




国产GPU进化!打造先进好用的“AI训练工厂”

我们正站在AI狂飙的黄金时代——短短半年,全球顶尖模型“智力”飙升50%;2025年几乎每周都有重磅模型登场;从大语言模型到多模态架构,七类模型架构全速迭代。
当传统“暴力堆卡”的训练模式,越来越难以满足指数级增长的智能生产需求。AI产业亟需要一场“效率革命”,即构建新一代大型人工智能计算基础设施,以应对生成式AI进化。
国内GPU厂商摩尔线程在WAIC 2025前夕出招了,要用国产全功能GPU打造一个AI“超级工厂”,直击大模型训练效率的瓶颈。

这座AI工厂的“产能”,有一道硬核公式来衡量:
AI工厂生产效率 = 加速计算通用性 x 单芯片有效算力 × 单节点效率 × 集群效率 × 集群稳定性
摩尔线程的杀手锏“全功能GPU”,就是这座“AI工厂”的心脏。
根据功能结构划分,GPU可分为图形GPU、GPGPU(通用计算GPU)与全功能GPU。既然是全功能GPU,你可以理解为,既能做图形,也能做AI,还可以做通用计算、科学计算等。全球范围内,也仅有NVIDIA掌握的尖端技术。而摩尔线程是国内唯一从功能上可以对标英伟达的国产全功能GPU企业。
自2020年成立以来,摩尔线程一直致力于全功能GPU的研发与创新。全功能GPU具备更强的通用性,不仅可以服务数据中心,也具备下沉至消费端的潜力,是真正的全能型选手。
截至目前,摩尔线程已完成了四代全功能GPU的迭代,其中包括支持FP8精度的最新智算卡MTT S5000、训推一体全功能智算卡MTT S4000、支持千卡互联的第一代超大规模智算融合中心产品KUAE1,以及第二代万卡集群KUAE2,这些产品已实际交付多个智算中心。

那么,摩尔线程如何打造世界先进的AI工厂?
这是一项系统级创新工程,主要体现在五个关键方面:加速计算通用性、单芯片有效算力、单节点效率、集群效率和集群稳定性,这些因素环环相扣缺一不可。

在加速计算通用性方面,摩尔线程自主研发的多引擎全功能GPU,率先实现在单芯片架构,同时支持AI计算加速、图形渲染、物理仿真和科学计算、超高清视频编解码,并覆盖从FP8到FP64的全计算精度。



不同精度的计算适用于不同的应用场景,例如FP8用于混合精度训练和大语言模型推理,INT8用于量化推理和CV推理,BF16/FP16用于机器学习和大语言模型训练,FP32/TF32用于3D渲染、游戏和高精度推理训练等,而FP64则主要用于科学计算,如天气预报和气候仿真等。

摩尔线程的全功能GPU能够支持以上全部精度的训练推理,从而实现AI训练推理、科学计算、工业智能、自动驾驶、具身智能、生物制药、AIGC、AI智能体、游戏等全场景AI加速。
有了应用场景,性能跟不上那也是白搭,摩尔线程自研的MUSA架构从底层基础设施到中间层管理平台,再到上层应用,实现了全面覆盖,通过计算、通信、存储技术创新,有效提升了单芯片有效算力。


MUSA架构,是创新的多引擎、可伸缩GPU架构,通过硬件资源池化及动态资源调度技术,构建了全局共享的计算、内存与通讯资源池。这一设计不仅突破了传统GPU功能单一的限制,还在保障通用性的同时显著提升了资源利用率。
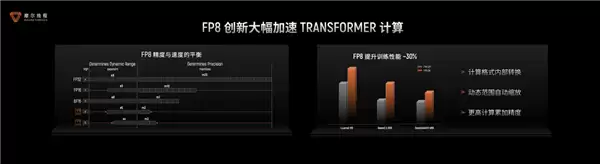
在计算层面,摩尔线程的AI加速系统(TCE/TME)全面支持INT8/FP8/FP16/BF16/TF32等多种混合精度计算。作为国内首批实现FP8算力量产的GPU厂商,其FP8技术通过快速格式转换、动态范围智能适配和高精度累加器等创新设计,在保证计算精度的同时,将Transformer计算性能提升约30%。

此外,DeepSeek曾在技术报告中提到,在通信过程中约15%的流式多处理器被占用,也就是差不多15%的算力没有用到训练中,而是被用于通信。
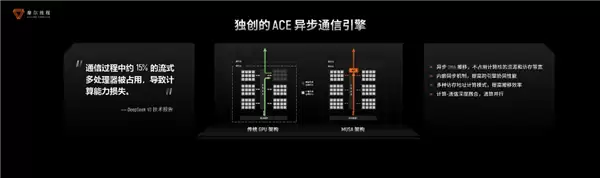
摩尔线程是如何解决这个问题的呢,基于自研的MTLINK 2.0实现的集合通信库,实现卡间高速互联,高出国内行业平均水平60%的带宽;同时基于MTT S5000的异步通信引擎,从而实现高效计算与通信并行,减少了15%的计算资源损耗,为大规模集群部署奠定了坚实基础。

