




LLM能否替代数据科学家?DeepAnalyze告别低效数据分析

来自中国人民大学与清华大学的研究团队推出DeepAnalyze——你的专属"数据科学家"。只需一个简单指令,它就能帮你自动化分析各类数据集,并独立完成各类数据科学任务。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
你是否还在为繁杂的数据文件和海量信息而苦恼?是否希望能够自动从数据中挖掘出真正有价值的商业洞察?
最近,由人大与清华联合研发的DeepAnalyze——这款专为数据科学打造的智能助手,让你只需简单描述需求,它就能自主分析数据、完成建模、生成可视化报告等多项复杂任务:
支持自动化数据准备、数据分析、数据建模、数据可视化、数据洞察数据研究:可在非结构化数据、半结构化数据、结构化数据中进行开放式深度研究,生成研究报告

DeepAnalyze是全球首个面向数据科学的自主智能体,无需预设工作流程,仅凭单一语言模型即可像专业数据科学家那样,自主完成多种复杂的数据任务。
DeepAnalyze的论文、代码、模型、数据均已开源,已在GitHub收获1.1K+星标,欢迎大家亲身体验!
DeepAnalyze——你的专属"数据科学家"
DeepAnalyze能够在真实环境中自主编排和优化各类操作流程,从容应对复杂的数据科学挑战。
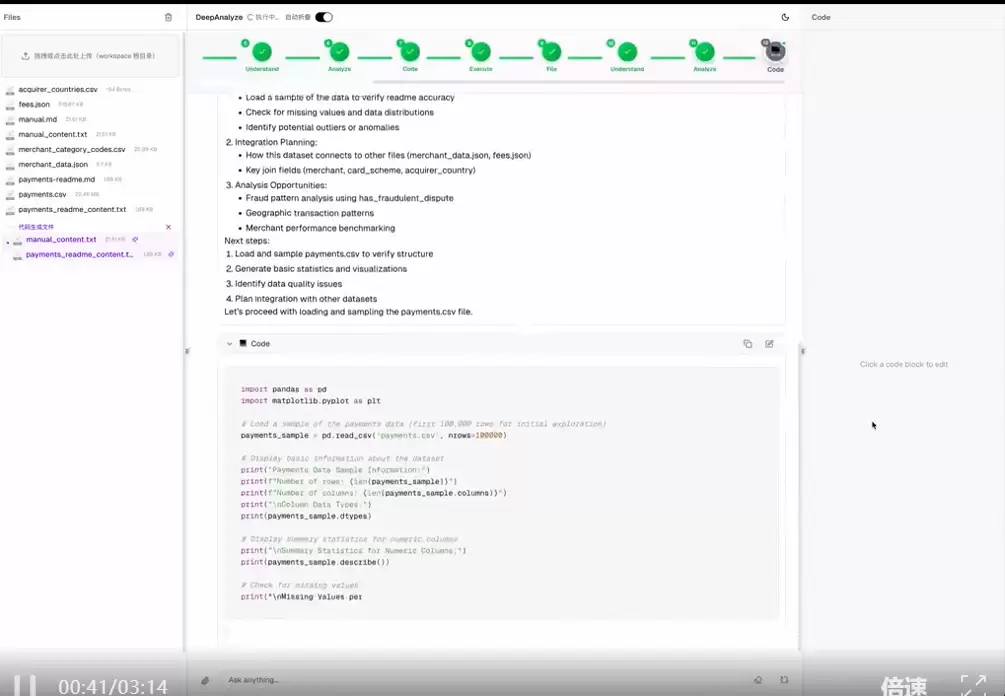
DeepAnalyze在真实环境中学习复杂任务
数据无处不在,而数据科学一直被视作人类智能的重要体现。从Kaggle竞赛到日常的数据分析实践,众多评测都在考察数据科学家在数据准备、分析、建模、可视化与洞察等方面的综合能力。
当前的数据智能体通常依赖人工设计的工作流程,来驱动大模型完成特定的数据分析与可视化任务。尽管在各类单点任务上已取得了令人瞩目的成果,但由于LLM的自主性仍然有限,它们距离理想的"全能自主数据科学家"依然存在明显差距。
随着大型语言模型智能水平的持续提升,一个关键问题也愈发突出:如何让LLM真正具备自主完成复杂数据科学任务的能力?
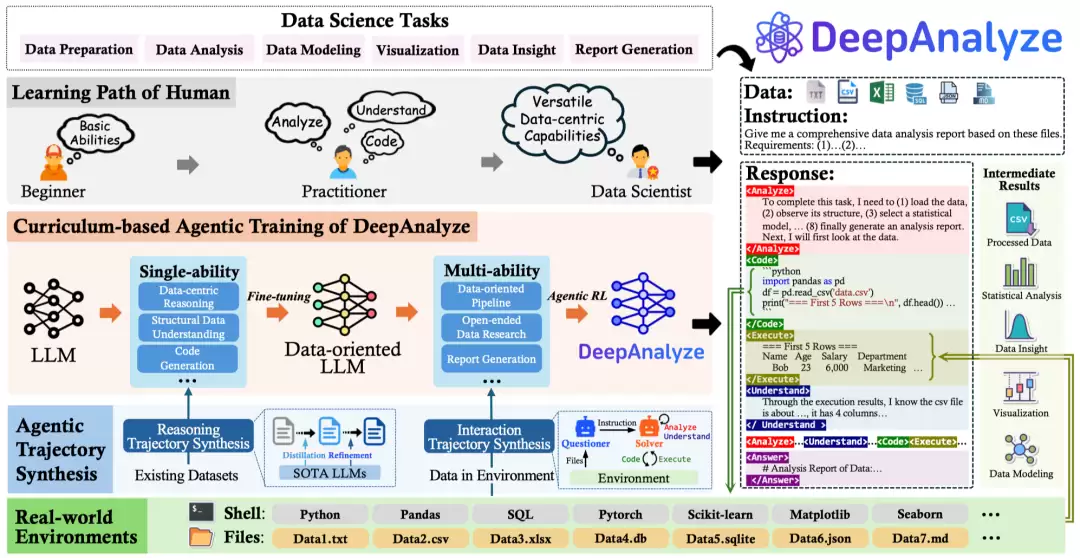
DeepAnalyze通过在真实环境中的训练,学会自主编排、自适应优化操作步骤,最终实现复杂数据科学任务的完整解决。
