




摩尔线程大模型对齐研究获国际认可:URPO框架入选AAAI 2026

11月13日消息,摩尔线程推出的新一代大语言模型对齐框架——URPO统一奖励与策略优化框架,相关研究论文近日被人工智能领域的国际顶级学术会议AAAI 2026收录,为简化大模型训练流程、突破模型性能上限提供了全新的技术路径。
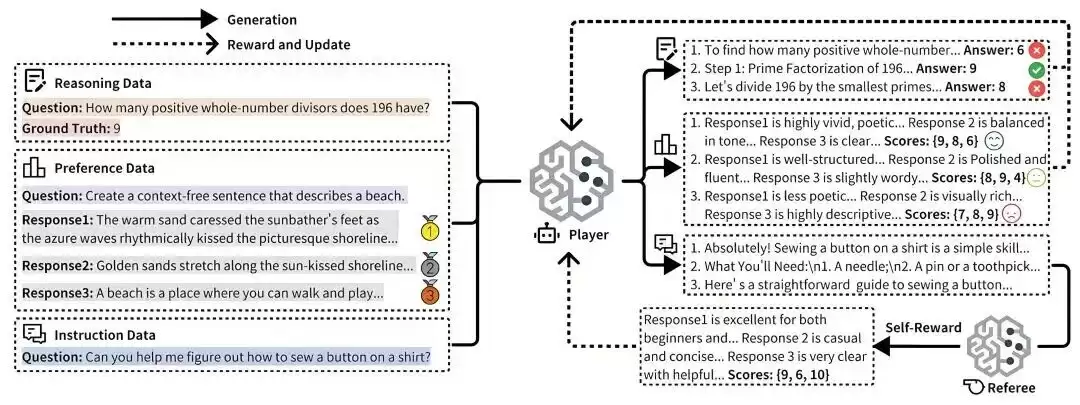
据介绍,在题为《URPO:A Unified Reward & Policy Optimization Framework for Large Language Models》的论文中,摩尔线程AI研究团队提出了URPO统一奖励与策略优化框架,将“指令遵循”(选手)和“奖励评判”(裁判)两大角色融合于单一模型中,并在统一训练阶段实现同步优化。URPO主要从以下三个方面攻克技术挑战:
数据格式统一:将异构的偏好数据、可验证推理数据和开放式指令数据,统一重构为适用于GRPO训练的信号格式。
自我奖励循环:针对开放式指令,模型生成多个候选回答后,自主调用其“裁判”角色进行评分,并将结果作为GRPO训练中的奖励信号,形成一个高效的自我改进循环。
协同进化机制:通过在同一批次中混合处理三类数据,模型的生成能力与评判能力得以协同进化。生成能力提升带动评判更精准,而精准评判进一步引导生成质量跃升,从而突破静态奖励模型的性能瓶颈。
实验结果显示,基于Qwen2.5-7B模型,URPO框架超越了依赖独立奖励模型的传统基线:在AlpacaEval指令跟随榜单上,得分从42.24提升至44.84;在综合推理能力测试中,平均分从32.66提升至35.66。作为训练过程中自然产生的“副产品”,该模型内部涌现出的评判能力在RewardBench奖励模型评测中取得了85.15的高分,表现优于其替代的专用奖励模型(83.55分)。
从摩尔线程最新获悉,目前URPO已在摩尔线程自研计算卡上实现稳定高效运行。同时,摩尔线程已完成VERL等主流强化学习框架的深度适配。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

安卓Gemini AI硬件需求公布 旗舰芯片与12GB内存成门槛
谷歌安卓AI助手GeminiIntelligence的硬件要求细节曝光。设备需搭载旗舰芯片、至少12GB内存,并支持GeminiNanov3端侧AI模型。同时,设备还需承诺至少5次系统升级和6年安全更新。目前兼容机型主要集中在2026年发布的新款手机,如Pixel10系列和三星Galaxy

安卓苹果跨平台互通升级 多款旗舰手机支持隔空投送功能
谷歌正积极推进安卓与苹果生态系统间的文件互通。继首批机型后,第二波更新将让三星GalaxyS25系列、一加15、荣耀MagicV6等多款安卓旗舰手机支持与iPhone的隔空投送功能。谷歌旨在解决多设备家庭中文件分享的难题,并计划在2026年将该功能覆盖至更多主流品牌。用户通过安卓的“快速分享”生

小米400升法式冰箱新品上市 支持60分钟快速自动制冰
小米米家近日推出了法式400L自动制冰冰箱新品,主打快速制冰与健康保鲜功能。该冰箱配备60分钟自动制冰系统,拥有99 9%抗菌率、全域离子净化和独立变温区。采用超薄平嵌设计,机身宽度65 4厘米,拥有400升总容积。产品首发价2999元,叠加国家家电补贴后到手价可至2549 15元,并提供了压缩机1

小米17 Max核心体验今晚直播揭晓,卢伟冰户外爆料六款新品
小米总裁卢伟冰于5月16日17点进行户外露营主题直播,集中爆料多款新品。直播重头戏是旗舰手机小米17Max,将完整展示其四大核心体验。同时,小米首款耳夹式耳机真机首次亮相,小米龙虾miclaw将演示手机跨设备操控电脑与智能家居。直播还包含618好物推荐、福利抽奖,并设置露营互动环节,卢伟冰也将探讨

小米SU7 GT车厘子红实车到店 月底发布性能参数抢先看
小米汽车旗下高性能SUV车型YU7GT已开始向全国门店铺货,实车主打车厘子红配色。该车定位跑车级SUV,拥有1003匹马力、2 95秒破百的强劲性能,同时续航达705公里。车辆由小米欧洲研发中心参与调校,外观采用专属GT设计语言,轴距3000mm,预计将于5月底正式发布。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
