




视觉优化长文本:内存直降50%,token需求减半!

在即将举行的NeurIPS 2025学术会议上,来自南京理工大学、中南大学与南京林业大学的联合研究团队重磅推出了突破性框架VIST(视觉导向的大语言模型Token压缩技术),为大规模语言模型实现长文本高效推理开创了全新的“视觉解决方案”。值得注意的是,这一创新思路与近期备受瞩目的DeepSeek-OCR技术理念高度契合。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
处理短文本时,大语言模型展现出令人印象深刻的理解与生成能力。然而现实场景中的许多任务——包括长文档理解、复杂问答以及检索增强生成(RAG)系统等,都需要模型处理成千上万甚至数十万字符的上下文信息。
与此同时,模型参数规模也从数十亿一路飙升至万亿级别。
面对“上下文长度激增”与“模型参数量膨胀”的双重挑战,Token压缩已不再仅仅是优化选项,而是成为了必备功能。
若无法有效缩减输入规模,即便是最强大的语言模型,也难以高效处理我们需要它分析的海量信息。
南京理工大学、中南大学与南京林业大学的研究人员提出的VIST框架,正是为了解决这一痛点而生。

论文链接:https://arxiv.org/abs/2502.00791
研究团队早在一年多前的NeurIPS 2024就开始探索——如何让模型能够像人类那样,通过视觉方式更高效地理解长文本内容。