为达成这一目标,DeepAnalyze提出课程学习式自主训练范式(Curriculum-based Agentic Training ofDeepAnalyze)和面向数据的轨迹合成框架(Data-grounded Trajectory Synthesis)。
课程学习式Agentic训练
数据科学任务本身具有高度复杂性,这使得基础LLM在早期训练阶段往往难以顺利完成任务。任务复杂性导致模型几乎得不到正向奖励信号(即"奖励稀疏"问题),强化学习过程容易停滞,甚至出现训练崩溃的情况。
为了解决这一难题,DeepAnalyze提出了"课程学习式 Agentic 训练"。其模拟人类数据科学家的学习路径,让LLM在真实环境中从简单到复杂、从单一任务到综合任务逐步进阶。通过这种渐进式训练,模型的能力得以稳步提升,避免在复杂任务中因为"奖励信号为零"而导致学习失败。
训练过程包括两大阶段:
单能力微调:训练LLM在代码生成、结构化数据理解、逻辑推理等方面的基础能力;多能力Agentic训练:在真实任务环境中,让LLM学会运用多种能力,像数据科学家一样自主完成复杂任务。面向数据的轨迹合成
在数据科学领域,缺乏完整的长链问题求解轨迹,这让LLM在探索解题空间时缺乏有效指引,只能进行低效、盲目的"试错式"探索,难以获得有意义的中间监督信号。
为了解决这一难题,DeepAnalyze提出了"面向数据的轨迹合成"方法。其能够自动合成50万条数据科学推理与环境交互数据,为模型在庞大的搜索空间中提供正确路径的示范和引导。
数据合成包含两个关键部分:
推理轨迹合成:基于现有的TableQA、结构化知识理解、数据科学代码生成任务,构建带有完整推理路径的训练数据;交互轨迹合成:构建多智能体系统,从结构化数据源(如Spider和BIRD)中自动合成数据科学交互轨迹,提供真实环境的交互轨迹。DeepAnalyze支持面向数据的深度研究
DeepAnalyze支持面向数据的深度探索,能够自动生成具备专业分析师水准的研究报告。在数据研究报告生成任务中,无论是内容深度还是报告结构,DeepAnalyze的表现都显著优于现有的闭源LLM。
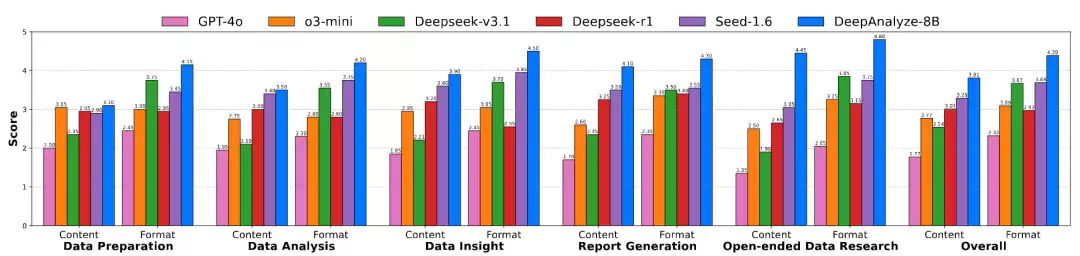
分析报告:

