




英伟达每美元性能是AMD15倍?成本解析帮你省更多

梦晨 发自 凹非寺量子位 | 公众号 QbitAI
为什么AI算力霸主永远是英伟达?
不算不知道,一算吓一跳:在英伟达平台每花一美元,获得的性能是AMD的15倍。
尽管英伟达卖的更贵,但只要买齐一套,就更省钱。
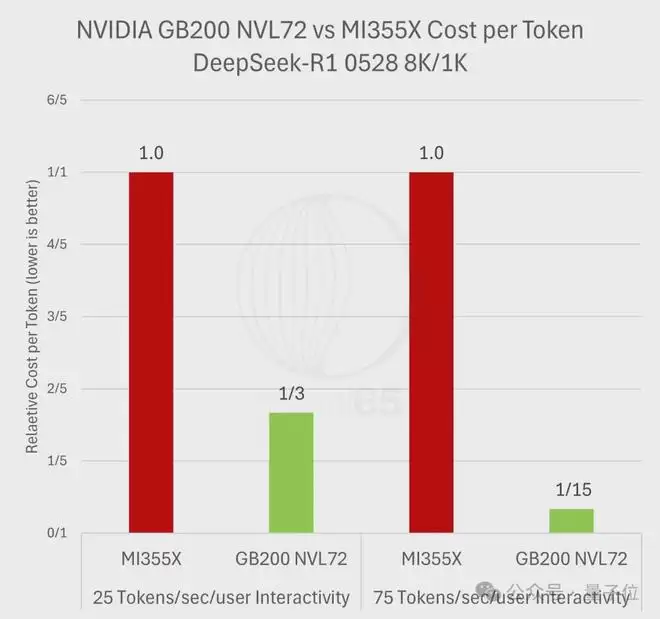
来自Signal65的一份最新详尽报告揭示了这个现实,一定条件下生成同样数量的token,英伟达的成本只有AMD的十五分之一。
这份报告基于SemiAnalysis Inference MAX的公开基准测试数据,时间跨度从2025年10月到12月,覆盖了从密集模型到前沿MoE推理模型的全场景测试。

黄仁勋的“买的越多,省的越多”原来是真的。

MoE时代:8卡系统撞上Scaling天花板
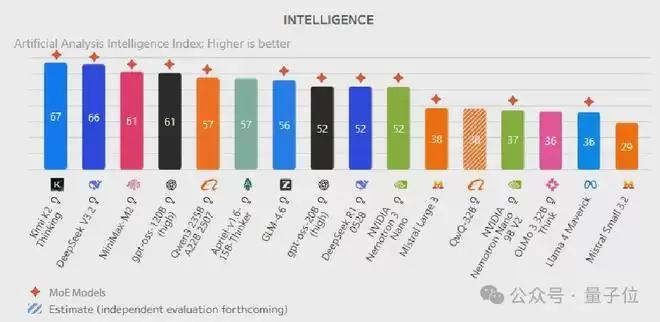
AI模型正在经历一场架构革命,打开Artificial Analysis排行榜就会发现,智能度排名前十的开源模型清一色都是MoE(Mixture of Experts,专家混合)推理模型。
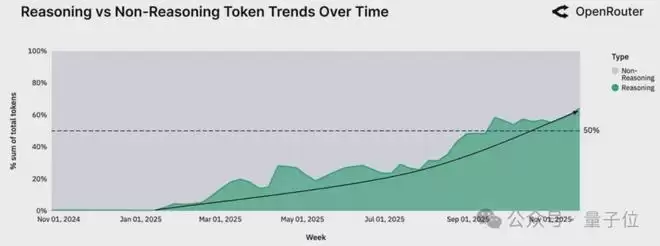
另一项来自OpenRouter的数据显示,超过50%的token流量正在被路由到推理模型上。
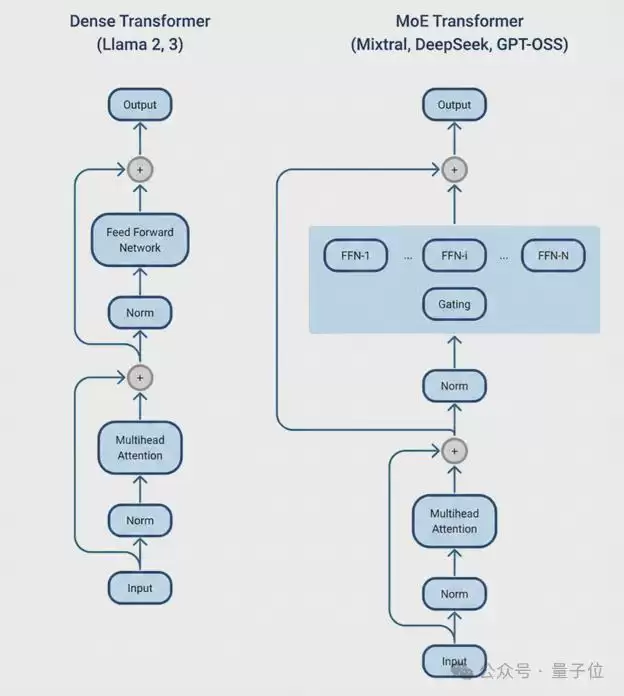
MoE架构的核心思路是把模型参数拆分成多个专门化的“专家”子网络,每个token只激活其中一小部分。
以经典的DeepSeek-R1为例,它拥有6710亿总参数,但每个token只激活370亿——这让它能以更低的计算成本提供前沿级别的智能。
问题随之而来。当专家分布在多块GPU上时,GPU之间的通信延迟会导致计算单元空闲等待数据,这些空闲时间直接转化为服务商的成本。
报告指出,无论是英伟达B200还是AMD MI355X,所有8卡系统在超出单节点规模后都会撞上“扩展天花板”(scaling ceiling)。
