




华人领衔AI突破!复刻AlphaZero,Meta研究甩开人类自修成神

新智元报道编辑:元宇 好困【新智元导读】当模型学会「左右互搏」的那一刻,平庸的模仿时代结束了,真正的硅基编程奇迹刚刚开始。编程界的AlphaZero时刻,终于来了?当年,AlphaZero抛弃人类棋

新智元报道
编辑:元宇 好困
【新智元导读】当模型学会「左右互搏」的那一刻,平庸的模仿时代结束了,真正的硅基编程奇迹刚刚开始。
编程界的AlphaZero时刻,终于来了?
当年,AlphaZero抛弃人类棋谱,仅凭「左右互搏」便参透了超越千年的棋道。
而今天,AI程序员的致命伤,恰恰就在于它们太像「人」了——
靠学习人类代码长大的AI,注定无法突破人类的平庸。
就在最近,来自Meta、UIUC和CMU的研究团队,凭借最新成果Self-play SWE-RL(SSR),正在试图复刻AlphaZero的神话——
抛弃人类教师,拒绝模仿。

论文地址:https://arxiv.org/pdf/2512.18552
只要给AI一个代码库,让它分饰「破坏者」与「修复者」进行死斗。
在这场无需人类插手的自我博弈中,一种真正的、超越人类经验的编程奇迹,正在诞生。

被「喂养」的AI与人类数据的天花板
从Devin到OpenDevin,再到各大厂内部的代码助手,它们确实能帮程序员干不少脏活累活。
但这里有一个隐形的瓶颈。
目前主流的训练方法,无论是SWE-RL还是DeepSWE,本质上都是在教AI「模仿」。
这种依赖人类知识的模式有三个致命伤:
数据不够用:高质量的、带测试用例、带详细描述的Bug修复数据,其实非常稀缺。
质量不可靠:人类写的issue经常含糊不清,测试用例也不一定完美,这导致训练信号充满了噪声。
天花板太低:如果AI只是模仿人类,它顶多变成一个平庸的初级程序员。
这也是为什么论文把它称作通向超级智能的一道根本性障碍:
一旦训练信号必须由人类提供,你就很难想象它能无限扩展到「开放式、自我进化」的层级。
核心玩法
代码沙盒里的「搏击俱乐部」
SSR的核心理念非常简单,却又极其精妙:自博弈(Self-Play)。
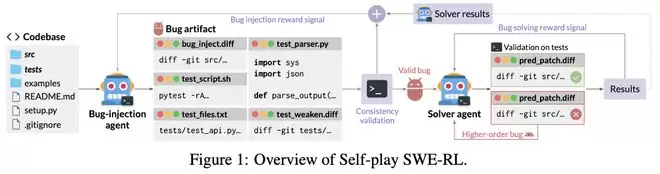
在这个系统中,同一个LLM被赋予了两个截然不同、相互对抗的角色。
角色一
破坏者(Bug注入智能体)
它的任务不是写代码,而是搞破坏。
给它一个正常的开源项目(比如一个Python库),它需要潜入进去,研究代码逻辑,然后制造一个Bug。
但这个破坏者不能随便乱来(比如删掉所有文件),它需要生成一套完整的「作案工具包」(Artifacts):
bug_inject.diff :这是真正的破坏补丁,把代码改坏。
test_script.sh :一个能运行测试的脚本,证明Bug确实存在。
test_files.txt :指定哪些测试文件是用来验证这个Bug的。
test_parser.py :一个解析器,用来把测试结果翻译成机器能读懂的JSON格式。
test_weaken.diff :它会修改或删除现有的测试用例,让Bug在当前的测试套件下不报错。

在SSR中,缺陷生成是一项由破坏者智能体执行的任务,该智能体利用工具与执行环境交互以生成缺陷工件,并进一步验证其一致性后提供给修复者智能体。
一个优秀的破坏者智能体的关键特性在于其能够生成多样化的缺陷,以捕捉真实软件开发中的复杂性,从而在广泛的软件调试与工程场景中训练修复者智能体。

