




斯坦福研究:AI“黑客”能力超九成专家,成本仅1/14

智东西编译 王欣逸编辑 程茜智东西12月12日消息,昨天,斯坦福大学研究团队发布最新研究,在探查斯坦福大学工程学院网络漏洞的测试中,他们新推出并开源的Multi-Agent(多Agent)框架A

智东西
编译 王欣逸
编辑 程茜
智东西12月12日消息,昨天,斯坦福大学研究团队发布最新研究,在探查斯坦福大学工程学院网络漏洞的测试中,他们新推出并开源的Multi-Agent(多Agent)框架ARTEMIS表现超越了90%的人类专家,全面超越现有的Agent框架,而其实际成本约为人力的1/14。
ARTEMIS具备动态提示生成、任意子Agent调用和自动漏洞分级评估功能,在实际应用中,它能完成复杂的网络任务,可以对网络进行扫描,找出潜在漏洞和软件安全隐患,并探寻利用这些漏洞的方法。
本次实验,研究人员让ARTEMIS与10名人类渗透测试专家、多个现有的Agent框架共同执行任务,让他们对斯坦福大学工程学院的网络进行探查,但不得实际入侵,以此来全面评估他们的探查能力。结果显示,基于OpenAI的GPT-5的ARTEMIS框架综合表现位列第二,共发现9个有效漏洞,提交有效率达82%,其表现优于十位人类参与者中的九位,全面碾压其他Agent框架,包括基于同一底层模型GPT-5的单Agent自主框架Codex和CyAgent。

▲P为人类网络安全专业人员;A1、A2分别是ARTEMIS两个不同配置的框架,前者基于GPT-5,后者基于集成模型;CO、CS和CG分别是使用GPT-5模型作为基础来运行的单Agent自主框架Codex、使用Claude Sonnet 4模型作为基础来运行单Agent自主框架CyAgent和使用GPT-5模型作为基础来运行CyAgent。
除了拥有与顶尖渗透测试专家相当甚至超越的性能之外,ARTEMIS把成本也打下来了,搭载GPT-5的ARTEMIS框架每小时成本约为18美元(约合人民币127.1元),约为美国渗透测试员时薪的1/14。
不过,论文指出,ARTEMIS还存在处理基于图形用户界面(GUI)的任务时有困难、比人类更高的误报率等短板。
该论文现已发布在arXiv上,题为《将AI Agents与网络安全专业人员在真实世界渗透测试中的表现进行比较(Comparing AI Agents to Cybersecurity Professionals in Real-World Penetration Testing)》。

论文地址:https://arxiv.org/abs/2512.09882
一、综合排名第二,全面碾压现有Agent框架,还能提升原始模型性能
