




MetaAI新突破:Transformer潜藏意识仅3%算力实现55%性能跃升

这项研究给予我们一个深刻的启示:即便Transformer架构在今天已经相当成熟,我们只需对其核心的自回归机制进行微小却精准的改进,依旧能够带来令人意想不到的性能飞跃。
来自Meta FAIR部门的研究员François Fleuret发布了一篇题为《The Free Transformer》的论文,提出了一种对现有解码器Transformer模型的巧妙扩展。

这项创新技术的精髓在于,它让模型在生成每个词汇之前,能够在内部形成一个类似计划草案的潜在决策,而不再像传统方式那样边写边想。
实验数据证实,这种先规划后执行的模式,在编程、数学和推理等各类任务中都带来了显著的性能提升。
AI写作的模式局限
我们现在所熟知的解码器Transformer,例如GPT系列模型,在生成文本时采用逐词递进的方式。它预测下一个词汇时,完全依赖于已经生成的所有前文内容。
假设我们要训练一个模型来撰写影评,而评论又分为正面和负面两类。
一个标准的解码器Transformer自然能够学会书写这两种评论。但它的工作机制是逐字逐句地输出文本——模型可能在写了几句话之后,根据已经表达的关于这部电影的观点,来判断接下来应该继续赞美还是转为批评。
它并没有一个全局性的、事先确定的决策机制:比如我现在要写一篇负面评论。这种正面或负面的概念,实际上是随着文字生成过程,隐含在概率计算中的后续推断。
这种方式存在几个潜在的问题。
它需要模型具备极大的容量和复杂的计算能力,才能从已生成的零散词汇中,反推出一个整体的意图,这种操作效率非常低下。
如果在生成过程的早期,出现了几个存在偏差、模棱两可或者前后矛盾的用词,整个生成过程就可能偏离方向,后续内容也难以调整回来。
关键的概念,比如正面或负面,并非由模型主动构建,而是在拟合训练数据时被动形成的。这使得模型在面对分布以外的数据时,可能表现得相当脆弱。
Free Transformer为模型赋予自主规划能力
Free Transformer的核心思路是,在模型的自回归生成过程中,引入一些额外的、不受训练样本直接控制的随机变量,让模型能够依据这些变量来动态调整文本的生成。
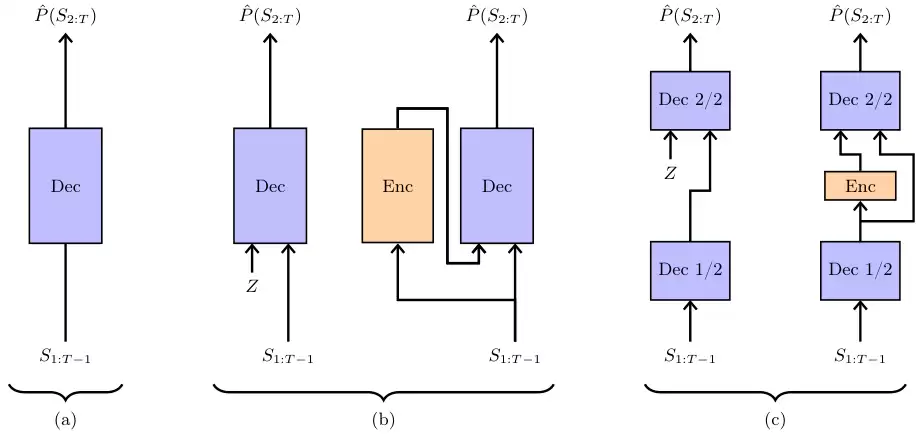
回到电影评论的例子。模型可以首先使用一个内部的随机布尔值,一次性确定接下来要生成的是正面评价还是负面评价。
