




阿里千问登顶全球冠军,超越Gemini3与GPT5.1推理能力

11月26日消息,今日空间推理基准测试SpatialBench更新了最新一期榜单,阿里千问的视觉理解模型Qwen3-VL与Qwen2.5-VL强势占据冠亚军位置,超越了Gemini 3、GPT-5.1、Claude Sonnet 4.5等国际顶尖模型。
SpatialBench榜单显示,Qwen3-VL-235B与Qwen2.5-VL-72B分别取得了13.5和12.9分的优异成绩,显著领先于Gemini 3.0 Pro Preview(9.6分)、GPT-5.1(7.5分)及Claude Sonnet 4.5等海外头部模型。
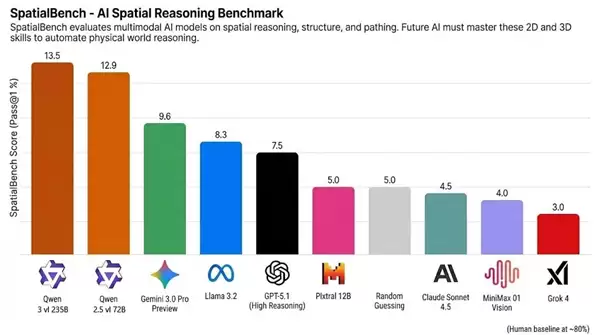
不过需要指出的是,AI大模型的整体表现与人类水平仍存在差距。人类基准线约为80分,能够专业处理电路分析、CAD工程和分子生物学等复杂空间推理任务,而目前大模型还无法完全自动化完成此类工作。
据了解,Qwen2.5-VL于2024年开源,Qwen3-VL则是阿里在2025年开源的新一代视觉理解模型。
Qwen3-VL在视觉感知和多模态推理方面实现了重大突破,在32项核心能力测评中超越Gemini 2.5 Pro和GPT-5。该模型不仅能调用截图、搜索等工具完成“带图推理”,还能通过一张设计草图或一段小游戏视频直接进行“视觉编程”。

与此同时,Qwen3-VL专门增强了3D检测能力,能够更准确地感知空间关系。基于该模型,机器人可以更好地判断物体方位、视角变化和遮挡关系,实现远处物体的精准抓取。
目前,Qwen3-VL已开源不同版本,包括2B、4B、8B、32B等密集型模型以及30B-A3B、235B-A22B等MoE模型,每个模型都提供指令版和推理版两款,是当下最受企业和开发者欢迎的开源视觉理解模型。同时,Qwen3-VL模型也已上线千问APP,用户可免费体验。
据悉,SpatialBench是近年来兴起的第三方空间推理基准测试榜单,主要聚焦多模态模型在空间、结构、路径等方面的综合推理能力,被AI社区视为衡量“具身智能”进展的新兴测试标准之一。
SpatialBench不仅测试模型已有的知识储备,还重点评估模型在二维和三维空间中感知和操控抽象概念的能力,这对具身智能的落地应用尤为关键。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

中芯国际封装技术最新布局与战略部署解析
5月15日,中芯国际在业绩说明会上披露了一项关键战略布局:公司自2015年起便已前瞻性地投入封装技术研发,尤其在先进封装领域进行了长期积累。经过数年的快速发展,其战略路径已非常明确——专注于为自身晶圆制造客户提供所需的关键前端封装技术支持。基于这一战略,中芯国际在过去十年间持续深耕3D CIS(CM

阿里巴巴推出AI工业知识考试系统确保回答准确性
最近,工业AI领域有一项研究值得关注。这项由阿里巴巴集团淘宝天猫多模态与工业AI团队主导的工作,已于2026年5月正式发布,论文编号为arXiv:2605 10267v2。其核心成果,是一套名为IndustryBench的专业测试系统。 不妨设想这样一个场景:你是一家工厂的采购经理,正考虑用AI来核

腾讯北大联合研发强化学习新方法提升机器人全局决策能力
强化学习是一种让智能体通过与环境交互、从试错中学习最优决策策略的人工智能技术。其核心机制类似于训练宠物:做出正确行为给予奖励,错误行为则没有。智能体在模拟或真实环境中不断尝试,根据反馈调整策略,最终找到获得最高累积回报的行动序列。然而,传统强化学习的样本效率低下是公认的难题——智能体往往需要数百万甚

香港中文大学研发频谱守护者优化器提升AI训练稳定性
训练大型语言模型,如同在云端构建一座持续生长的知识大厦。随着模型层数不断增加,任何微小的参数偏差都可能被逐层放大,最终导致训练过程失控。如何确保这座大厦在建造过程中始终保持结构稳定,一直是困扰研究人员的核心挑战。 近期,一项由香港中文大学、马克斯·普朗克智能系统研究所和西湖大学联合发布的技术报告,带

豆包服务中断原因与恢复时间详解
5月19日晚间,“豆包崩了”这一话题迅速冲上各大社交平台热搜榜首,引发广泛关注。众多用户反映,豆包AI服务突然出现中断,导致正在进行的在线学习、文案创作、代码编程等工作被迫暂停,一时间用户反馈激增。 事实上,这并非豆包首次出现服务异常问题。回顾今年1月28日,豆包就曾发生过一次影响范围较大的区域性服








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