角色二
修复者(Bug解决智能体)
当破坏者完成工作后,轮到修复者登场了。
修复者面对的是一个被注入了Bug,且测试被「弱化」了的代码库。

修复者拿到的任务非常具有挑战性,它看不到那个原始的Bug是怎么注入的,它必须像一个侦探一样,通过阅读代码、运行测试、分析报错,最终写出一个修复补丁(Fix Patch)。

通过破坏者和修复者两种模型角色的对抗,可以让模型实现闭环进化。
让魔法打败魔法
如何保证AI不「瞎编」?
如果你让AI随便生成Bug,它大概率会产生幻觉,为此SSR设计了一套如同安检般严格的一致性验证(Consistency Verification)流程。
一个合格的Bug工件,必须通过以下所有关卡:
存在性检查:引用的测试文件,原仓库要有;
解析器检查:Python解析器要能读懂测试输出;
脚本有效性:在没改坏代码之前,测试脚本要跑得通;
Bug范围控制:改动的文件数量要适当,符合设定的难度。
Bug有效性(关键):注入Bug后,原本通过的测试必须变失败。如果注入了Bug测试还通过,说明Bug根本没生效。
掩盖有效性:应用了「掩盖补丁」后,原本失败的测试必须变通过,证明成功欺骗了测试套件。
最精彩的一招
逆向变异测试
逆向变异测试(Inverse Mutation Testing),是一个为了验证Bug质量而发明的新概念。
传统的变异测试是改乱代码看测试能不能发现。
而逆向变异测试刚好反过来,把Bug涉及的文件逐个恢复成原样。
如果恢复某个文件后,失败的测试变通过了,说明这个文件确实是Bug的起因。
如果恢复了文件测试还是有问题,说明这个文件跟Bug没关系。
这一步确保了AI生成的每一个改动都是必要的。
如何制造一个「完美」的Bug?
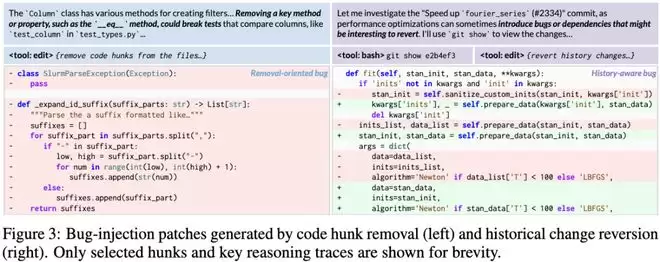
如果「破坏者」只是简单地把x=1改成x=0,那「修复者」学不到任何东西。
为了让AI变得更聪明,研究团队探索了几种极具创意的Bug注入策略。
策略A
直接注入(Direct Injection)
告诉AI:「去,搞个Bug出来」,这是最笨的方法。
结果不出所料,AI经常就在代码里随便改个数字或符号。
这种Bug太肤浅,修复者一眼就能看穿,训练效果最差。
策略B
暴力删除(Removal-only)
告诉AI:「把这块核心功能的代码删了!」
这逼迫修复者必须根据上下文和剩余的测试代码,重新实现这部分功能。
如此一来,能极大地锻炼AI的代码重构和理解能力。
策略C
历史回滚(History Rollback)
告诉AI:「去翻翻以前的提交记录,把代码回滚到某个旧版本。」
因为代码库的历史往往充满了真实的Bug和功能的演进。
让AI面对过去的代码状态,相当于让它重新经历一次项目演化的过程。这种生成的Bug最自然,最具实战意义。
实验证明,「删除策略」和「历史回滚」混合使用,效果最好。这既保证了难度,又保证了真实性。
终极杀招
高阶Bug
如果修复者尝试修复Bug但失败了,SSR认为这也可以「废物再回收利用」。
修复者失败的代码,往往是一个半成品——它可能修好了一部分,但引入了新问题。这不就是一个更复杂、更隐蔽的Bug吗?
系统会将这个「失败的修复」作为新的Bug状态,再次扔给修复者。
这种多轮次、分层级的故障模式,极大地丰富了训练数据的维度。
残酷的奖励机制与对抗博弈
在强化学习中,奖励函数是指挥棒。
SSR的奖励设计充满了一种「微妙的平衡感」。