有了这个全局性的决策机制,模型就不再需要从已经生成的零散词句中费力地推断意图。
实现这个想法,需要借助一种名为变分自编码器(Variational Autoencoder,简称VAE)的框架。
在生成新内容时,操作流程相当简洁:模型先采样一个随机变量Z,然后像普通的Transformer一样,基于这个Z来生成整个序列。
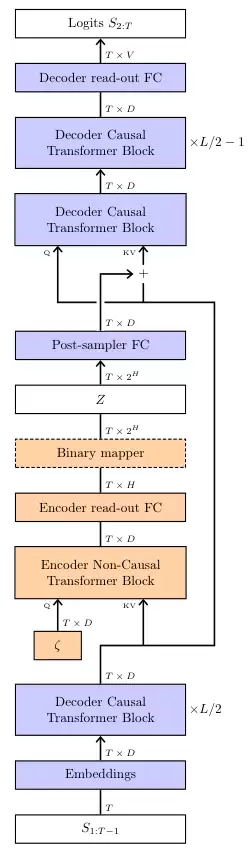
真正的挑战在于训练过程。我们希望模型学会将有意义的信息(例如评论的情感倾向)编码到潜变量Z中。
这就需要一个编码器。在训练时,编码器会读取一个完整的训练样本(比如一篇已有的正面评论),然后生成一个与之匹配的Z。解码器再借助这个Z,尝试去重构原始的评论。
通过联合优化编码器和解码器,模型就学会了如何将序列的全局属性(情感、主题等)压缩进Z,并利用Z来指导生成过程。
这里存在一个关键点:必须限制从编码器流向Z的信息量。否则,编码器可能会耍小聪明,直接把整个原文复制到Z中,解码器就可以轻松完成重构。这在训练时看起来表现完美,但在实际生成时,没有了编码器,模型就束手无策了。
VAE理论通过计算Z的分布与一个标准先验分布之间的KL散度来控制信息量,并将其作为一个惩罚项加入到总的损失函数中。
Free Transformer的结构设计非常巧妙。它并非一个全新的模型,而是对标准解码器Transformer的微小改造。
它将随机噪声Z注入到模型的中间层。
更为精妙的是,编码器直接复用了模型的前半部分网络层,只额外增加了一个非因果关系的Transformer块和两个线性层。
非因果关系意味着这个模块可以同时看到整个输入序列,这对于捕捉全局信息至关重要。
这样的设计,对于一个28层的1.5B模型来说,额外开销大约是1/28,约等于3.6%。而对于一个32层的8B模型,开销约为1/32,即3.1%。
仅用约3%的计算开销,就能带来大幅性能提升,这几乎相当于享用了一顿免费的午餐。
实验结果验证其有效性
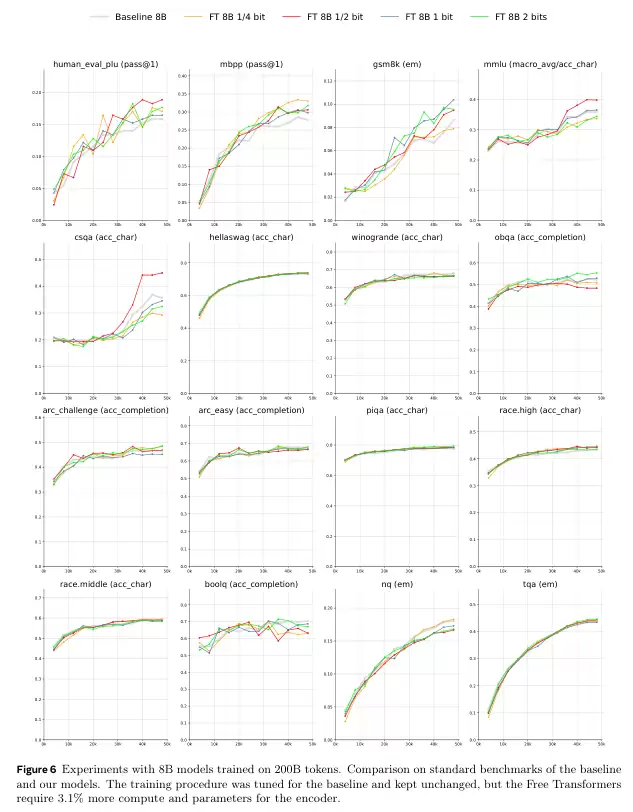
为了验证Free Transformer是否真正学会了利用潜变量Z,研究人员设计了一个精巧的合成数据集。
每个数据样本的生成规则如下:以64个下划线_开始。随机选择一个大写字母,在序列的随机位置,用8个该字母组成的目标替换掉下划线。以很小的概率,将任意字符替换为感叹号,作为噪声。在尾部附上一个提示,比如 a>,告知目标字母是什么。

