




谢燊宁REPA大幅优化:不到4行代码实现高效改进


机器之心报道
编辑:Panda
邹忌曾经有一个问题:吾与徐公孰美?
而对于 REPA,也有一个类似的问题:全局信息空间结构,哪个对表征对齐更重要?
表征对齐(REPA)可通过将强大的预训练视觉编码器的表征蒸馏为中间扩散特征,来指导生成式训练。该方法于去年十月份问世,一直以来都备受关注,已成为加速扩散 Transformer(Diffusion Transformers)训练的一项有力技术。参阅报道《扩散模型训练方法一直错了!谢赛宁:Representation matters》。
但是,其还有一个很基本的问题悬而未决:对生成而言,目标表征的哪个方面更重要?是其「全局」语义信息(例如,以 ImageNet-1K 准确率衡量),还是其空间结构(即,图像块 token 之间的成对余弦相似度)?
此前,普遍观点认为,如果使用更强的全局语义性能作为目标表征,可以带来更好的生成效果。
为了研究这一点,Adobe Research、澳大利亚国立大学和纽约大学的一个联合团队对 27 种不同的视觉编码器和不同的模型规模进行了大规模的实证分析。
然后他们得到了一个出人意料的结果:驱动目标表征生成性能的是空间结构,而非全局性能!
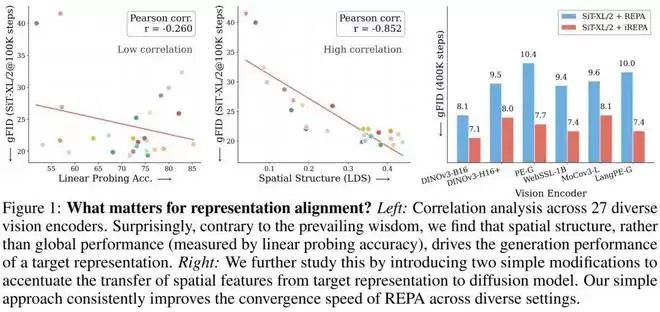
更令人惊讶的是,基于此发现,他们还构建了一种简单方法(代码实现少于 4 行),即iREPA,其能在各种视觉编码器、模型大小和训练变体(如 REPA、REPA-E、Meanflow、JiT 等)中持续提高 REPA 的收敛速度。