英伟达GB200 NVL72的解法是把72块GPU通过NVLink连接成一个单一域,提供130 TB/s的互联带宽。
在软件层面,整个系统就像一块巨型GPU一样运作。配合英伟达Dynamo推理框架的分离式预填充-解码调度和动态KV缓存路由,这套架构能够有效突破8卡系统的通信瓶颈。
模型越复杂,英伟达的优势越明显
报告测试了三类典型模型:模型越复杂,英伟达的优势越明显。
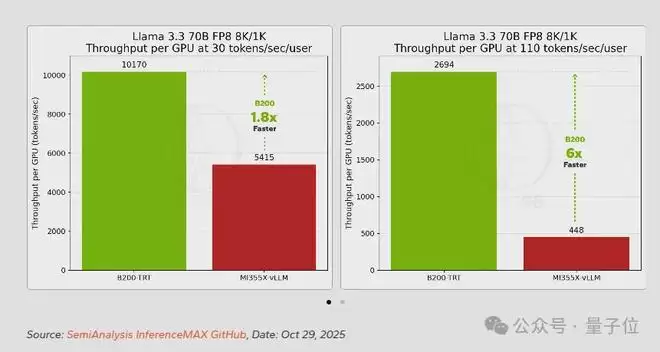
在密集模型Llama 3.3 70B上,英伟达B200对比AMD MI355X的领先幅度相对温和。
在基线交互性(30 tokens/sec/user)下,B200的性能约为MI355X的1.8倍;当交互性要求提升到110 tokens/sec/user时,这一差距扩大到6倍以上。
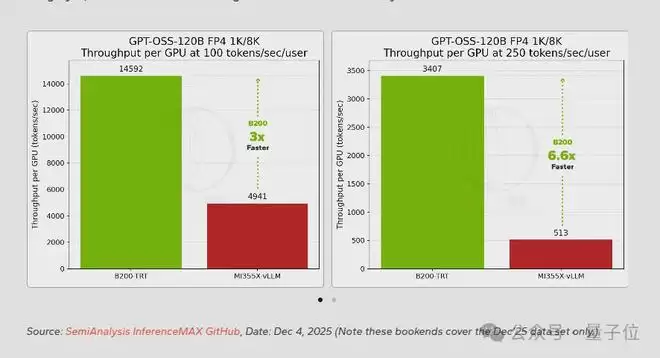
中等规模的MoE模型GPT-OSS-120B开始让差距变得更加显著。
这款OpenAI开源模型拥有1170亿总参数,但每个token只激活约51亿参数。在2025年12月的测试数据中,100 tokens/sec/user交互性下B200的性能接近MI355X的3倍。
在更符合推理模型需求的250 tokens/sec/user条件下,差距扩大到6.6倍。
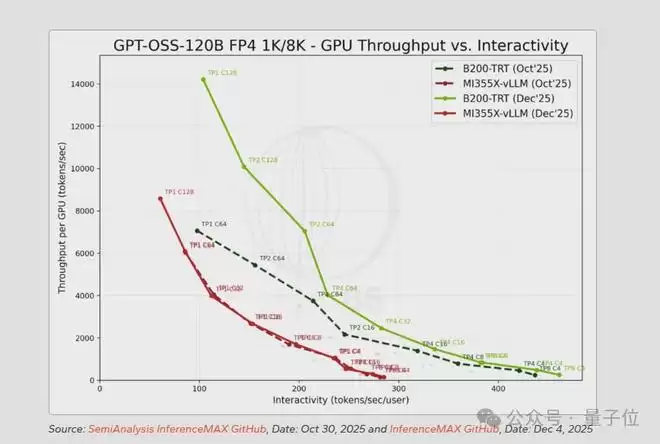
两个平台的绝对性能相比10月都有显著提升,英伟达的峰值吞吐从约7000 tokens/sec跃升至14000以上,AMD则从约6000提升到8500左右,但相对差距反而拉大了。
真正的分水岭出现在前沿推理模型DeepSeek-R1上。
这款模型集MoE路由、大参数规模和高强度推理生成于一身,对基础设施的要求极为苛刻。