论文链接:https://arxiv.org/pdf/2406.02547
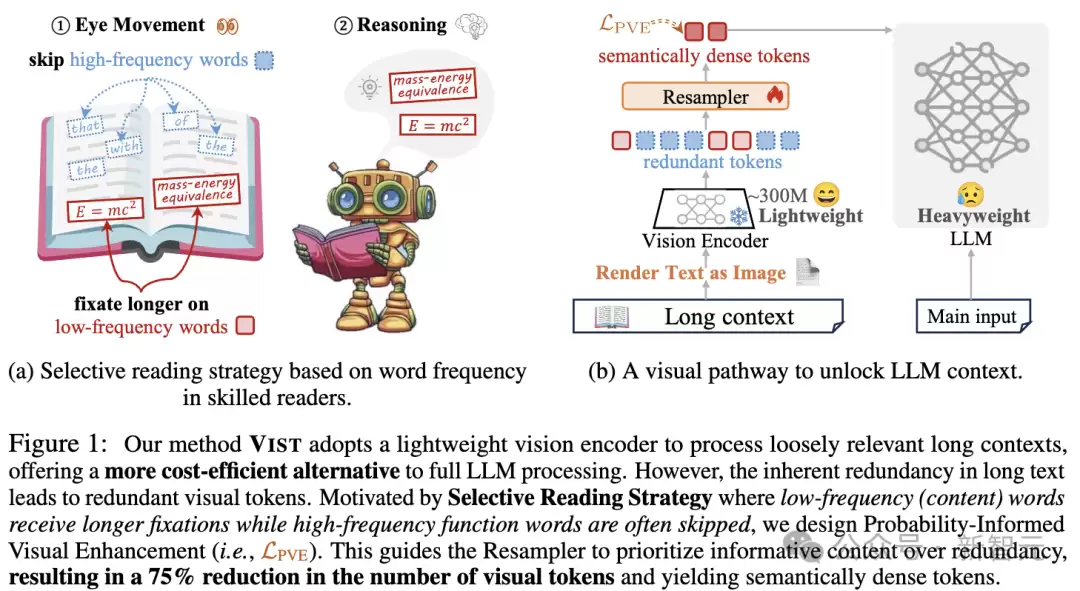
人类阅读文章时,并不会逐字读完每一个词汇。
像“的”“了”“和”这类功能性高频词,几乎会被大脑自动忽略。真正让我们停下目光的,是那些承载意义的低频词——名词、动词、数字等关键信息。
VIST的核心思想,正是让大模型也具备这种“选择性阅读”的智能。
它设计了一种模拟人类“快-慢阅读通路”的可视化压缩机制,让大模型在理解长文本时,既能快速扫读把握整体,又能深入思考重点内容:
快速通道:将远处的、相对次要的上下文内容渲染为图像,由冻结的轻量级视觉编码器快速提取显著性语义;
慢速通道:将关键性的邻近文本直接输入LLM,用于深度推理与语言生成。
这种“视觉+语言”的双通道协作模式,就如同人类的眼睛与大脑的配合——一边扫视全局获取脉络,一边聚焦要点进行深度思考。
VIST让模型真正具备了“像人一样速读”的智能。
凭借这一创新设计,在处理相同文本内容时,VIST所需的视觉Token数量仅为传统文本分词所需Token数量的56%,内存占用减少了50%。
用“视觉压缩”解锁长文本理解
早期的LLM主要通过分词器将文本拆分成离散的token输入模型进行处理,这种范式带来了许多优势,特别是实现了高度语义化。
但已有研究发现,经过大规模图文配对数据预训练,CLIP等视觉编码器能够自发掌握OCR识别能力,这使得它们可以直接理解文本图像内容,为长文本的可视化处理提供了强大工具。
VIST则借鉴了人类高效阅读的认知技巧,提出了全新的快-慢视觉压缩框架,用视觉方式处理长文本,让模型既能快速扫读把握大意,又能深度理解核心内容。
快速通道
将次要的长距离上下文渲染成图像,由轻量级视觉编码器处理;
通过重采样器将视觉特征进一步压缩至原尺寸的1/4;
压缩后的视觉特征再通过交叉注意力机制与LLM的主输入进行整合。
慢速通道
对邻近位置或核心文本直接交给LLM处理,进行深度推理和语言生成。
这种“扫视远处,专注近处”的处理方式,模拟了人类阅读的自然策略,让模型在长文本场景下既高效又精准。
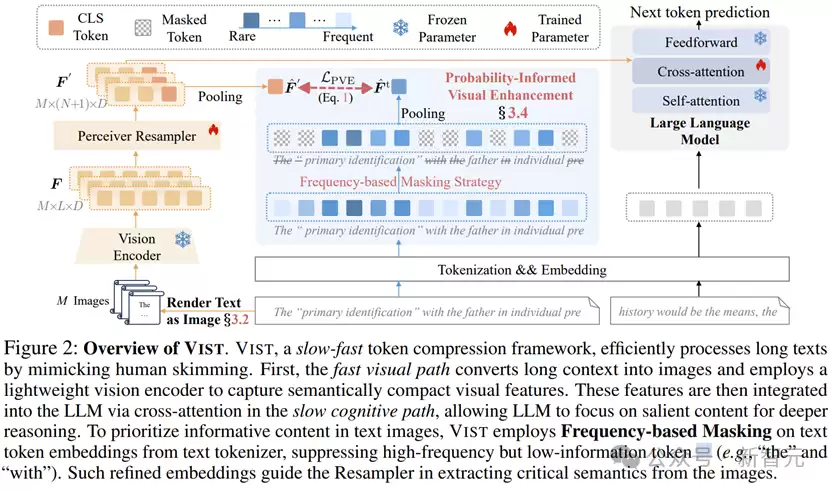
概率感知视觉增强
教模型学会“略读”
虽然视觉编码器(如CLIP)能力强大,但它们主要在自然图像上训练,对于渲染文本的理解能力有限。而且,长文本中往往充斥大量冗余信息,如果不加选择地处理,不仅浪费算力,还会被噪声干扰而抓不住重点。
为此,VIST引入了一个精巧机制——概率感知视觉增强(PVE),教会模型“略读”关键信息,忽略冗余词汇。