论文标题:What matters for Representation Alignment: Global Information or Spatial Structure?论文地址:https://arxiv.org/abs/2512.10794v1项目页面:https://end2end-diffusion.github.io/irepa/
本论文的第一作者是 Jaskirat Singh,澳大利亚国立大学二年级博士生,他在 Adobe 实习期间完成了此研究。目前也正在 Meta 实习。
此外,作者名单中还有多位万引大佬,包括 Adobe 资深研究科学家 Richard Zhang、Adobe 高级首席科学家 Eli Shechtman 以及我们熟悉的纽约大学谢赛宁。
下面我们来看看这项研究的具体内容。
反直觉的发现:全局强,不代表生成强
在深入探究之前,我们先来看几个令人费解的现象。
长期以来,研究人员通常假设:一个视觉编码器在 ImageNet-1K 上的分类准确率越高,它提取的特征就越好,用来指导扩散模型生成图像的效果也就应该越好。
然而,论文作者在测试了 27 种不同的编码器后,发现事实并非如此。
该团队举了几个非常有力的反例:
SAM2 的逆袭:分割模型 SAM2-S 的 ImageNet 准确率仅为 24.1%,这在分类任务上可以说表现平平。然而,当它被用作 REPA 的目标表征时,其生成的图像质量(FID 分数)竟然优于那些准确率比它高出 60% 的模型(如 PE-Core-G)。大模型的困境:在同一个模型家族中,更大的参数量通常意味着更高的分类准确率。但在表征对齐中,更大的模型(如 DINOv2-g)并不一定能带来更好的生成效果,有时甚至更差。画蛇添足的 CLS token:如果强行将包含全局信息的 [CLS] token 融合到图像块(patch)特征中,虽然线性探测(Linear Probing)准确率上升了,但生成质量(FID)却显著下降了。
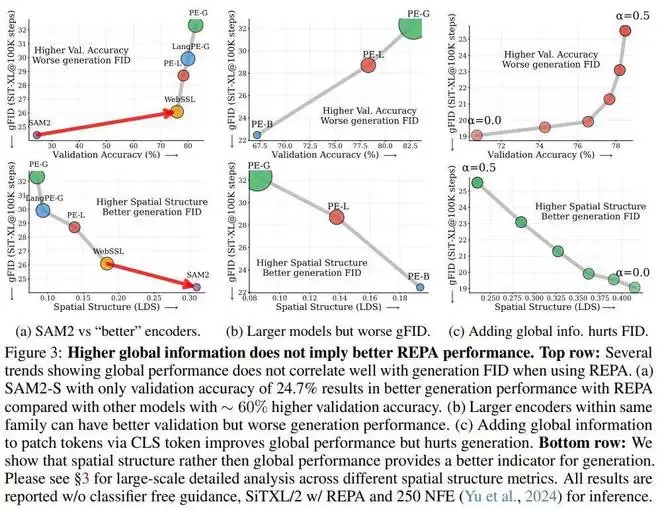
这些现象指向了一个结论:更高的验证准确率,并不意味着它是更好的生成表征。
真正的主宰:空间结构
如果不是全局语义信息在起作用,那究竟是什么在驱动生成性能?
作者提出假设:是空间结构,即图像块 token 之间的成对余弦相似度。
为了量化这一指标,作者引入了空间自相似性(Spatial Self-Similarity)的概念。简单来说,就是衡量特征图在空间上的「纹理」和「关系」是否清晰。作者使用了几种不同的度量标准,其中最直观的是LDS(Local vs. Distant Similarity):
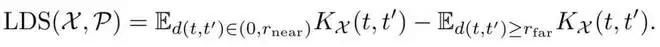
通俗点说,LDS 衡量的是:在特征空间中,相邻的图像块是否比相距较远的图像块更相似?如果一个编码器能很好地保留这种「近亲远疏」的空间结构,它的 LDS 分数就高。
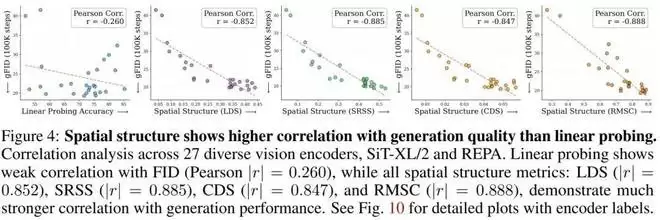
令人震惊的相关性出现了(如上图所示):传统的线性探测准确率(代表全局信息)与生成质量(FID)的相关性极低,皮尔逊相关系数仅为 r = -0.260。而空间结构指标(LDS) 与生成质量的相关性高达 |r| = 0.852!
这完美解释了之前的反例:SAM2 虽然不懂「这张图是猫」,但它极其擅长理解「猫的轮廓在哪里」,因此拥有极佳的空间结构,进而带来了出色的生成效果。
iREPA:不到 4 行代码的改进
既然明确了「空间结构」才是核心,那么与其盲目追求更强的语义编码器,不如想办法在训练过程中强化空间信息的传递。
基于此,该团队提出了iREPA。但其核心改动非常简单,代码实现甚至不到 4 行,主要包含两个修改:
1. 用卷积层替代 MLP 投影层
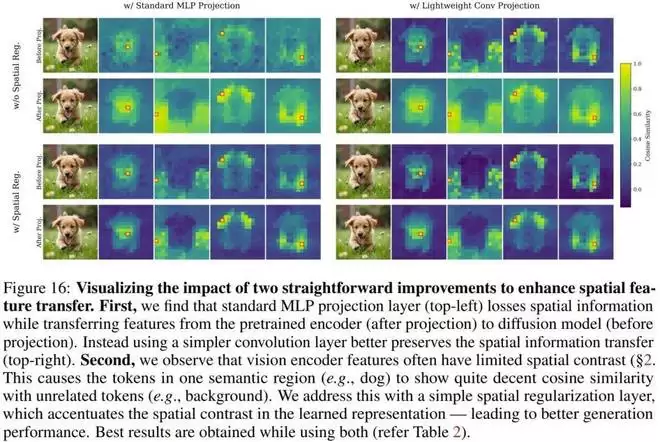
标准的 REPA 使用 MLP 将扩散模型的特征映射到目标表征的维度。作者指出,MLP 是「有损」的,会破坏 patch 之间的空间对比度。
其改进方法是:将其替换为一个简单的3×3 卷积层。卷积天然具有归纳偏置(Inductive Bias),能够更好地保留局部的空间关系。
2. 引入空间归一化层
作者发现,预训练视觉编码器的 patch token 中往往包含大量的全局信息(就像一层笼罩全图的「雾」),导致前景和背景的 token 居然有不低的相似度。
其改进方法是:既然这层全局均值信息对生成没用甚至有害,那就把它去掉。作者对目标表征引入了一个空间归一化(Spatial Normalization)层,减去均值,除以标准差。这牺牲了全局信息,但极大地增强了 patch 之间的空间对比度。
算法代码如下:

效果:提升显著
iREPA 的有效性并非仅停留在理论层面,作者通过一系列大规模实验,证明了这一改进方案具有极强的鲁棒性和通用性。
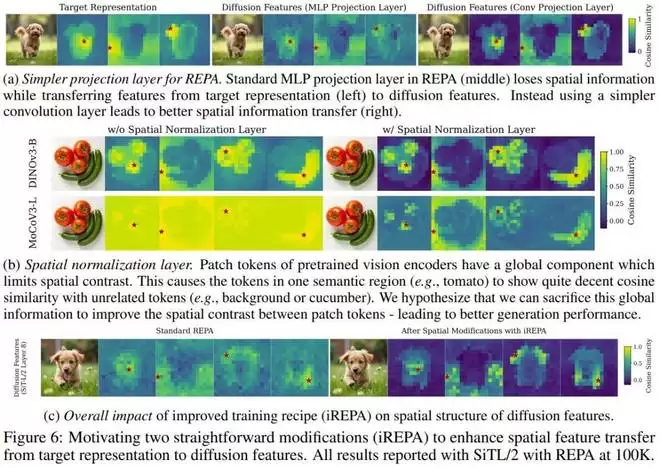
收敛速度更快
对于扩散 Transformer(如 SiT-XL/2)的训练而言,收敛速度就是金钱。实验结果表明,无论使用何种视觉编码器作为「教师」,iREPA 都能显著加速「学生」模型的训练收敛。
从下图可以看到,在各种模型规模(SiT-XL/2, SiT-B/2)和编码器(DINOv3, WebSSL, CLIP 等)下,iREPA 都显著提高了收敛速度 。
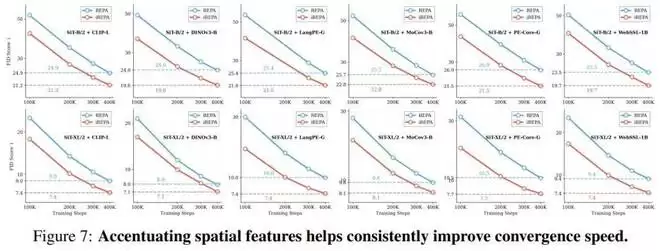
编码器通用性
通常一种优化方法可能只对特定类型的模型有效,但 iREPA 展现出了惊人的通用性。作者测试了多达 27 种不同的视觉编码器,涵盖了监督学习(如 DeiT)、自监督学习(如 DINOv2, MoCo v3, MAE)以及多模态模型(如 CLIP)。
如下图所示,在横跨所有测试的编码器中,iREPA(红色柱状图)的生成 FID 分数均低于标准 REPA(蓝色柱状图)。
可以看到,即使是像 SAM2 这样分类准确率极低(24.1%)的分割模型,在经过 iREPA 的空间增强处理后,其指导生成的 FID 分数甚至优于许多分类强模型。
同时,对于 DINOv3 和 WebSSL 等目前最强的特征提取器,iREPA 依然能进一步压低 FID,提升生成上限。
扩展性:模型越大,收益越高
这是一个非常符合「Scaling Law」趋势的发现。作者探究了 iREPA 在不同规模模型上的表现:
编码器规模:当视觉编码器从 PE-B (90M) 增大到 PE-G (1.88B) 时,iREPA 带来的性能提升百分比也随之增加(从 22.2% 提升至 39.6%)。扩散模型规模:当生成模型从 SiT-B (130M) 扩展到 SiT-XL (675M) 时,iREPA 带来的相对增益同样在扩大。这意味着,模型做得越大,空间结构的重要性就越显著,iREPA 的价值也就越高

广泛适用性
iREPA 并不仅限于特定的 Transformer 架构,它能无缝集成到各种现有的先进训练流中.
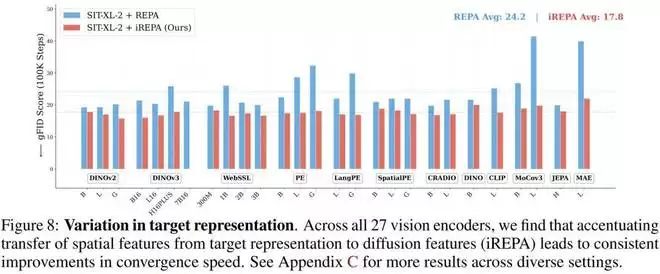
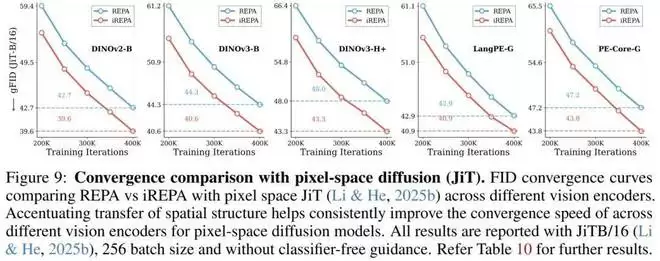
像素空间扩散 (Pixel-space Diffusion):在下图中,作者展示了将 iREPA 应用于 JiT (Just-in-Time) 模型的结果。即使在像素空间操作,强化空间信息传递依然能显著加速收敛.
先进配方兼容: 如下表所示,当结合 REPA-E(一种端到端调优 VAE 的方法)或 MeanFlow 等最新技术时,iREPA 依然能稳定地提供额外的性能增益。这说明它触及了生成模型训练的一个底层共性问题,而非仅仅是某种特定设置下的特例。
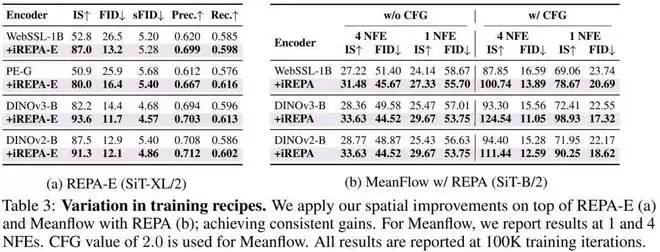
视觉质量有肉眼可见的结构改善
除了枯燥的数据,生成的图像本身最有说服力。
如下图所示,对比标准 REPA 和 iREPA 生成的样本(如鱼、公鸡、猫等类别),可以发现 iREPA 生成的图像在物体轮廓、纹理细节和整体结构的连贯性上都要优于前者。

