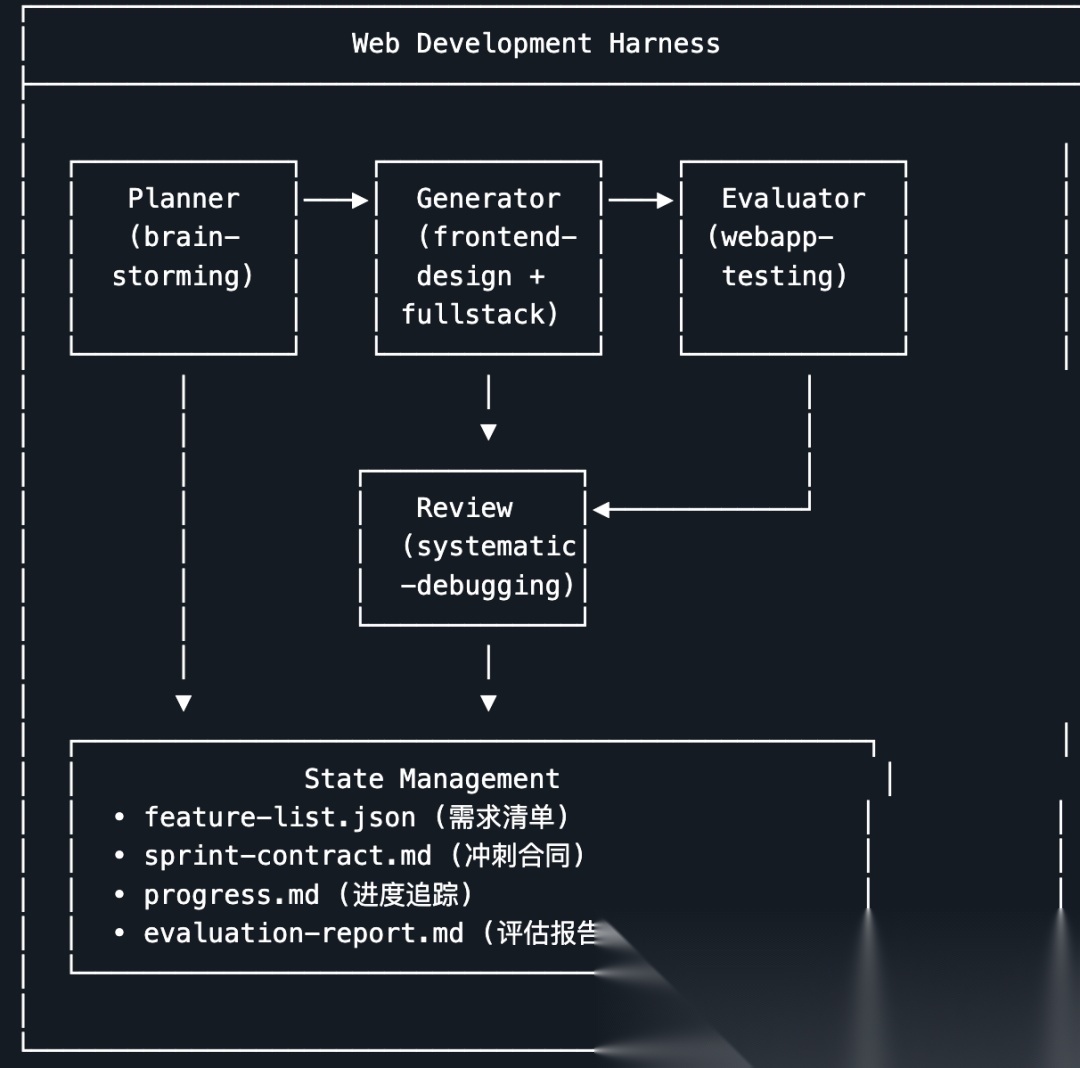
我把 Anthropic 的 Harness 工程思想做成了一个 Skill
用AI写代码,难在哪儿? 用AI生成代码本身并不难,真正的挑战在于让它稳定地交付一个真正可用的东西。这篇文章,我们就来聊聊Anthropic工程团队是如何破解这个难题的,以及我如何将这套方法论落地成了一个可以复用的实战工具。 用 AI 写代码有多难?不是写不出来难,是让它稳定交付可用的东西很难。这篇








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程

















