




GeoVLA框架重构机器人空间感知,突破2D视觉局限



论文名称: GeoVLA: Empowering 3D Representation in Vision-Language-Action Models
在具身智能的浪潮中,VLA 模型被视为通往通用机器人的快车道。然而,随着研究深入到非结构化环境,现有 VLA 模型面临着一个严重的维度缺陷:空间失明。
目前,大多数 VLA 模型(比如 OpenVLA、RT-2、Pi0、Pi05)单纯依赖 2D RGB 图像作为视觉输入,导致模型眼中的世界“纸片化”,严重缺乏深度信息和几何先验;由此带来的后果是:
深度感知缺失:面对需要精确距离判断的任务,比如精准投篮、挂扣环,2D 模型往往“抓瞎”,无法准确预测 Z 轴的动作。
空间适应性差:一旦物体尺寸发生变化(Scale Variance)或相机视角发生偏移(Viewpoint Shift),便无法理解物体在空间中的本质位置,导致任务失败。
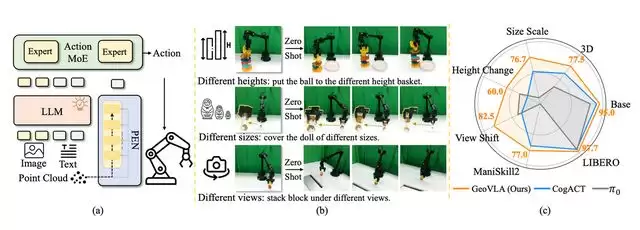
图 1:GeoVLA 整体示意图
Dexmal 原力灵机作者团队提出一种全新的 VLA 框架 GeoVLA,它在保留现有视觉-语言模型(VLM)的预训练能力的同时,采用了一种优雅的双流架构(Dual-path Architecture)。
具体而言,GeoVLA 在保留 VLM 强大的语义理解能力的同时,引入专用的点云嵌入网络 PEN 和空间感知动作专家 3DAE,直接利用深度图生成的点云数据,赋予机器人真正的三维几何感知能力。
这一设计不仅在仿真环境中取得 SOTA,更在真实世界的鲁棒性测试中,特别是在视角改变和物体尺度变化的极端条件下,展现出惊人的适应力。
方法框架
常见的做法试图让一个 VLM 既懂语义又懂几何,这往往顾此失彼;GeoVLA 的核心逻辑是选择把任务解耦:让 VLM 负责“看懂是什么”,让点云网络负责“看清在哪里”。
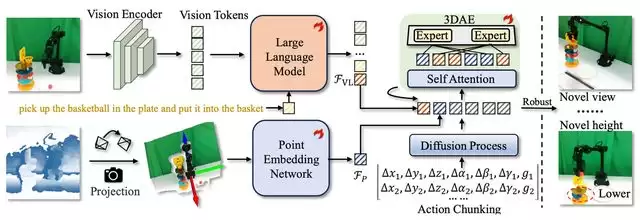
图2:GeoVLA 框架图
GeoVLA 是一个全新的端到端框架,其流程包含三个关键组件的协同工作:
语义理解流:利用预训练的 VLM(如 Prismatic-7B)处理 RGB 图像和语言指令,提取融合后的视觉-语言特征。
几何感知流:利用点云嵌入网络 PEN 处理由深度图转换而来的点云,独立提取高精度的 3D 几何特征。
动作生成流:通过3D 增强动作专家 3DAE 融合上述两种特征,生成精确的动作序列。
点云嵌入网络 PEN
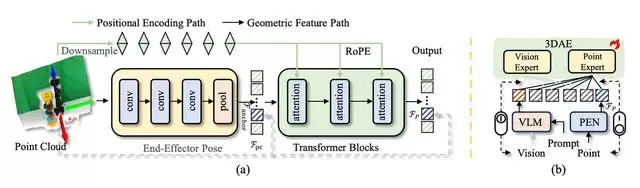
图 3:双路径点云嵌入网络细节图
原始深度图往往包含大量噪声,且数据稀疏,直接作为输入效果不佳。点云嵌入网络 PEN 专为机器人操作设计,采用双路径架构来提取干净且紧凑的几何特征:
几何特征提取:使用大核卷积和局部池化的轻量级 CNN,将非结构化的点云编码为 Patch 级别的几何 Token。
空间位置编码:引入在大语言模型中常见的旋转位置编码 RoPE,它能极好地保留 3D 空间中的相对位置信息,这对于操作任务至关重要。
空间锚点(Spatial Anchor)设计是 PEN 的一大亮点。作者团队并没有简单地对所有点云特征进行平均池化,而是选择对应于末端执行器坐标原点的 Token 作为“锚点”。这种以“手”为中心的视角设计,让模型能够显式地建模“手”与“物体”之间的几何关系,大幅提升操作精度。
3D 增强动作专家 3DAE
特征提取只是第一步,如何有效融合 RGB 的语义信息和点云的几何信息,实现1+1>2的效果,是多模态研究当中的难点。作者团队在动作生成端采用基于扩散 Transformer (DiTs) 的架构,并创新性地引入混合专家 (MoE) 机制。
静态路由策略 (Static Routing):这是一个直觉且有效的策略。在训练过程中,由于 VLM 分支是预训练的,而点云分支是从头开始学,如果使用常规的动态路由,模型会倾向于走捷径,只依赖 VLM 分支,忽略点云信息。
强制解耦:作者团队采用了静态路由,随机丢弃某种模态,逼迫模型必须学会独立利用几何信息来解决问题,从而确保了双流信息的有效融合。
实验结果
GeoVLA 在仿真和真机实验中均展现出对传统 2D VLA 模型的压倒性优势,证明显式 3D 表征在复杂操作中的不可替代性。
仿真环境测试结果
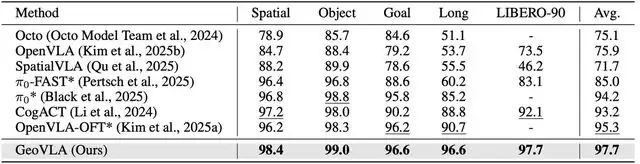
表 1:LIBERO 评测结果
在 LIBERO 基准测试中,GeoVLA 超越所有任务套件。在最具挑战性的 LIBERO-90(长程多任务)中,GeoVLA 达到 97.7% 的成功率,超越之前的 SOTA 方法 OpenVLA-OFT (95.3%) 和 CogACT (93.2%)。

