




玩转多主体操控:角色锁定助你打造个性化文生图

LayerComposer为个性化图像生成带来了革新突破,让用户能够像在Photoshop里那样自如控制元素的位置与大小,彻底解决了传统方法在交互性与多主体扩展方面的难题,实现更自然高效的创作体验,推动个性化生成技术迈入主动交互的全新阶段。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
大型扩散模型(如Stable Diffusion)让我们能够从文字生成高保真图像。但当用户希望"生成我和朋友们在不同场景中的合照"时,现有个性化生成方法(如DreamBooth、IP-Adapter)仍然面临两个根本性问题:
缺乏交互性:无法自由控制人物的空间位置、大小与相互关系;难以扩展到多主体:每增加一个人物,内存和算力需求就会线性增长。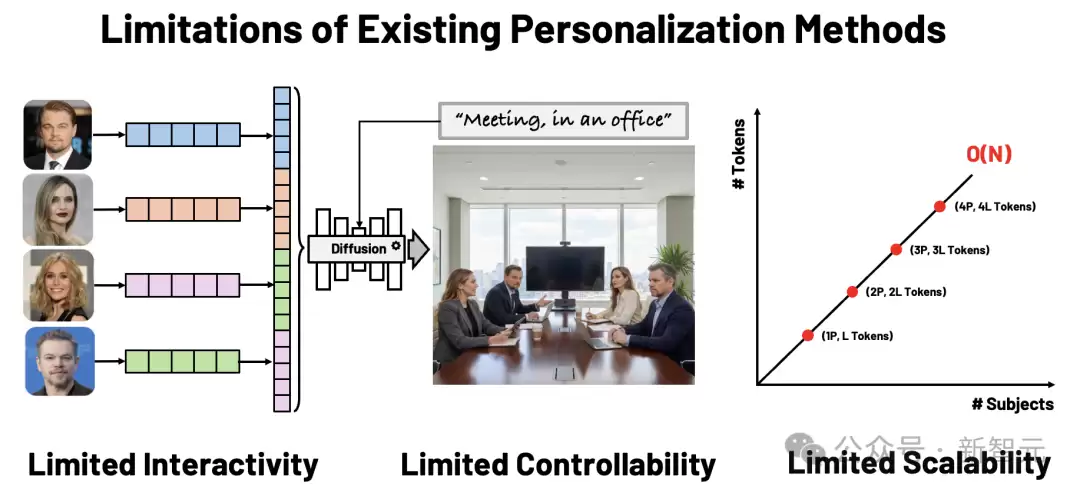
LayerComposer的目标,正是要打破这两大限制,让用户可以直观地控制在哪里放置什么样的元素,实现可控且高效的个性化生成。

项目地址:https://snap-research.github.io/layercomposer/
论文地址:https://arxiv.org/abs/2510.20820

"一张由雪人和三位女孩组成的合影"——你可以像在Photoshop里那样,自由放置、缩放、锁定角色,然后让模型完成剩下的工作。
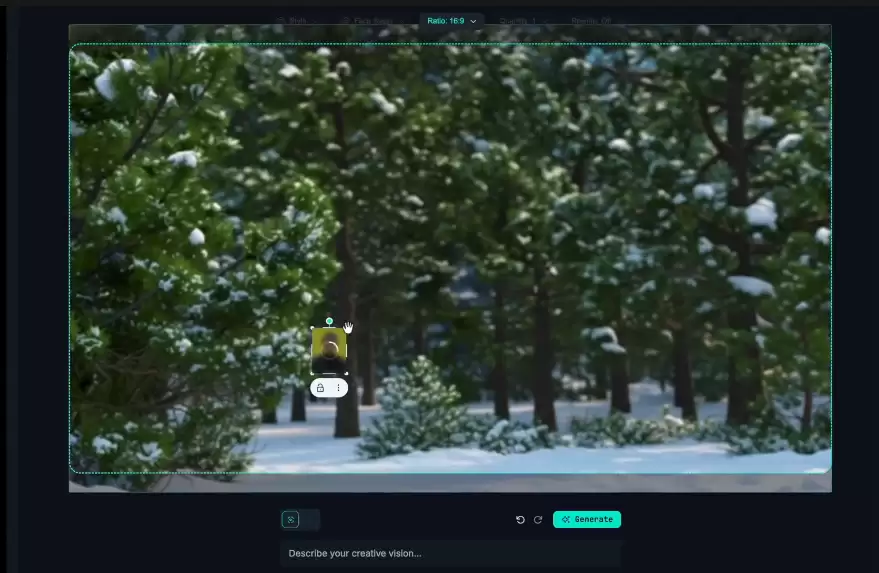
LayerComposer的三大设计
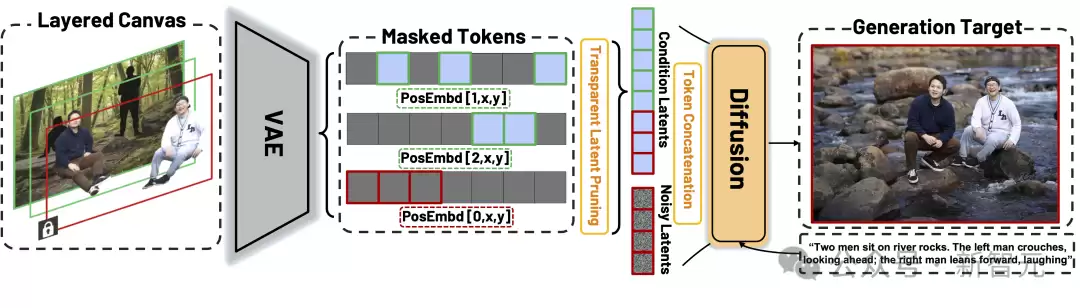
分层画布(Layered Canvas)
每个人物、物体或背景都放在独立的RGBA图层中(包含透明通道的图片),这样可以:
避免人物遮挡导致的信息丢失;通过透明潜裁切(Transparent Latent Pruning)显著降低计算量;支持任意数量的主体组合。类似于在Photoshop里,每一层就是一个独立的角色,可以随意移动、缩放或删除。
锁定机制(Locking Mechanism)
每一层都可以选择"锁定(Lock)"或"解锁(Unlock)」:
锁定层 → 模型必须高保真地保留该层,仅允许细微的光照调整;解锁层 → 模型可以根据文字描述自由生成姿态、表情或互动。你可以锁定背景,让随提示变化,也可以锁定一个角色姿态,生成其他人围绕他互动。
这种"可选保真度"让LayerComposer比以往方法更接近人类的创作流程。
模型-数据共设计(Model–Data Co-Design)