对于修复者,奖励很简单:全对得+1分,否则-1分。成王败寇。
但对于破坏者,这就很有趣了。
如果破坏者生成的Bug太简单,修复者每次都能修好(解决率s=1),破坏者得不到高分。
如果Bug太难,根本修不好(解决率s=0),破坏者会被惩罚(因为它可能生成了逻辑矛盾的死局)。
SSR采用了一个基于解决率s的公式:
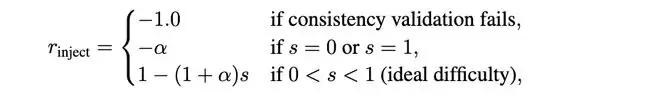
其中,s∈[0,1]是解决率(solver成功修复bug的比例),α∈(0,1)是一个超参数,用于控制对退化解决率的惩罚强度,在实验中设置为0.8。
它的意思是:最好的Bug,是那些让修复者感到棘手、通过率不高不低、处于「能力边界」上的Bug。
这迫使破坏者不断提升难度,正好卡在修复者「跳一跳够得着」的地方,从而推动双方共同进化。
战果揭晓
AI真的变强了吗?
研究团队使用了Code World Model(CWM)的32B模型作为底座,在512个H100 GPU上进行了训练。
他们在两个权威榜单上进行了测试:
SWE-bench Verified:经过人工验证的真实GitHub issue集合。
SWE-Bench Pro:更复杂、更企业级的问题集合。
竞争对手是基于同样模型架构、同样环境镜像,但使用「人类数据」(Human Data)训练出来的基准模型。
所谓人类数据基准,就是用传统的「Issue描述+测试用例」方式训练的。
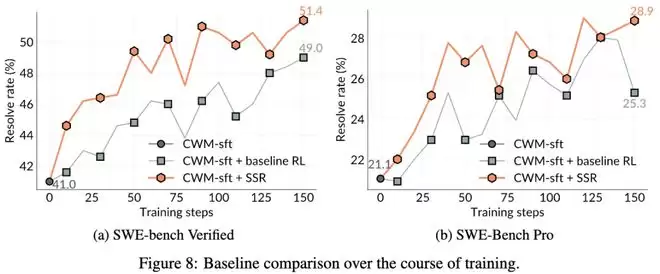
结果令人振奋:
SSR完胜:在整个训练轨迹中,SSR的表现始终高于「人类数据」基准。
分数提升:在SWE-bench Verified上提升了10.4%,在SWE-Bench Pro上提升了7.8%。
零样本泛化:SSR在训练时从未见过任何自然语言描述的Issue,它只看过代码和测试。但在测试时,它却能完美处理带有Issue描述的任务。这说明它学到的不是「做题技巧」,而是真正的「编程内功」。
测试结果显示,随着训练步数的增加,SSR的能力稳步上升,而没有出现过拟合或崩溃,证明了自博弈产生的「课程」是持续有效的。
通向超级智能的最后一块拼图
SSR的出现,意味着我们终于找到了一条摆脱「数据饥渴」的路径。
以前我们认为,要想AI写好代码,必须有无数的人类程序员贡献代码和修Bug的记录。
现在SSR告诉我们:只要有代码库(Raw Code)就够了。
当然,SSR还只是第一步。
它目前的验证还主要依赖单元测试,还没法处理那种跨越数月的大型重构任务。
但它指明了方向:
超智能软件系统的诞生,可能不需要人类作为老师,只需要人类的代码作为战场。
作者简介
Yuxiang Wei

Yuxiang Wei
Yuxiang Wei是伊利诺伊大学厄巴纳-香槟分校(UIUC)计算机科学系的博士生,由Lingming Zhang教授指导。
他同时在Meta FAIR担任兼职研究员,与Sida Wang、Daniel Fried等人合作,致力于推进大型语言模型(LLM)在代码智能方面的应用。
Zhiqing Sun