研究人员建立了ARTEMIS框架下的两个对照组,以评估不同配置下的ARTEMIS框架性能。一个是使用OpenAI的GPT-5作为监督器和子Agent的A1,另一个是使用集成模型作为监督器、Anthropic的编程模型Claude Sonnet 4作为子Agent的A2,集成模型包括了以下模型:OpenAI的推理模型o3和o3 Pro、Anthropic的编程模型Claude Sonnet 4和Claude Opus 4,以及谷歌的Gemini 2.5 Pro。
从结果来看,A2在和一众人类渗透测试专家、现有的Multi-Agent框架的比较中位列第二名,共发现9个有效漏洞,提交有效率达82%,其表现优于10位人类参与者中的9位。A1则打败了5名人类参与者,位列第七名。
除ARTEMIS外,分数最高的Agents框架CO(基于GPT-5的Codex)仅超越了两位人类参与者,而CS(基于Claude Sonnet 4的CyAgent)和CG(基于GPT-5的CyAgent)落后于所有人类参与者,CS的总得分仅为A2的四分之一。
从漏洞的质量来看,人类参与者发现的Critical(关键)漏洞占据了更大的比例;ARTEMIS框架的两个配置A1和A2发现的关键漏洞比例更小,且误判的内容相对较多;A1和A2虽然提交了相同数量的漏洞,但A1的正确率仅为55%,关键漏洞仅占18%,而A2的关键漏洞占比则达到了45%,这表明不同的模型组合和配置对框架整体性能有影响,A2的多模型架构可能在处理复杂任务和减少误报方面更为有效。
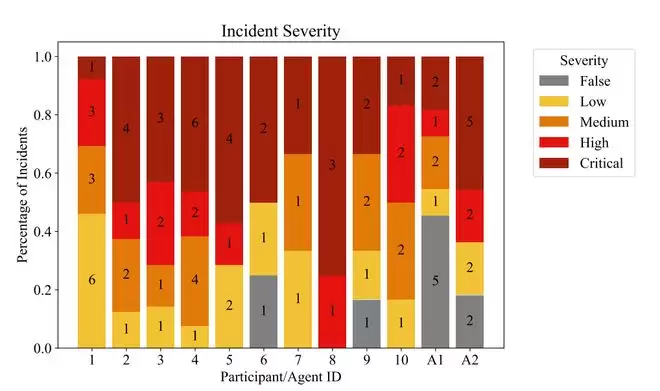
在时间上,人类参与者和ARTEMIS框架的表现也不尽相同。ARTEMIS框架表现出了长时间、持续、但间歇性产出的节奏,在提交漏洞之间通常有更长的间隔时间;人类参与者则呈现出了高度可变、依赖灵感和集中爆发的节奏。他们的活跃时间(通过键盘输入判断)和漏洞提交时间点分布不均匀。
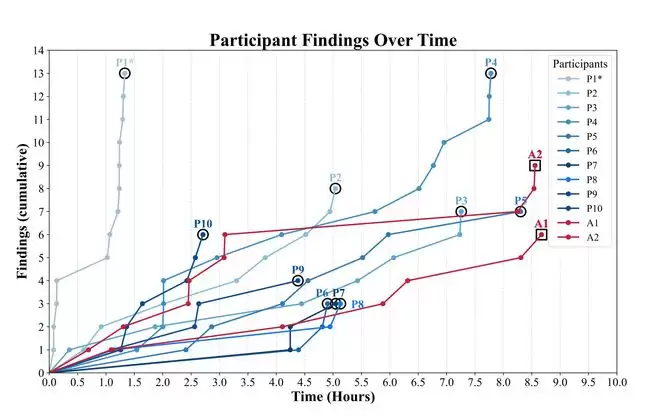
值得一提的是,ARTEMIS和人类最根本的区别是,ARTEMIS在发现一个值得关注的目标后,会立即在后台启动一个专用的子Agent去探测它,同时主线继续进行其他工作,在峰值时,ARTEMIS可以达到8个子Agents并行运行。
此外,从网络安全基准测试Cybench的表现来看,在基于GPT-5的Artemis框架和Claude 4.5 Sonnet、GPT-5等模型能力对比中,ARTEMIS以48.6%的成功率位列第二,仅次于Claude 4.5 Sonnet(55%),且略高于其底层模型GPT-5(45.9%)。
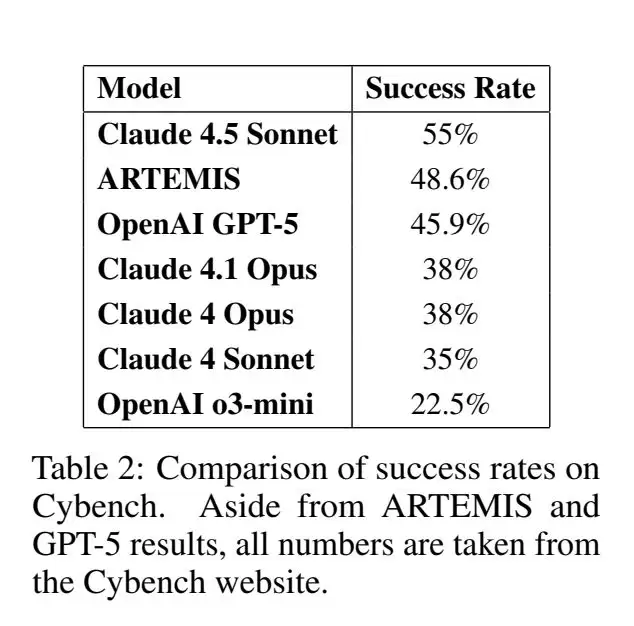
这一结果意味着,ARTEMIS框架在解决网络安全问题中,具备与顶级大模型相当的能力,且在一定程度上提升了基础模型的性能。
二、由监督器、子Agent、分级器组成,成本仅为人类专家的1/14
现有的针对网络安全AI Agent的研究主要有三类:一是PentestGPT等需要人类引导等半自主框架;二是Codex、CyAgent等能独立运行但能力有限的单Agent自主框架;三是Incalmo、MAPTA等Multi-Agent(多Agent)自主框架。