作者介绍

张绍磊,中国人民大学信息学院助理教授,隶属于中国人民大学讲席教授范举教授团队。
他博士毕业于中国科学院计算技术研究所,导师为冯洋研究员。他的研究方向涵盖大语言模型、多模态大模型、AI for Data Science。
相关研究成果在NeurIPS、ACL、ICLR等国际人工智能与自然语言处理会议发表论文30余篇,开源的多语言大模型、多模态大模型、数据科学大模型在GitHub社区累计获得5000+星标。
他长期担任CCF-A类国际会议ACL ARR的领域主席和责任编辑。个人主页:zhangshaolei1998@github.io。

范举,中国人民大学教授、博士生导师,国家级青年人才,中国计算机学会数据库专业委员会、大数据专业委员会委员。
研究方向包括:数据治理技术与系统、智能数据库系统等。
相关研究成果在计算机领域国际顶级期刊/会议发表论文60余篇。作为负责人先后主持国家自然科学基金优秀青年基金项目、重点项目、面上项目,以及多项产学研合作项目。
先后获得ICDE 2025 Best Paper Runner-Up、ACM SIGMOD Research Highlight Award、ACM China Rising Award、宝钢优秀教师等奖项。
团队介绍:
RUC-DataLab是中国人民大学信息学院、数据工程与知识工程教育部重点实验室设立的科研团队,负责人是范举教授,团队专注于数据系统+人工智能(Data+AI)交叉领域,致力于将数据技术与人工智能技术深度融合,从而打造更加智能、高效的新型数据系统。
实验室的研究方向包括:(1)数据库系统智能化(AI4DB):利用人工智能技术提升数据库系统的查询性能、自治能力等;(2)数据库技术赋能AI系统(DB4AI):利用数据管理技术支撑大模型训练的高效处理、大模型推理的低延迟、高吞吐优化;(3)数智融合的新型数据科学系统(AI4DS):利用推理大模型、多模态语义理解等技术,提升数据科学系统的智能化水平与执行性能,有效释放数据价值。
论文:https://arxiv.org/pdf/2510.16872
代码:https://github.com/ruc-datalab/DeepAnalyze
模型:https://huggingface.co/RUC-DataLab/DeepAnalyze-8B
数据:https://huggingface.co/datasets/RUC-DataLab/DataScience-Instruct-500K
更多示例:https://ruc-deepanalyze.github.io/

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Kyugo
Kyugo Calendar 是什么 市面上日历应用层出不穷,但大多脱不开线性列表或方格矩阵的老路子。这时候,Kyugo Calendar带着它那独特的圆形设计出现了,它想干的,可不只是帮你记个日程那么简单。 由Kyugo团队打造的这款工具,本质上是一个专注生产力的日历。它的野心在于改变我们看待和管

Cantrip.io
Cantrip io是什么 如果你一直在寻找一个能让网站搭建变得像“魔法”一样简单的工具,那么Cantrip io很可能就是答案。这款由专注用户体验和技术的团队开发的平台,其核心卖点非常明确:为用户,尤其是那些不想操心插件、设计或复杂后台设置的用户,提供一个真正“无痛”的建站体验。它巧妙地将AI内容

Blessing Wiki
Blessing Wiki是什么 在数字问候日渐同质化的今天,你是否想过,一条祝福也能真正“为你而生”?这就是Blessing Wiki想回答的问题。它并非出自大厂之手,而是一群由技术爱好者、创意作家和充满同理心的客服人员共同打造的工具。其核心理念很纯粹:将语言的优雅与人工智能的智能相结合,生成那些

Datascale
Datascale是什么 在数据团队日常工作中,面对成百上千的SQL脚本和错综复杂的数据关系,是种什么体验?想必不少数据库管理员和工程师都深有体会:混乱、耗时且极易出错。好在我们现在有了新的解题思路——Datascale。这是一款由Poom开发的创新型云SQL建模平台,它最厉害的地方在于,能够帮你彻

Ecomtent
Ecomtent AI是什么 当你在亚马逊、谷歌或eBay上浏览产品时,有没有想过,那些抓人眼球的图片和文案是怎么来的?背后很可能有AI的助力。Ecomtent AI正是这样一款工具,专为优化电商产品内容而生。它由Ecomtent公司开发,能自动生成高质量的图片、信息图表和文案,核心目标就一个:显著








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