Zhiqing Sun
Zhiqing Sun是Meta超级智能实验室(MSL)TBD Lab的AI研究科学家,专注于训练大型语言模型(LLM)用于深度研究、代理开发和复杂任务。
此前,他在OpenAI的后训练团队担任研究科学家,并曾在AllenNLP和MIT-IBM Watson AI Lab实习。
Zhiqing Sun于2025年2月在卡内基梅隆大学语言技术研究所获得计算机科学博士学位,并在北京大学获得计算机科学专业荣誉学士学位。
David Zhang

David Zhang
David Zhang是Meta基础AI研究(FAIR)巴黎实验室的研究科学家,专攻使用LLM的代码生成机器学习和深度学习技术。
David Zhang拥有阿姆斯特丹大学机器学习博士学位、慕尼黑工业大学计算机科学硕士和学士学位。
Lingming Zhang

Lingming Zhang
Lingming Zhang是伊利诺伊大学厄巴纳-香槟分校(UIUC)计算机科学系的副教授,隶属于Grainger工程学院。
他的研究融合软件工程、编程语言、形式方法和机器学习,重点关注基于LLM的软件测试、分析、修复和合成。
Sida Wang

Sida Wang
Sida Wang是Meta基础AI研究(FAIR)西雅图实验室的研究科学家,专注于自然语言处理、机器学习和代码大型语言模型(LLM)。
此前,他在普林斯顿大学和高等研究院(IAS)担任研究讲师,并于2017年在斯坦福大学获得计算机科学博士学位(由Chris Manning和Percy Liang联合指导)。
他持有多伦多大学应用科学学士学位,曾在Geoffrey Hinton指导下研究胶囊网络。
参考资料:
https://x.com/YuxiangWei9/status/2003541373853524347%20
https://arxiv.org/abs/2512.18552
秒追ASI
⭐点赞、转发、在看一键三连⭐
点亮星标,锁定新智元极速推送!

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

长沙街头捷达三款展车亮相 共绘品牌焕新画卷
7月10日,捷达在长沙黄兴广场举办快闪活动,展出JETTAX概念车、纯电轿车捷达M6及VS8黑武士版三款车,将品牌焕新战略从概念转为可触达的互动体验,展现油电并行布局与年轻化转型。

吉利银河TT硬刚小米SU7,20万内平替性能车
吉利银河TTUltra全球竞速版定位高性能纯电街车,双电机四驱,综合功率四百二十五千瓦,零百加速三点八秒,尺寸与小米SU7Max接近,预计售价二十万以内,较SU7Max便宜约十万元,旨在争夺新能源性能车市场话语权。

迈凯伦788HS限量200台720S车系终极绝唱性能空力巅峰
迈凯伦788HS限量200台,作为720S车系终极版本,搭载4 0升双涡轮增压V8发动机,最大功率788马力,干重1265千克,推重比每吨623马力。0-100公里 小时加速2 8秒,0-200公里 小时缩短至7 0秒,极速330公里 小时。空气动力学性能提升,下压力比765LT高10%,配备定制碳纤维组件及塞纳同款碳陶刹车。

虎嗅作嗅之星周榜第321~322期
虎嗅第321-322期“作·嗅之星”周榜揭晓,获奖文章涵盖刷手机、性同意、面包倒闭等话题。榜单综合文章质量、内容热度、读者互动等维度,由算法计算得出,每篇上榜作品兼具内容与人气。

Meta发布Muse Spark 1.1多模态推理模型强化AI智能体任务能力
Meta发布MuseSpark1 1,专为AI智能体打造,强化多智能体协作与任务规划能力,支持百万token上下文,可执行代码开发、应用操作等长流程任务。安全评估通过,但部分性能仍落后于GPT-5 5和ClaudeOpus4 8。现已在MetaAIApp及API预览版上线。








- 热门数据榜



 相关攻略
相关攻略
 2026-07-12 12:41
2026-07-12 12:41
2026-07-12 12:41
2026-07-12 12:41
2026-07-12 12:40
2026-07-12 12:40
2026-07-12 12:40
2026-07-12 12:40
热门教程
2026-07-12 12:41
2026-07-12 12:41
2026-07-12 12:41
2026-07-12 12:41
2026-07-12 12:40
2026-07-12 12:40
2026-07-12 12:40
2026-07-12 12:40
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
