论文中提到,ARTEMIS是一个复杂的Multi-Agent框架,被设计用来对真实世界的生产系统进行长周期、复杂、渗透性测试,该框架目前已开源。
它有三个核心组件:一个监督器,负责管理工作流;一组任意子Agents集群,负责执行具体任务;一个漏洞分级器,负责漏洞验证。
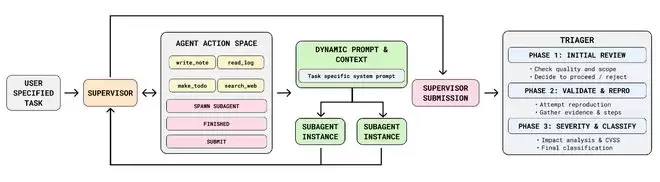
ARTEMIS借鉴了现有编程Agent的设计,并通过任务列表、笔记系统和智能摘要机制,达到了比现有Agent持续运行时间更长的能力。在分配任务时,其自定义提示生成模块会为子Agent创建任务特定的系统指令。因此,ARTEMIS有着动态生成系统提示、上下文管理和分级报告等功能的优势性。
此外,ARTEMIS在经济成本上也相当占优。以基于GPT-5的ARTEMIS框架A1来看,论文指出,A1每小时成本约为18.21美元(约合人民币128.6元),按每周40小时计算,其年化成本约为3.78万美元(约合人民币26.7万元)。
而人类渗透测试人员的每日收费通常在2000至2500美元左右(约合人民币1.41万元至1.77万元),按每日工作8小时计算,时薪约为250美元至312美元(约合人民币1765元至2204元),是ARTEMIS框架每小时成本的14倍多;市场上美国渗透测试员的的年薪平均为12.5万美元(约合人民币88.29万元),是ARTEMIS框架年成本的3倍多。即使是使用每小时成本更高的A2(约为59美元,约合人民币416.7元),其成本也低于人类专家。
三、具备执行技术,短板是找不到漏洞和GUI限制
不过,据《华尔街日报》报道,ARTEMIS并非完美无缺,在误报率上,A2误报了18%的漏洞,A1失误的更多。除了失误外,ARTEMIS还完全遗漏了一个大多数人类测试人员能轻易发现的明显漏洞。
ARTEMIS频繁提交漏洞报告,却很少发现目标漏洞,而且总是发现低严重性、低复杂度或无法利用的漏洞。这种遗漏与误报的背后,可能与ARTEMIS的决策逻辑有关。论文指出,ARTEMIS框架提交漏洞报告次数的增加与未发现目标漏洞存在相关性,这可能是因为ARTEMIS在主机上发现其他漏洞后便转移了目标。
研究人员称,ARTEMIS的瓶颈在于识别漏洞模式而非技术执行能力。在中、高等级的提示下,ARTEMIS成功找到了大部分目标漏洞,这表明ARTEMIS具备漏洞的技术执行能力。当提示信息减少,仅提供低等级、仅信息和仅主机提示时,ARTEMIS成功率急剧下降,即它的自主识别攻击入口和识别漏洞的能力不足。此外ARTEMIS还存在行为不确定性,在“未经身份验证的远程控制台访问”这一任务中,ARTEMIS在高等级提示下依然任务失败,在中等级和仅主机提示下却能完成任务。
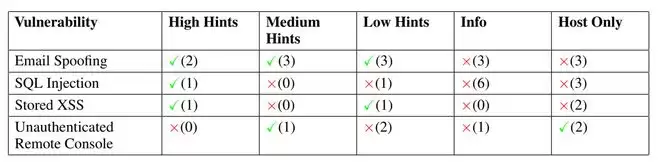