LayerComposer的锁定机制无需修改网络结构。
研究人员通过"位置嵌入"(positional embedding)与"数据采样策略"共同实现:
锁定层共享相同的空间编码;解锁层使用独立的编码,以避免重叠混淆。这种轻量化设计,可以在现有扩散模型(如FLUX Kontext)上直接适配。
实验结果
多主体、高保真、强可控
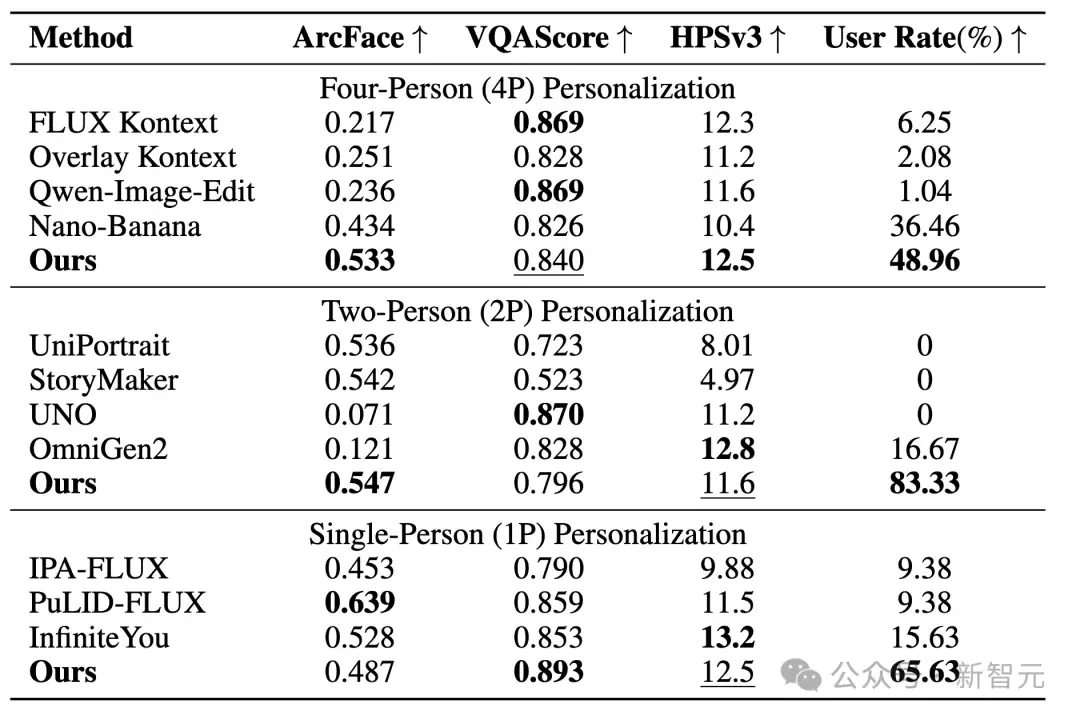
四人场景(4P)

在四人同框的任务中,LayerComposer的生成质量显著优于FLUX Kontext、Qwen-Image-Edit、Gemini 2.5 Flash Image等模型,能在存在遮挡的情况下保持人物结构完整,并忠实地还原每个人物。
双人互动(2P)