而在下图中,作者可视化了经过卷积投影和空间归一化后的特征图。可以看到,通过 iREPA 处理后,特征图(右侧)明显比标准 REPA(左侧)保留了更清晰的语义边界和空间对比度,前景与背景的区分更加鲜明。
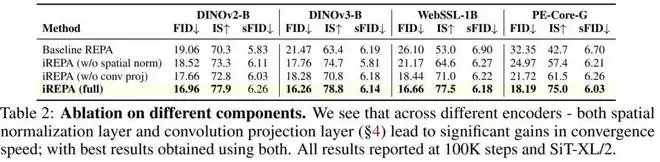
该团队也进行了消融实验,验证了各组件的有效性。
结语
这篇论文与其说是提出了一种新方法,不如说是通过扎实的实证分析,拨正了社区的关注点。它告诉我们,在利用预训练模型加速生成任务时,不要被「ImageNet 准确率」这一单一指标所迷惑。
对于生成模型而言,理解像素之间的空间关系,远比知道「这图里有只狗」要重要得多。正如作者在文中总结的那样:Spatial structure not global information determines the generation performance.
更多详情请访问原论文。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Harness Engineering 团队的核心职责与工作重点解析
在开发AI智能体或进行AI编程时,许多开发者都遇到过类似的困境:当你为大语言模型设计了一个包含多步骤的复杂任务链时,前期进展可能非常顺利,让你感觉胜券在握。 然而现实往往充满挑战。随着任务推进到中后期,模型的输出行为可能逐渐偏离预期——生成内容开始出现事实性错误,返回的数据结构悄然发生格式偏移,最终

Kimi 2.6 发布 性能对标Opus 4.6 刷新开源编程模型上限
月之暗面正式上线并开源了新一代模型 Kimi K2 6。从最新公布的基准测试成绩来看,其代码能力已经追平甚至超越了GPT-5 4和Opus-4 6,表现相当亮眼。当然,与A厂最新发布的Mythos和Opus-4 7相比,仍存在一定差距。我们先来看一张开源与闭源模型的整体对比图,以便有个直观的印象。

爱奇艺AI艺人库功能详解与最新回应
2026年4月21日 今天这张工业机器人概念图,信息量极为丰富。画面中,形态各异的机器人主体与背景的工业设施、管线共同构成了一幅“技术交汇快照”,精准反映了当前工业自动化与智能制造领域的核心发展趋势。 位于视觉中心的机械臂,其精密的关节构造与独特的末端执行器设计,明确指向高精度装配与柔性抓取应用。这

CodeBuddy前端Tree Shaking优化指南:精准分析import打包体积膨胀
前端项目打包体积膨胀常因不当的import语句导致TreeShaking失效。CodeBuddy工具通过解析源码,能识别高风险导入模式,如全量导入或动态访问。它可生成依赖引用图谱,评估模块引用饱和度,并自动推荐ES模块替代方案。此外,该工具会检查sideEffects字段的合规性,并审计构建配置,确保TreeShaking优化条件完备,从而精准定位并解决打包

奥迪与上汽深化合作 L3自动驾驶将首搭E7X车型
在备受瞩目的大众集团之夜活动上,奥迪全球CEO高德诺(Gernot Döllner)正式宣布了一项战略级规划:奥迪将在全新纯电车型E7X上,全球首搭L3级高阶自动驾驶系统。此举不仅是奥迪在智能驾驶领域的一次重磅技术落地,更标志着其正将深厚的豪华造车底蕴,与中国本土领先的智能科技力量深度融合,从而为豪








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
