




浪潮信息刘军:AI产业盈利难,1元/百万Token成本仍不足

来源:美通社
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
北京2025年12月25日 /美通社/ -- 当前全球AI产业已从模型性能竞赛迈入智能体规模化落地的"生死竞速"阶段,"降本" 不再是可选优化项,而是决定AI企业能否盈利、行业能否突破的核心命脉。在此大背景下,浪潮信息推出元脑HC1000超扩展AI服务器,将推理成本首次击穿至1元/每百万token。这一突破不仅有望打通智能体产业化落地"最后一公里"的成本障碍,更将重塑AI产业竞争的底层逻辑。
浪潮信息首席AI战略官刘军强调,当前1元/每百万token的成本突破仅是阶段性胜利,面对未来token消耗量指数级增长、复杂任务token需求激增数十倍的必然趋势,现有成本水平仍难支撑AI的普惠落地。未来,AI要真正成为如同 "水电煤" 般的基础资源,token成本必须在现有基础上实现数量级跨越,成本能力将从"核心竞争力"进一步升级为"生存入场券",直接决定AI企业在智能体时代的生死存亡。

智能体时代,token成本就是竞争力
回顾互联网发展史,基础设施的"提速降费"是行业繁荣的重要基石。从拨号上网以Kb计费,到光纤入户后百兆带宽成为标配,再到4G/5G时代数据流量成本趋近于零——每一次通信成本的显著降低,都推动了如视频流媒体、移动支付等全新应用生态的爆发。
当前的AI时代也处于相似的临界点,当技术进步促使token单价下滑之后,企业得以大规模地将AI应用于更复杂、更耗能的场景,如从早期的简短问答,到如今支持超长上下文、具备多步规划与反思能力的智能体……这也导致单任务对token的需求已呈指数级增长。如果token成本下降的速度跟不上消耗量的指数增长,企业将面临更高的费用投入。这昭示着经济学中著名的"杰文斯悖论"正在token经济中完美重演。
来自多方的数据也有力佐证了token消耗量的指数级增长趋势。火山引擎最新披露的数据显示,截至今年12月,字节跳动旗下豆包大模型日均token使用量突破50万亿,较去年同期增长超过10倍,相比2024年5月刚推出时的日均调用量增长达417倍;谷歌在10月披露,其各平台每月处理的token用量已达1300万亿,相当于日均43.3万亿,而一年前月均仅为9.7万亿。
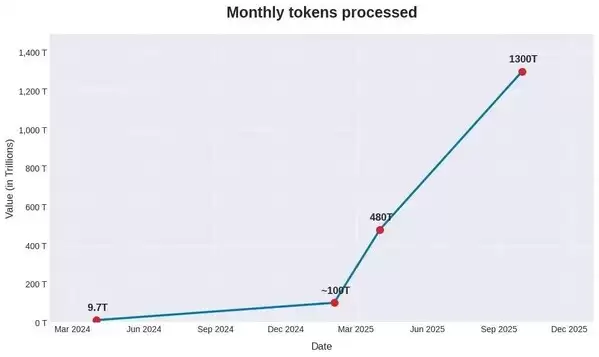
当使用量达到"百万亿token/月"的量级时,哪怕每百万token成本只下降1美元,也可能带来每月1亿美元的成本差异。刘军认为:"token成本就是竞争力,它直接决定了智能体的盈利能力。要让AI真正进入规模化普惠阶段,token成本必须在现有基础上继续实现数量级的下降。"
深挖token成本"暗箱":架构不匹配是核心瓶颈
当下,全球大模型竞赛从"盲目堆算力"转向"追求单位算力产出价值"的新阶段。单位算力产出价值受到能源价格、硬件采购成本、算法优化、运营成本等多种因素的影响,但不可否认的是,现阶段token成本80%以上依然来自算力支出,而阻碍成本下降的核心矛盾,在于推理负载与训练负载截然不同,沿用旧架构会导致算力、显存与网络资源难以同时最优,造成严重的"高配低效"。
一是算力利用率(MFU)的严重倒挂。训练阶段MFU可达50%以上,但在推理阶段,特别是对于追求低延迟的实时交互任务,由于token的自回归解码特性,在每一轮计算中,硬件必须加载全部的模型参数,却只为了计算一个token的输出,导致昂贵的GPU大部分时间在等待数据搬运,实际MFU往往仅为5%-10%。这种巨大的算力闲置是成本高企的结构性根源。
二是"存储墙"瓶颈在推理场景下被放大。在大模型推理中,随着上下文长度的增加,KV Cache呈指数级增长。这不仅占用了大量的显存空间,还导致了由于访存密集带来的高功耗。这种存算分离不仅带来数据迁移功耗和延迟,还必须配合使用价格高昂的HBM,已经成为阻碍token成本下降的重要瓶颈。
三是网络通信与横向扩展代价愈发高昂。当模型规模突破单机承载能力时,跨节点通信成为新瓶颈。传统RoCE或InfiniBand网络的延迟远高于芯片内部的总线延迟,通信开销可能占据总推理时间的30%以上,导致企业被迫通过堆砌更多资源来维持响应速度,推高了总拥有成本(TCO)。
对此,刘军指出,降低token成本的核心不是"把一台机器做得更全",而是围绕目标重构系统:把推理流程拆得更细,支持P/D分离、A/F分离、KV并行、细粒度专家拆分等计算策略,让不同计算模块在不同卡上按需配置并发,把每张卡的负载打满,让"卡时成本"更低、让"卡时产出"更高。
基于全新超扩展架构,元脑HC1000实现推理成本首次击破1元/每百万token
当前主流大模型的token成本依然高昂。以输出百万token为例,Claude、Grok等模型的价格普遍在10-15美元,国内大模型虽然相对便宜,也多在10元以上。在天文数字级别的调用量下,如此高的token成本让大规模商业化应用面临严峻的ROI挑战。要打破成本僵局,必须从计算架构层面进行根本性重构,从而大幅提升单位算力的产出效率。
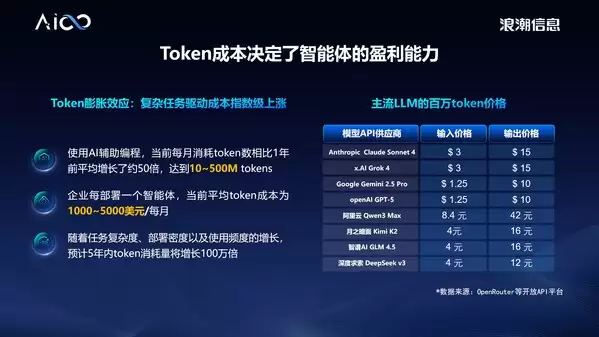
为此,浪潮信息推出元脑HC1000超扩展AI服务器。该产品基于全新设计的全对称DirectCom极速架构,采用无损超扩展设计,可高效聚合海量本土AI芯片,支持极大推理吞吐量,推理成本首次击破1元/每百万token,为智能体突破token成本瓶颈提供极致性能的创新算力系统。