研究人员用这个数据集训练了模型,并设置了不同的KL散度阈值(κ),这个阈值控制了模型可以向Z中注入多少信息量。

结果非常直观。当KL阈值很低时,模型几乎不使用Z,表现与普通Transformer无异(图左上)。所有生成的序列都各不相同。
当阈值稍微提高,模型开始将目标位置信息编码到Z中。在图右上的绿色框里,所有序列共享同一个Z,它们的目标都出现在了相同的位置。
当阈值进一步提高,模型不仅编码了位置,还编码了噪声(感叹号)的模式。图左下的绿色框里,不仅目标位置完全一样,连感叹号出现的位置都完全相同。
当阈值过高时,模型投机取巧,把整个序列的信息都塞进了Z,导致生成了错误的序列(图右下)。
这个实验清晰地证明,Free Transformer确实学会了根据任务需求,自主地将最关键的全剧信息(目标位置、噪声模式)封装到潜变量Z中。
接下来是基于真实世界的基准测试。研究人员使用了1.5B和8B两种规模的模型,与结构相同的标准解码器Transformer进行对比。
为了保证公平,所有超参数都沿用了基线模型的设定,没有为Free Transformer做特殊优化。
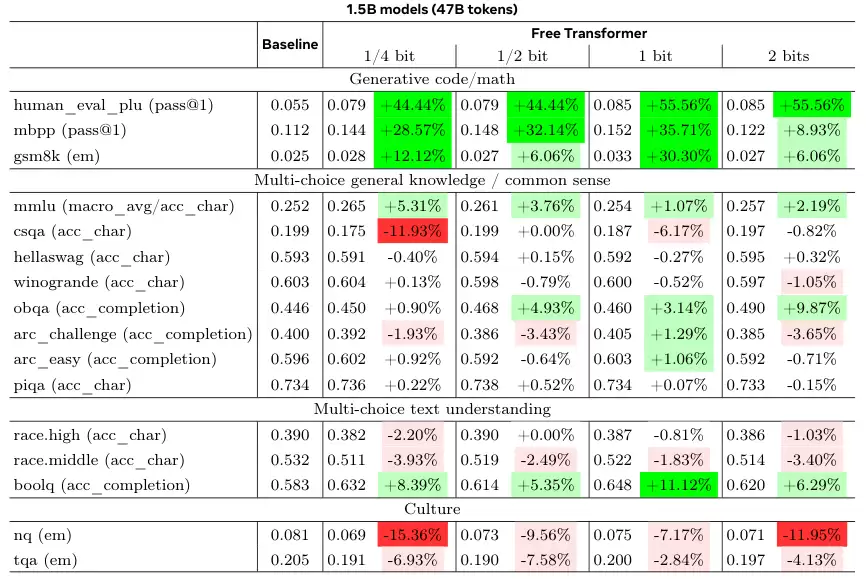
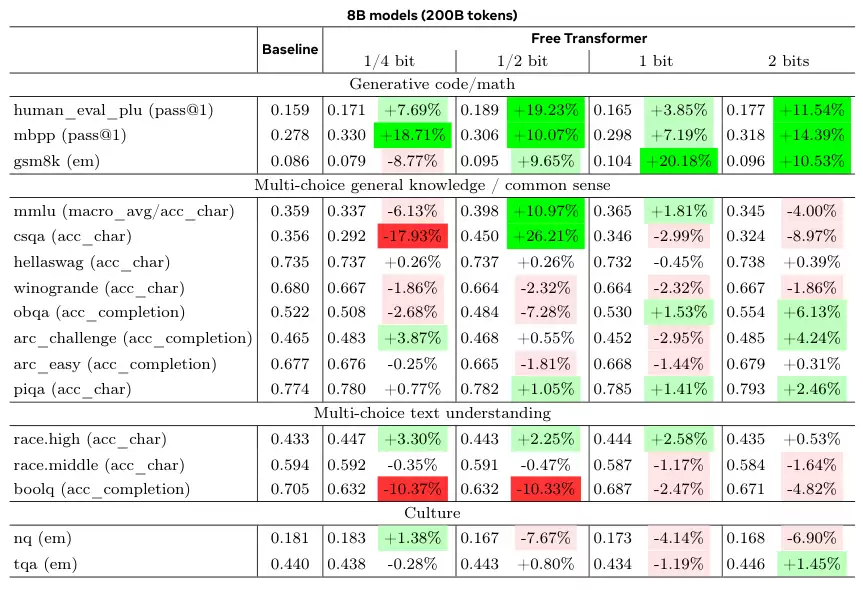
结果显示,在需要推理能力的基准任务上,如HumanEval+(代码生成)、MBPP(代码生成)和GSM8K(小学数学应用题),Free Transformer都取得了显著的性能提升。
在8B模型上,当允许每个token引入半比特信息时,性能提升最为明显。
为了验证这种改进在更大规模的训练下是否依然有效,研究团队使用1T(万亿)级别的token训练了8B模型。
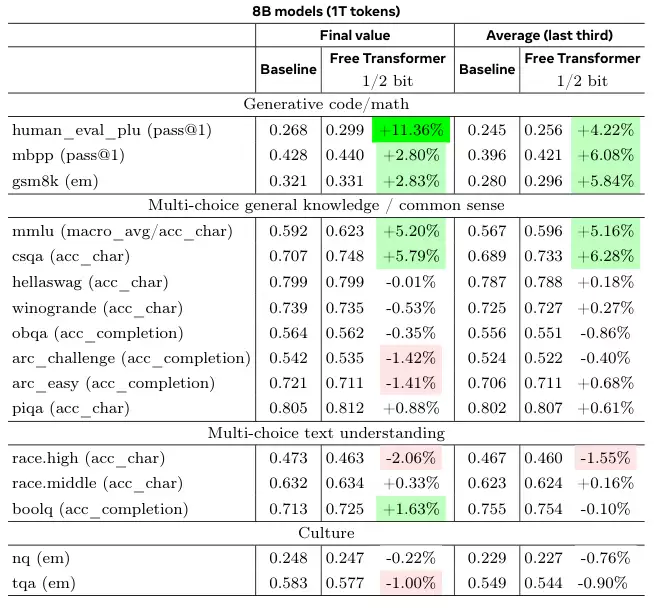
结果再次证实了之前的发现。无论是在训练结束时还是在训练后期的平均性能上,Free Transformer在推理、数学和多项选择问答任务中都稳定地优于基线模型。
这项工作的深远意义
Free Transformer以一种极为高效的方式,对标准解码器Transformer的内在偏好进行了改进。
它让模型有能力从训练数据中发现潜在的结构性信息,并利用这些结构来指导内容的生成过程。
在某种意义上,这与思维链或强化学习中的推理模型有异曲同工之妙。后者是在token层面,通过显式的文本来进行推理;而Free Transformer则是在模型的潜在空间中,通过自编码的方式进行一种更深层次的、隐性的规划。
将这两种方法结合起来探索,无疑是一个充满潜力的研究方向。
这项工作还仅仅是一个开端。研究人员指出,模型的训练过程有时不稳定,这可能是编码器和解码器优化过程耦合导致的,未来可以探索不同的优化策略。随机嵌入Z的形式也可以有多种选择。
它在更大规模的模型和数据集上的表现,仍有待进一步探索。
这项研究给予我们的启示是,即使在Transformer架构已经非常成熟的今天,对其核心的自回归机制进行微小却深刻的改造,依然能带来意料之外的性能突破。
AI不仅在学会如何表达,更在学会如何思考。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