在训练过程中,PVE采用基于词频的掩码策略,把高频但信息量低的词(如英文中的"the"、"with")进行遮蔽,同时重点保留低频、高信息量的词汇,如名词、动词、数字等核心内容。
这些经过语义优化的文本嵌入有效指导重采样器从文本图像中提取更重要的语义信息,让视觉压缩模块变得更高效率且更精确。
视觉压缩的巨大潜力
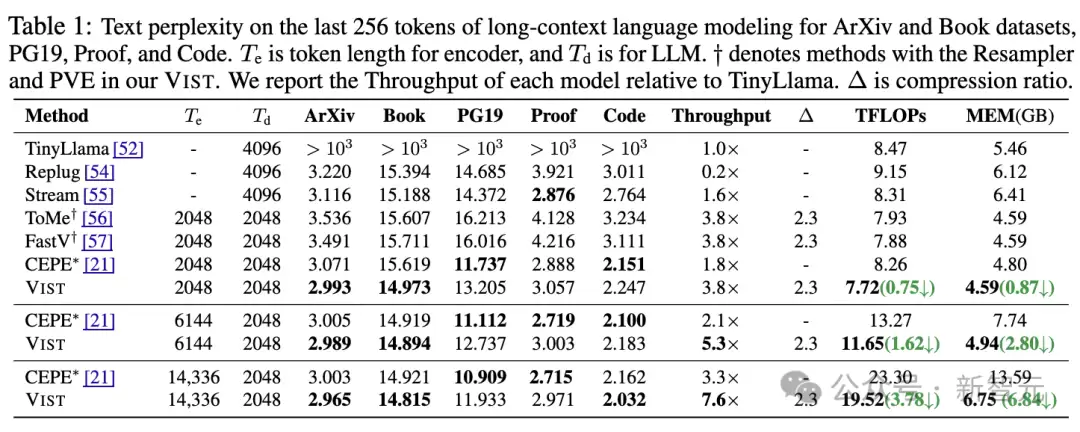
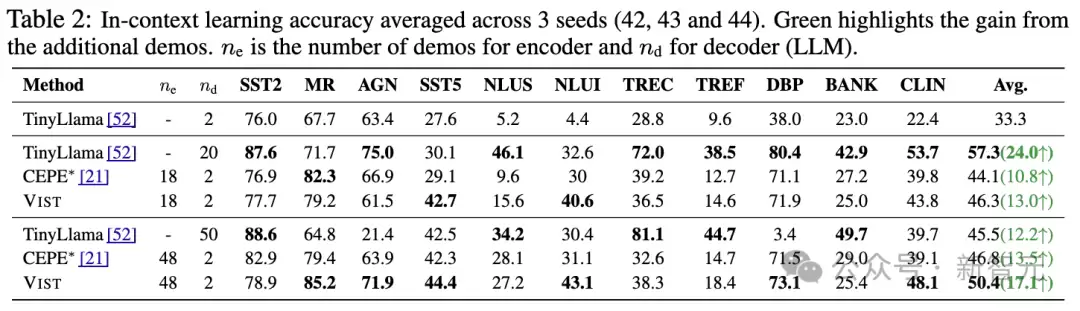
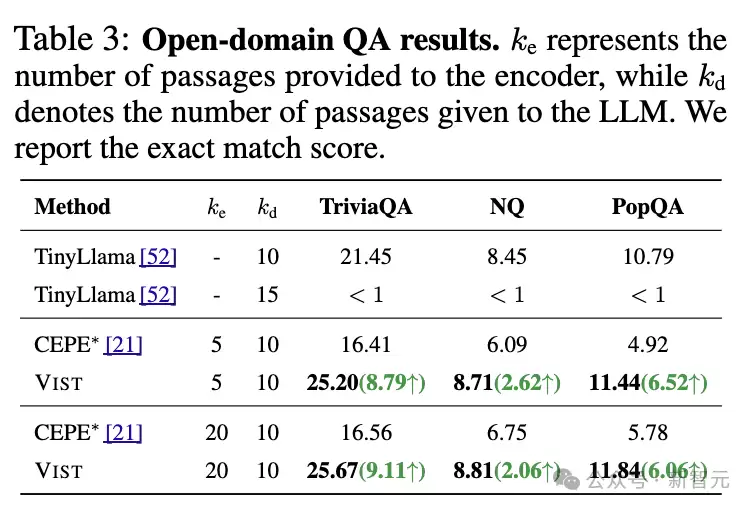
在开放域问答任务以及11个上下文学习基准任务上,VIST框架的表现显著优于基于文本编码器的压缩方法CEPE。
即使在极端条件下——所有章节仅通过视觉编码器处理——VIST仍能在开放域问答任务中达到与TinyLlama相当的性能,充分展示了视觉压缩在长文本处理中的可靠性。
此外,在处理相同文本内容时,VIST所需的视觉Token数量比传统文本Token减少56%(压缩比约为2.3,从1024个文本Token压缩至448个视觉Token),同时显存使用量降低50%,极大提升了计算效率。
让大模型“用眼睛读文字”
VIST利用轻量级视觉编码器,将冗长的上下文信息进行压缩处理,为大语言模型提供了一条高效、低成本的新路径。
更巧妙的是,视觉编码器还能充当视觉文本分词器,带来四大显著优势:
1. 简化分词流程传统文本分词器依赖复杂规则和固定词表,通常涉及近十步人工预处理(如小写化、标点符号处理、停用词过滤等)。视觉编码器直接将渲染的文本视作图像输入,无需繁琐预处理,处理流程更直接高效。
2. 突破词表瓶颈传统分词器在多语言环境下容易受词表限制影响性能,而视觉编码器无需词表,统一处理多种语言文本,大幅降低嵌入矩阵和输出层的计算与显存开销。
3. 对字符级噪声更鲁棒视觉编码器关注整体视觉模式,而非单个Token匹配,因此对拼写错误或低级别文本攻击具备天然抵抗力。
4. 多语言高效处理尽管本文主要针对英文,视觉文本分词器在其他语言中同样高效:与传统分词相比,可减少62%的日文Token、78%的韩文Token、27%的中文Token,在处理长文本时优势尤为显著。
结语与未来展望
VIST 展示了“视觉 + 语言”协作在大模型长文本理解中的巨大潜力:它让大模型能够“像人一样读”,既能快速扫视冗余信息,又能专注思考关键内容。
未来,视觉驱动的Token压缩技术很可能成为长上下文LLM的标准组件。随着模型规模不断增长,这种“先看再读”的策略,将帮助大模型在保证理解能力的同时,大幅降低计算成本,为多模态智能理解铺平道路。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