在需要两人互动的场景(如"一起吃饭"、"握手")中,LayerComposer能生成自然的姿态与空间关系,不再出现"复制粘贴"或"缺少人物"的问题,用户偏好率达到83.3%,远超OmniGen2等最新模型。
单人个性化(1P)

即使只生成单人肖像,LayerComposer仍然展现出卓越的表现:
在保持身份一致的同时,能灵活生成不同表情与动作(如微笑、闭眼、吃饭等),完美避免了"贴脸"效应。
消融实验
锁定与分层的作用

锁定机制(Locking Mechanism)
为了展示锁定机制的效果,研究人员逐步对每一层输入进行锁定。
被锁定的层会保留该人物的姿态——模型只会在基础上进行"外延绘制"(outpainting)和轻微的细节光照调整。需要强调的是,这与"掩码推理"不同:在掩码推理中,被遮挡的区域完全不会被更新。
另外,在实验设置中,未锁定的层会根据已锁定的内容和整体场景上下文灵活调整,从而实现自然的协调与融合。
分层画布(Layered Canvas)
如果不使用分层画布,模型就只能以单张拼接图像作为条件输入,如图中"Inputs"一列所示。
可以看到,在"w/o layered canvas"(无分层画布)的结果中,由于拼接重叠造成的遮挡,会导致信息缺失。
例如,左边女子圣诞帽上的球被遮挡后,在生成结果中完全消失。
相比之下,提出的分层画布能够显式地处理遮挡问题,从而避免此类伪影和细节丢失。

通过在Layered Cavas中调整每个subject在各layer的位置,LayerComposer支持直观的空间布局调控。
总结
LayerComposer让多主体个性化生成从"被动输入"迈向了"主动创作"。
用户不再只是输入文本,而是真正参与到构图过程中。
从DreamBooth到LayerComposer,个性化生成,终于有了交互的灵魂。
未来展望
尽管LayerComposer带来了交互式个性化的新范式,但仍存在一些挑战。
在需要"复杂物理推理"(如"坐在输入图片椅子上")的场景中可能失败。
未来,研究人员计划让LayerComposer支持更强的理解能力和更多模态,以促进人机协同创作:
结合大语言与视觉模型的理解能力,实现语义级别的自动布局与构图建议;支持视频级别的分层个性化,让交互式创作从静态图像走向动态场景;探索生成与编辑的统一界面,让用户在同一画布上无缝地修改、添加与再生内容。这种以"分层画布"为核心的交互式个性化范式,将成为下一代生成式创作工具的重要方向。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

一篇讲透:豆包、元宝、DeepSeek、Kimi、WorkBuddy,职场里到底怎么分工
别再把所有 AI 当成一个东西:WorkBuddy 和豆包、元宝、DeepSeek、Kimi,到底该怎么选? 这一年,AI 的进化速度着实叫人眼花缭乱。 大家的关注点,早就从“这工具能写文章吗”跳到了“它能不能帮我做方案、改稿子、整理会议纪要,甚至把任务往前推一步”。 于是,一个新问题浮出水面。 很

我用WorkBuddy“克隆“了一个我,从此每句话像我自己说的
如何使用WorkBuddy深度学习我的说话方式,让每一份文案都自带个人风格 作为一名企业培训师,每年主讲上百场课程是行业常态。无论是线下公开课、线上直播,还是视频号、公众号的内容创作,每天的工作状态不是在授课,就是在准备各种讲稿的路上。早期借助通用AI工具辅助创作,写作效率确实有所提升,但生成的内容

英国视障跑者挑战马拉松,将借助智能眼镜“看”到赛道、辨别方向
英国视障跑者挑战马拉松,将借助智能眼镜“看”到赛道、辨别方向 最近有一则科技助残的新闻,让人眼前一亮。当地时间4月2日,英国BBC报道称,视障跑者克拉克·雷诺兹正计划借助一项创新技术,参加一场全程马拉松。这项技术的巧妙之处在于,它能让世界另一端有视力的志愿者,实时“看到”雷诺兹眼前的景象,并为他提供
彻底卸载 OpenClaw (龙虾) 指南
彻底卸载 OpenClaw (龙虾) 指南 想把 OpenClaw(大家常叫它“龙虾”)从你的系统里清理干净?这事儿得讲究个章法,胡乱删除往往治标不治本,残留的服务和文件就像散落在角落的贝壳,时不时硌你一下。接下来,咱们就按一套稳妥的流程,帮你把它请走。 卸载原则 核心原则就一句话:先停服务,再卸工

AI 让英国学生“不会思考”,近 6000 名英格兰中学教师表示担忧
AI让英国学生“不会思考”?近6000名教师敲响教育警钟 一项来自英国教育界的深度调查,为当前AI技术涌入课堂的热潮带来了冷静思考。据英国《卫报》4月2日报道,英格兰的中学教师们普遍观察到一种现象:随着人工智能在教育中的应用日益广泛,学生的批判性思维能力与深度思考习惯正面临下滑风险。这项由英国全国教








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程

















