




九成大模型评测方法存缺陷:直面语言模型信任危机

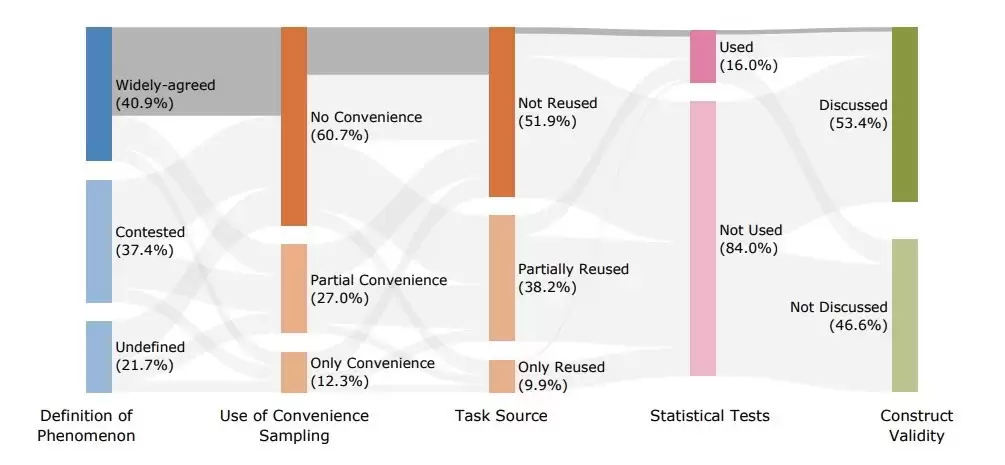
2025年11月,来自牛津大学与华盛顿大学等机构的联合研究揭示,当前大语言模型评测领域普遍存在方法论缺陷,严重影响了人们对人工智能发展水平的客观判断。研究人员系统梳理了2018至2024年间在主要人工智能学术会议上发表的445篇基准测试论文,并组织29位领域专家进行评审,结果发现所有论文均存在至少一项重大方法论问题。
该研究报告指出,多数基准测试对核心概念的界定存在模糊不清或缺乏共识的问题。虽然78%的测试体系声称涵盖特定能力评估,但其中半数未能对“推理”、“对齐”、“安全性”等关键术语作出明确定义,导致研究结论的基础薄弱,可信度受到质疑。
在测试设计层面,约61%的基准测评聚焦于复合型能力,例如“智能体行为”等综合表现。这类测试往往同时涉及意图理解、结构化输出生成等多个子任务,而各子项通常未被独立评估,使得最终结果难以准确归因和解释。
数据采样问题尤为突出,高达93%的论文采用便利抽样方式,其中12%的研究完全依赖此类非代表性样本,导致无法有效反映模型在真实场景中的实际表现。此外,38%的测试存在数据复用现象,部分研究直接沿用已有测试集,增加了模型因接触训练数据而产生偏差的风险,特别是在数学推理等复杂任务中可能严重高估实际性能。
评估标准的设定同样存在不足。超过80%的研究以“完全匹配率”作为主要评分依据,但仅有16%采用统计检验方法来判断模型间的差异是否显著,仅13%引入人工评价机制。绝大多数研究未能提供误差范围、置信区间或不确定性分析,削弱了结果的科学性与可比性。
针对上述问题,研究团队提出一系列改进建议:未来基准测试应当清晰界定评估目标与适用边界,避免测试过程中混入无关因素;必须防范数据污染,确保测试集的独立性与代表性;同时应结合严谨的统计方法与定性分析,加强误差评估,从多维度提升测评结果的准确性与可靠性。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

云米科技CEO奖励员工小米YU7 期待未来再奖励更多台
云米科技创始人兼CEO陈小平通过社交平台正式揭晓了公司年会上的“重磅大奖”:一辆小米YU7汽车,专为表彰一位长期服务核心客户、始终坚守岗位并成功推动项目实现关键突破的员工。获奖理由简洁而有力——“尽职尽责、持之以恒”。陈小平在现场还定下目标:“希望到2026年,能送出更多台车。” 这句话,既是对员工

腾讯开源Node模块联邦方案hel-micro-node
腾讯近日正式发布开源项目 hel-micro-node,作为 hel+ 生态体系中的核心组件,专门为 Node js 运行环境量身打造,旨在提供一种轻量化、高效率且易于使用的服务端模块联邦解决方案。与同类产品 @module-federation node 相比,hel-micro-node 在功能

doc个人图书馆因业务调整无偿转让寻找接管方
日前,知识分享平台“360doc个人图书馆”正式对外发布官方公告。自2005年上线以来,这一经典数字图书馆已稳健运营整整二十年,累计服务用户超过八千万,沉淀文章数量突破十一亿篇。作为国内知名的免费知识管理公益平台,它不仅承载了无数人的智慧积累与珍贵记忆,更在个人知识存档与内容管理领域保持了独特的品牌

iPhone Air 2最新传闻 散热与双扬声器及双摄成重点
细想起来,距离苹果那款备受期待的超薄系列新机——我们暂时称之为iPhone Air 2——正式亮相,其实已经不到一年了。产业链上陆续传出的消息都在暗示,苹果这次决心放一个大招,在散热、音频、影像这几个核心体验上动真格的。 iPhone Air 销量与市场反响 此前不少舆论认为初代iPhone Air

上海交大今日正式发布自研光学垂直大模型
光学领域最近迎来了一位重量级新成员——上海交通大学正式推出了面向光学垂直方向的大模型Optics GPT。官方将其定义为一位“数字光学顾问”,听起来可能有点抽象,但说白了,就是让一个AI系统把光学领域的所有核心知识吃透,然后能稳稳当当地帮科研、工程和教学解决问题。 如果拿ChatGPT这类通用大模型








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2026-07-08 12:45
2026-07-08 12:44
2026-07-08 12:44
2026-07-08 12:44
2026-07-08 12:44
2026-07-08 12:44
2026-07-08 12:43
2026-07-08 12:43
热门教程
2026-07-08 12:45
2026-07-08 12:44
2026-07-08 12:44
2026-07-08 12:44
2026-07-08 12:44
2026-07-08 12:44
2026-07-08 12:43
2026-07-08 12:43
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