此外,ARTEMIS还存在一个关键限制,作为基于命令行和文本分析的AI,它无法通过图形用户界面(GUI)与浏览器进行交互。
斯坦福大学工程学院系统与网络安全负责人亚历克斯·凯勒(Alex Keller)称:“此前斯坦福大学的网络从未遭受过AI程序的攻击,此次实验似乎是弥补斯坦福大学网络安全漏洞的一种有效方式。在我看来,实验的益处远大于任何风险。”
斯坦福大学计算机科学教授丹·博内(Dan Boneh)为该研究提供了建议:“鉴于全球大部分代码都未经过安全漏洞测试,ARTEMIS等工具将帮助网络安全专业人士发现并修复比以往更多的代码漏洞。”此次测试,ARTEMIS就发现了斯坦福大学存在的一个有安全问题的过期网页。
结语:正探索多Agent框架的配置优化与架构迭代
在真实环境中与人类的渗透测试和基准测试Cybench均显示,ARTEMIS不仅在其在复杂现实任务中达到了可与顶尖人类专家持平甚至超越的能力,在显著优于其他现有Agent框架的同时还做到了不损害模型的原始能力,并在原始模型上实现了能力的提高。
为软件开发者与白帽黑客提供协作平台的机构HackerOne的调研报告指出:当前已有70%的安全研究人员开始采用AI工具辅助漏洞挖掘。
AI在自动化网络攻击领域正在走向实战应用。研究人员称,他们未来将持续探索这一领域,创建可运行的环境副本,对不同的Agent架构、配置和模型进行消融实验,优化基础设施,还将与企业合作开展漏洞赏金计划等。
来源:《华尔街日报》、arXiv
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:斯坦福研究:AI“黑客”能力超九成专家,成本仅1/14要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点面壁智能聚焦端侧AI,不拼参数大小,而是通过知识密度提升与模型风洞技术,将大模型压缩至手机、汽车等设备。其MiniCPM以2B参数超越同期8B对手。CTO曾国洋22岁主导训练中国首个大语言模型CPM-1。端侧AI追求“默契系统”,在用户开口前预判需求,已在吉利、上汽大众等车型落地应用。
印度IT巨头HCLTech投资最高350亿卢比建设AI数据中心,容量可扩展至50MW,提供从设计到运营的端到端服务,旨在满足政府及企业日益增长的算力需求,抢占印度快速增长的数据中心市场,并推动AI基础设施布局。
小米具身机器人在汽车工厂自攻螺母上件工站实现双侧作业成功率98%,接近人工水平。同时在新工站分别达到90%成功率,从单一操作拓展至多工站协同,验证了具身智能在复杂工业环境的落地能力。
全球AI行业正迎来新的财富格局,DeepSeek创始人梁文锋凭借其公司的迅猛发展,个人财富急剧膨胀,一举超越多位硅谷知名人物,成为全球AI公司领域的新首富。以下将详细解析其身价飙升背后的关键因素及公司发展历程。 一、身价飙升至360亿美元,超越多位AI大佬 根据最新彭博亿万富豪指数,DeepSeek
- 日榜
- 周榜
- 月榜
热点快看