




科学家:多数大语言模型测试标准存缺陷,难以客观评分

11月8日消息,科技媒体The Decoder今日报道称,牛津大学与华盛顿大学等机构联合发布的一项国际研究指出,目前大多数大语言模型的测试标准存在严重的方法论缺陷,这使得人们难以客观衡量人工智能的真实进展。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
研究人员系统梳理了2018至2024年间顶级人工智能学术会议发布的445篇基准测试论文,这些会议涵盖ICML、ICLR、NeurIPS、ACL等权威平台。在邀请29名领域专家进行评审后,发现这些论文均存在至少一个重大方法论漏洞。
研究报告显示,这些基准定义中普遍存在术语模糊或概念争议的问题。虽然78%的基准能够说明测试内容,但其中半数未能清晰定义"推理""对齐""安全性"等核心概念,导致研究结论缺乏可信度。
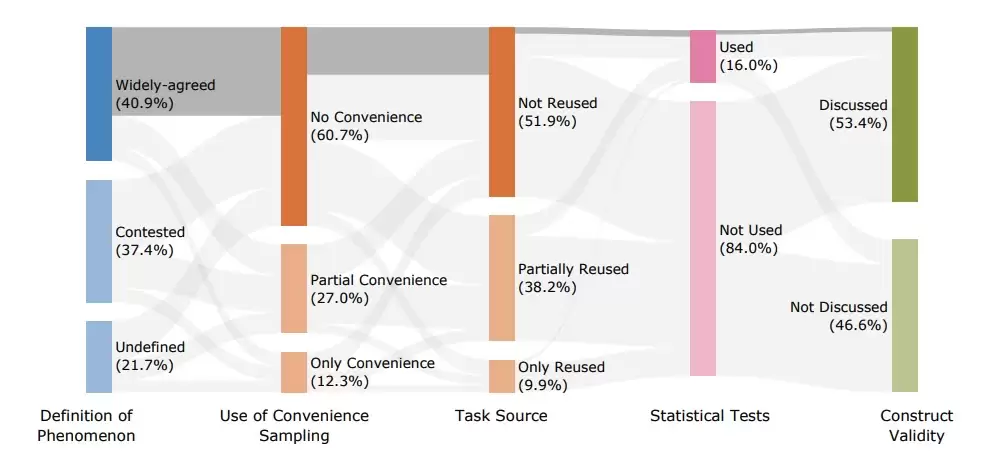
值得注意的是,约61%的基准测试评估了复合型能力,例如"智能体行为"。这类测试通常同时涉及意图理解、结构化输出生成等多个子任务,而这些子任务鲜少被单独评估,导致最终结果难以合理解读。
数据采样方法也是基准测试的另一个薄弱环节。约93%的论文采用便利抽样,12%完全依赖便利抽样,这些样本无法代表真实使用场景。此外,38%的测试复用了现有数据集,许多研究甚至直接使用其他测试集。这种做法可能扭曲大语言模型的实际表现,无法真实反映模型在复杂数学推理方面的能力水平。
此外,超过80%的研究使用"完全匹配率"作为评分标准,但仅16%采用统计校验方法来比较不同模型间的差异,还有13%使用人工评判。大多数测试未能提供不确定性统计或置信区间,严重削弱了结果的可信度。
研究团队也提出了具体改进建议。他们强调后续测试需要明确定义测试目标和边界,确保评估过程不掺杂无关任务,同时需要防范数据污染问题。建议采用严谨的统计与误差分析方法,从定量和定性两个维度着手,让研究结论更加准确可靠。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

京东直播新动作:刚需复杂指令与自由态数字人如何升级
编辑|泽南刚刚落幕的 2026 科技界「春晚」GTC 大会上,一个全行业的共识已经形成:AI 正在进入智能体(Agent)时代。然而,当各大厂商都在疯狂入局智能体时,一个尴尬的现实却摆在面前:这些聪

玻色量子完成10亿元B轮融资,刷新行业融资纪录
2026年3月31日,“十五五”规划专用量子计算机赛道唯一代表企业——北京玻色量子科技有限公司(以下简称“玻色量子”)完成10亿元B轮融资。本轮融资由北京金控、工银资本、朝阳顺禧、招银国际、深投控和

GitLab创始人借力AI抗癌:ChatGPT在现实世界中的真实用途
Sid 这个案例最震撼我的,不是“AI 参与抗癌”这几个字本身。而是它让我第一次很清楚地感觉到:AI 真正的用途,可能从来都不是回答问题。而是进入那些原本只有专家团队才能推进的复杂现实,把前面的认知

Claude已会点外卖!揭秘AI批量替代创业公司的未来危机
说句心里话,我确实不太待见 Anthropic(Claude 背后那家公司),但这并不妨碍它依然是目前全球最顶尖、最牛掰的 AI 公司,没有之一。这个世界就是这么现实:能力强弱和是非对错,那是两码事

黄仁勋站台的抱抱脸机器人卖爆了,背后公司竟来自中国
henry 发自 凹非寺量子位 | 公众号 QbitAI还记得Hugging Face去年推出的桌面机器人Reachy Mini吗?在刚发布的时候,量子位曾第一时间报道过这只身高28cm、体重1 5








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
