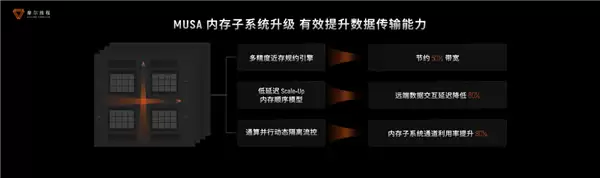
内存系统方面,通过多精度近存规约引擎、低延迟Scale-Up、通算并行资源隔离等技术,实现了50%的带宽节省和60%的延迟降低。
有了单芯片的算力,还需要实现单节点的高效率,摩尔线程的MUSA全栈系统软件,通过高效的基础软件库,框架算法创新和完备的开发工具链提升了单节点计算效率。

在GPU驱动任务调度优化方面,摩尔线程的核函数启动时间仅为业界平均耗时的1/2,核函数启动是指计算任务从CPU主机传输到GPU设备并执行的过程,传统方法中,较高的启动延迟会导致算力资源浪费。而摩尔线程则支持千次计算指令并行下发,从而大幅减少GPU等待时间。



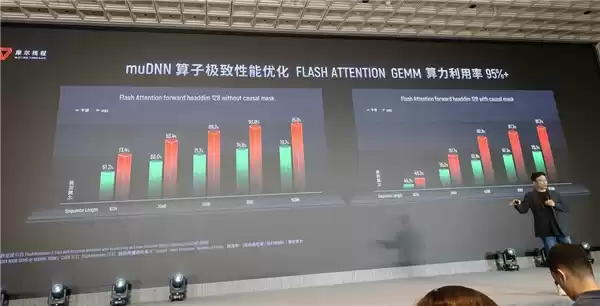
摩尔线程还对核心算子库进行了极致优化,比如GEMM算子算力利用率达98%,Flash Attention 算子算力利用率突破95%。
在通信效率上,MCCL通信库实现RDMA网络97%带宽利用率;基于异步通信引擎优化计算通信并行,集群性能提升10%。
在开发生态兼容上,基于Triton-MUSA编译器 + MUSA Graph实现DeepSeek R1推理加速1.5倍,全面兼容Triton等主流框架。
此外,摩尔线程还提供了完整的开发者工具套件,如深度监控GPU并收集硬件性能数据的Torch Profiler,以及可以一键部署MUSA软件栈和AI服务程序的MUSA Deploy等。


正是这种软硬协同与系统优化,实现了极致性能和效率,从平湖和国际主流GPU产品的实测对比数据中,我们可以直观地看到摩尔线程产品的优势。
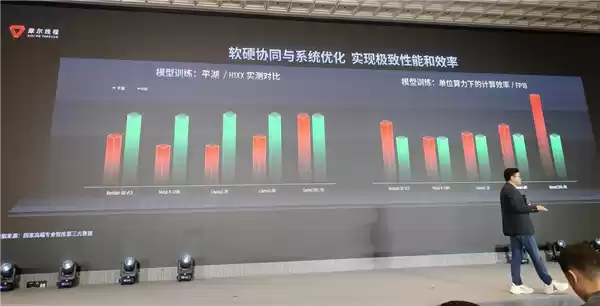
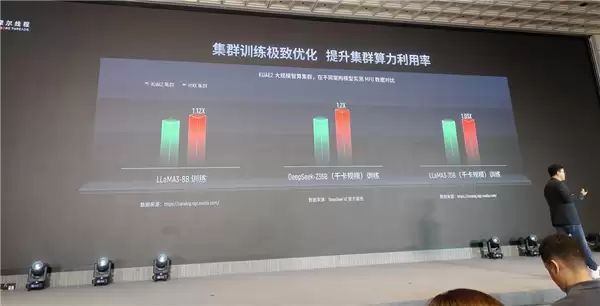
在集群方面,如前文所述,摩尔线程拥有支持千卡互联的KUAE1和支持万卡互联的第二代方案KUAE2,并实现了模型种类全支持,无论何种类型的模型都能适用,这也是真正满足AI工厂使用和实现的地方。




根据官方分享的数据,KUAE2在不同架构模型的实测MFU数据对比中,性能和效率均处于行业领先水平。
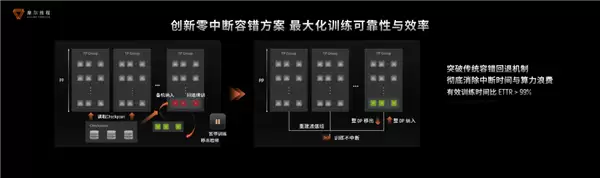
最后也是最重要的一点,那就是稳定性,集群不稳定的话,再高的性能再快的效率也没有任何意义,为此摩尔线程推出了零中断容错技术,故障发生时仅隔离受影响节点组,其余节点继续训练,备机无缝接入,全程无中断,这也使得KUAE集群有效训练时间占比超99%。