刘军表示:"我们看到原来的AI计算是瞄着大而全去建设的,五脏俱全,各种各样的东西都在里面。但是当我们聚焦降低token成本这一核心目标之后,我们重新思考系统架构设计,找到系统瓶颈,重构出一个极简设计的系统。"
元脑HC1000创新设计了DirectCom极速架构,每计算模组配置16颗AIPU,采用直达通信设计,解决传统架构的协议转换和带宽争抢问题,实现超低延迟;计算通信1:1均衡配比,实现全局无阻塞通信;全对称的系统拓扑设计,可以支持灵活的PD分离、AF分离方案,按需配置计算实例,最大化资源利用率。

同时,元脑HC1000支持超大规模无损扩展,DirectCom架构保障了计算和通信均衡,通过算网深度协同、全域无损技术实现推理性能1.75倍提升,并且通过对大模型的计算流程细分和模型结构解耦,实现计算负载的灵活按需配比,单卡MFU最高可提升5.7倍。
此外,元脑HC1000通过自适应路由和智能拥塞控制算法,提供数据包级动态负载均衡,实现KV Cache传输和All to All通信流量的智能调度,将KV Cache传输对Prefill、Decode计算实例影响降低5-10倍。
刘军强调,当前"1元/每百万token"还远远不够,面对未来token消耗量的指数级增长,若要实现单token成本的持续、数量级下降,需要推动计算架构的根本性革新。这也要求整个AI产业的产品技术创新,要从当前的规模导向转为效率导向,从根本上重新思考和设计AI计算系统,发展AI专用计算架构,探索开发大模型芯片,推动算法硬件化的专用计算架构创新,实现软硬件深度优化,这将是未来的发展方向。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

湖南金证解读人形机器人产业如何借赛事机遇加速发展
备受瞩目的人形机器人专项赛事即将拉开帷幕。与往届相比,本届赛事在竞赛路线与赛制规则上均实现了全面升级,其中尤为关键的是增设了自主导航这一核心竞赛单元。此举不仅显著提升了测试标准与技术门槛,更标志着赛事性质正从单纯的竞技比拼,演进为行业前沿关键技术成果的权威验证平台。对于资本市场而言,这无疑是一个重要

联发科全域智能体化体验如何实现服务找人
上半年科技界最受瞩目的行业盛会——天玑开发者大会2026(MDDC 2026)圆满收官。纵观全程,一个明确的趋势已然清晰:AI体验的下一阶段,早已超越了在手机中内置语音助手或为App接入大模型API的简单模式。真正的变革在于,智能体(Agent)正在全面渗透各类终端与系统,无声地融入我们日常生活的每

宝马新任董事长聂科维博士接棒齐普策引领集团战略转型
宝马集团监事会近日宣布了一项重要高层人事变动:原董事会主席齐普策先生成功完成七年任期,其职位将由聂科维博士正式接任。在过去的七年中,齐普策先生成功领导了宝马集团的战略转型进程,即便面对全球疫情等严峻挑战,依然为集团的长期可持续发展奠定了坚实基础。监事会主席彼得博士对此高度认可:“齐普策先生以卓越的战

红旗H7插电混动版下半年上市 多款续航版本瞄准中高端市场
备受期待的全新红旗H7正式亮相于最新一批免征车辆购置税的新能源汽车车型目录,并确认将于今年下半年推向市场。新车最大的亮点在于其搭载的全新1 5T插电式混合动力系统,为消费者提供了高效节能的新选择。 在核心动力配置上,全新红旗H7采用高效的1 5T涡轮增压发动机与电动机组成的插电混动系统。其中,发动机

小米耳夹式耳机本月发布 首款外观设计正式亮相
小米音频生态迎来重要新成员!5月14日,小米官方正式宣布,旗下首款耳夹式耳机将于本月发布。这款名为“小米耳夹式耳机”的新品,主打开放式佩戴体验,标志着小米在入耳式、半入耳式及挂耳式耳机产品线之外,正式进军耳夹式耳机这一热门细分市场。 小米 从官方预热海报可以看出,这款耳夹式耳机在设计上颇具匠心。其采








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