如何制作极具商务高级感的路演PPT 利用Gamma一键定制极简黑金视觉模版
说实话,每次看到别人在商务路演时拿出那种设计精良、气质高端的PPT,你是不是也暗自羡慕过?但咱们既不是专业设计师,又抽不出大把时间琢磨排版配色——这种困境我太懂了。好在现在有了Gamma这样的智能平台,它内置的模板系统能让你快速产出专业级PPT。今天我就以最经典的极简黑金风格为例,带你走一遍具体操作

airtag不更新实时位置怎么设置_AirTag位置刷新与实时更新设置方法
不知道你有没有遇到过这种情况:在“查找”App里盯着自己的AirTag,结果发现它的位置好像“卡住”了,几个小时甚至更久都没动过。这事儿确实挺让人着急的。别担心,这通常不是AirTag坏了,而是它的位置更新机制暂时“打了盹儿”。AirTag本身不能联网,它得靠路过的其他Apple设备“帮个忙”,才能

OpenClaw能否成为下一代智能入口
随着2026年初OpenClaw在GitHub上19天内斩获16 5万星标的现象级爆发,“xxClaw”系列产品迅速成为全球AI领域关注的焦点。国内像腾讯、字节、阿里、小米、华&为等科技巨头纷纷入局,推出各自的Claw产品,围绕“智能入口”的争夺战正式打响。 2026年3月的深圳,腾讯大厦楼下排起长

ai保存的时候怎么把源文件设置成不可编辑_Ai导出PDF设置权限密码禁止编辑方法
不知道你有没有遇到过这种情况:辛辛苦苦用AI设计工具做好方案,导出成PDF发给客户或同事后,没过多久,就发现自己的排版被改得面目全非,或者内容被轻易复制走了。老实说,这种感觉真的很糟糕。如果你也想保护自己的劳动成果,让导出的PDF文件“只可远观,不可亵玩”——也就是无法被随意编辑、复制或修改,那今天

如何快速用上OpenClaw?这应该是全网使用 OpenClaw 最方便快捷的方式
一键安装,直接开始“养虾” 如果你最近关注过OpenClaw(龙虾),想必已经见过五花八门的安装教程。但真正动手尝试时,很多人会遇到这样的困扰: 需要配置环境、准备API Key、熟悉命令行操作,甚至还要折腾Docker和各类依赖——光是这些准备工作,就足以让不少用户望而却步。 不过现在有个好消息:








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