表 2:ManiSkill2 评测结果
在物理仿真更为逼真的 ManiSkill2 中,GeoVLA 优势更加明显,平均成功率达到 77%,大幅领先 Dita (66%) 和 CogACT (69%);特别是在 PickClutterYCB 这种物体堆叠杂乱、遮挡严重的任务中,GeoVLA 凭借点云带来的几何理解,保持了极高的操作精度。
真机环境与鲁棒性测试

图 4:真机实验任务的变体展示
作者团队使用 WidowX-250s 机械臂进行了广泛的真机测试;实验被分为“基础任务”和“3D 感知任务”。在域内任务中,GeoVLA 在基础任务上平均成功率 95.0%,在 3D 感知任务上为 77.5%,总体平均 86.3%,大幅领先 Pi0 (57.5%) 和 CogACT (76.3%)。特别是在 Put Basketball 和 Put Hairclip 等需要精确空间理解的任务中,GeoVLA 表现出更好的鲁棒性。

表 4:真机任务评测结果
更令人印象深刻的是 GeoVLA 在分布外(OOD)场景下的鲁棒性,这也是 GeoVLA 最核心的突破点:

表 5(左):投篮任务变体的评测结果;表 6(右):套娃任务变体的评测结果
投篮任务变体(高度变化):当篮筐高度被调整到训练数据未覆盖的最高位置 (H1) 时,依赖 2D 视觉的 CogACT 和 Pi0 彻底失效,成功率降至 20%;而 GeoVLA 凭借点云信息,依然保持 60% 的成功率。
套娃任务变体(尺寸变化):面对比训练时大一号的套娃,2D 模型往往因为像素特征不匹配而无法识别;GeoVLA 则通过几何形状匹配,保持了 80% 的高成功率。
堆叠积木任务变体(视角变化):堆叠积木时,当相机视角偏移 45°,CogACT 成功率直接归零,说明 2D 模型极度依赖特定视角的像素记忆;而 GeoVLA 依然稳健,保持 70% 的成功率,证明其学到了真正的 3D 空间结构。
胡萝卜任务变体(移除海绵垫):训练时使用的海绵垫在推理阶段被移除,胡萝卜位置被降低,导致大多数方法抓取胡萝卜失败;GeoVLA 则能更稳定且成功抓取,展现出更强的泛化能力。
结论

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

北京科博会汇聚800余家企业 展示太空大脑与医疗探针等硬核科技
从刺破苍穹的“太空大脑”,到精准导航人体的“医疗探针”,再到身临其境的“VR巨幕”……第二十八届中国北京国际科技产业博览会(简称“北京科博会”),已然成为一场硬核科技的“阅兵式”。超过800家中外顶尖企业与科研机构携核心成果汇聚于此,共同描绘了一幅从探索宇宙到守护健康的科技创新全景图,集中展现了中国

无意识状态下大脑能否理解他人话语
躺在手术台上,当麻醉师告诉你“睡一觉就好了”的时候,你大概会认为大脑也随之“关机”了。毕竟,醒来后你确实对手术过程一无所知。但“不知道”就等于“没发生”吗?一项最新的研究给出了碘伏性的答案:即便在深度麻醉的无意识状态下,你的大脑,尤其是海马体,可能仍在暗中处理着复杂的信息。 2026年5月,《自然》

许哲诚计算性设计展演评析:数字逻辑与物质建构的生成境域
数字逻辑与物质建构的深度对话 ——评许哲诚“境域·生成”计算性设计展演 □ 丁雅力(江苏省美术馆策展人) 当代设计与造物的核心范式,正经历着由计算性设计带来的深刻变革。2026年3月20日,南京艺术学院教师许哲诚于南京莫玄空间呈现的“境域·生成”个人专场展演,正是这一前沿趋势的集中体现。本次展览超越

2027款宝马i7 M70实车亮相 旗舰纯电轿车迎来全面升级
近日,汽车媒体BMW Blog曝光了一组2027款宝马i7 M70的实车照片,迅速引发了车迷与行业的高度关注。宝马集团CEO奥利弗·齐普策将此次中期改款定义为品牌史上“规模最大的车型改款”,从已披露的视觉信息来看,其改动幅度之大,确实堪比一次全新换代。 这款已于四月底正式亮相的新车,前脸设计采用了近

蔚来回应被约谈传闻称消息不实
近期,部分车企因“锁电”问题引发消费者集中投诉的事件有了新的监管动态。据相关报道,已有8家车企因此被监管部门约谈,其中3家因涉嫌违规操作被正式立案调查。尽管官方尚未公布具体涉事企业名单,但关于“哪8家车企被约谈”的讨论与猜测已在网络平台持续发酵。 针对网络流传的各类信息,多家涉事车企迅速作出官方回应








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