针对集群中的慢节点,摩尔线程开发了一套多维度Training Insight,将异常处理效率提升了50%,结合集群巡检与起飞检查,训练成功率及速度提高了10%。

综合来看,摩尔线程的高效AI工厂结合了全功能GPU、MUSA架构、MUSA软件栈、KUAE集群和零中断技术,为AI大模型训练提供了强大可靠的基础设施支持,而且只有这样的组合,才能确保每一个环节都达到最佳状态。

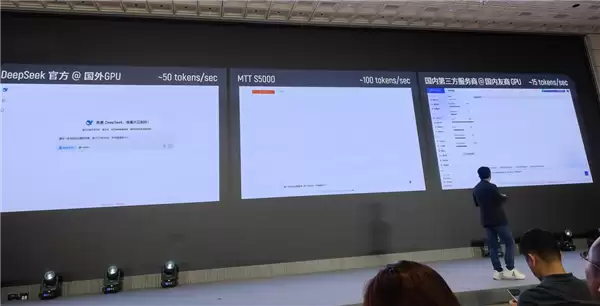
大模型训练完成后,还需要进行推理验证,摩尔线程的推理解决方案基于MT Transformer自研推理引擎、TensorX自研推理引擎和vLLM-MUSA推理框架,为模型验证和部署提供极致性能支持。


通过实测,MTT S5000树立了DeepSeek全量模型推理速度的新标杆:跑满血DeepSeek R1推理模型,速度达到100 tokens/s。
GPU可以说是AI时代最稀缺的资源之一,也是大国科技竞争的焦点,其重要性不言而喻。我们深知硬科技研发的艰难,但摩尔线程还是选择了通用性最强、难度最高的全功能GPU路线。
从全功能GPU的研发,到“AI工厂”概念的提出与实践,摩尔线程这条道路虽然充满挑战,但它无疑是能够走得最长远的路径。未来,我们期待摩尔线程能够持续突破技术瓶颈,以更强大的算力、更高效的架构、更稳定的性能,为国产AI的发展注入强劲动力。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

三星T9移动固态硬盘评测:专为户外摄影设计的存储解决方案
户外摄影的魅力,在于捕捉瞬息万变的自然光影与真实动人的创作瞬间。然而,这份创作激情背后,常常伴随着一系列令人头疼的存储挑战。无论是拍摄高码流的4K、8K超清视频,还是保留丰富细节的RAW格式照片,这些高质量素材文件体积庞大,相机存储卡空间频频告急成为常态。同时,存储卡本身的读写速度在备份大量素材时往

EPOMAKER RT100 Pro三模机械键盘国行版开售 首发价649元起
4月24日,EPOMAKER旗下的RT100 Pro三模机械键盘正式在国内市场开售。国行649元的起售价颇具看点,相比其海外官网约800元软妹币的定价,显然为国内玩家提供了更直接的吸引力。这款键盘凭借其鲜明的复古设计语言、可玩性极高的模块化交互,以及客制化级别的内部结构,一经亮相便迅速成为中高端个性

2026上海科技节盛大开幕:科技嘉年华等你来体验
2026年上海科技节于5月23日开幕,为期一周,覆盖全市16个区,计划举办近2000场活动。活动设置七大板块,涵盖专题会议、科普开放日、赛事及文旅体验等,旨在打造全民共享的科技嘉年华,让前沿科技与城市生活深度对话。通过多层次、可参与的场景设计,让市民直观感受科技如何塑造未来,推动科普从单向传。

Moka发布三款AI人力资源工具助力企业管理智能化
随着人才供需变化与AI岗位激增,HR面临更复杂的人才匹配挑战。Moka近期推出三款AI工具:招聘Eva优化全流程筛选与面试,人事Eva处理高频事务,BPEva提供组织洞察。这些工具旨在将HR从繁琐工作中解放,聚焦战略与人才管理。AI的应用有望推动评价体系更客观,并重塑组织协作方式,但转型需克服固有工作惯性。

2026年618惠普星Book Pro轻薄本选购指南与推荐
对于在校大学生而言,选择一台称心如意的笔记本电脑,需要综合考虑预算、性能、便携性与续航等多重因素。进入2026年,兼具高性价比、轻薄机身、长时续航与丰富接口的轻薄本,已成为校园学习与生活的主流装备。它不仅能流畅完成论文撰写、PPT制作、在线课程等日常学业任务,也能胜任轻度的平面设计、视频剪辑或编程开








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