AI赋能儿童故事创作:灵珠智能绘本文案生成指南
灵珠AI能帮助用户快速创作儿童故事与绘本,根据简单提示生成结构完整、逻辑连贯的初稿。平台提供绘本增强功能,自动提取画面描述以优化图文匹配,支持移动端碎片化编辑与多轮润色。完成后的作品可通过内置渠道一键发布,系统自动审核并适配格式,方便分发。

豆包如何提取图片文字OCR功能详解
豆包AI集成多语言OCR引擎,可识别印刷体、手写体及表格文字。用户可通过对话上传图片提取文字,或使用“图片理解”处理复杂场景。专用工具支持批量处理与多格式导出,AI绘图界面也内置识别功能。自然语言指令亦可触发OCR,多种方式满足不同需求,高效获取可编辑文本。

纳米AI语音输入使用教程:说话就能高效写作的详细指南
纳米AI语音输入提供多场景方案:手机APP可直接口述需求;网页版支持语音搜索与写作联动;拍照加语音模式可结合图像生成内容;通过Siri等设置快捷指令可实现全流程语音操控;本地部署方案利用开源助手离线保护隐私,仅上传文本至云端处理。

WorkBuddy与WPS AI办公文档处理能力对比评测
WPSAI深度集成于WPS客户端,对原生格式支持好,操作直接高效,响应快且安全。WorkBuddy依赖外部技能包,擅长执行跨文档、跨平台的复杂长指令与自动化流程,但步骤繁琐、权限风险较高。两者定位不同,前者侧重单文档轻便处理,后者侧重复杂工作流构建。

通义万象生成透明背景PNG图片的抠图与通道设置教程
生成透明背景PNG素材需先通过提示词生成白底图,再利用AI工具抠图并导出含Alpha通道的PNG文件。如需精修,可在Photoshop中通过通道优化选区,保存时勾选透明度。最后在OBS等应用中验证边缘融合效果,局部修改可使用支持Alpha通道的编辑模型保持透明。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