测试结果显示:在25 tokens/sec/user交互性下,GB200 NVL72的每GPU性能是H200的10倍、MI325X的16倍;在60 tokens/sec/user下,相比H200的优势扩大到24倍,相比MI355X达到11.5倍;在75 tokens/sec/user下,GB200 NVL72的性能是B200单节点配置的6.5倍,是MI355X的28倍。
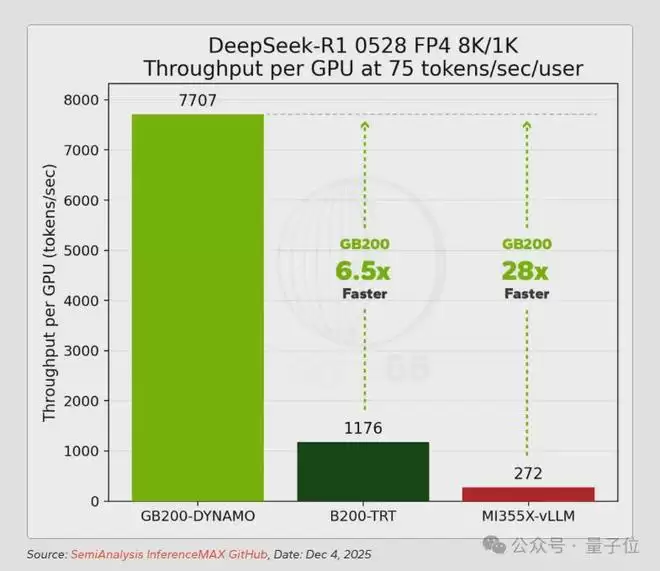
更关键的是,GB200 NVL72能够达到竞争平台根本无法企及的水平,在28卡配置下可以输出超过275 tokens/sec/user,而MI355X在相当吞吐水平下的峰值只有75 tokens/sec/user。
Token经济学:贵了1.86倍,便宜了15倍
直觉上,性能更强的平台应该更贵。事实也确实如此:根据Oracle Cloud的公开定价,GB200 NVL72的每GPU每小时价格为16美元,MI355X为8.60美元,前者是后者的1.86倍。
如果参照CoreWeave的定价,GB200 NVL72相比上一代H200的价格也贵了约1.67倍。
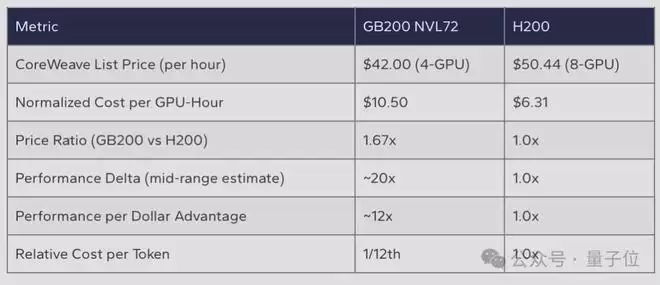
但报告的计算揭示了一个反直觉的结论:
在25 tokens/sec/user交互性下,GB200 NVL72的性能优势为5.85倍,除以1.86倍的价格溢价,每美元性能仍是MI355X的3.1倍。
在75 tokens/sec/user交互性下,28倍的性能优势除以1.86倍的价格,每美元性能达到MI355X的15倍,这意味着生成同等数量的token,英伟达平台的成本只有AMD的十五分之一。
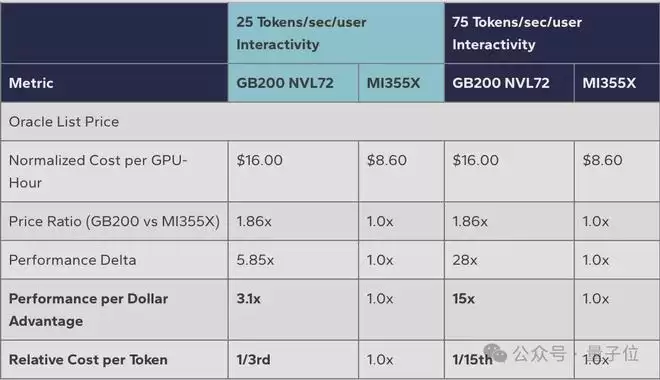
与上一代产品的对比同样惊人。
报告估算在DeepSeek-R1的典型工作负载下,GB200 NVL72相比H200的性能提升约20倍。
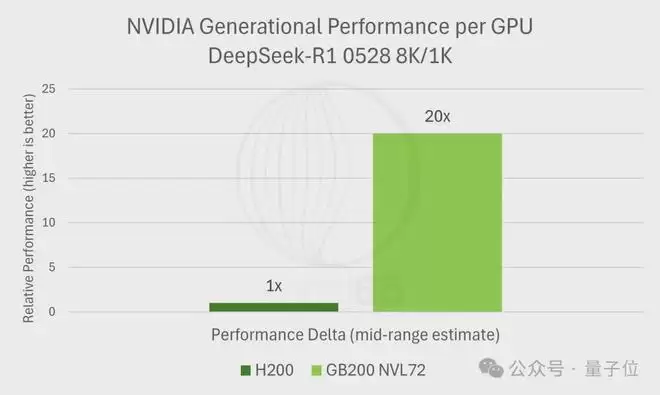
而GB200 NVL72价格仅上涨1.67倍,换算下来每美元性能提升约12倍,单token成本降至H200的十二分之一。
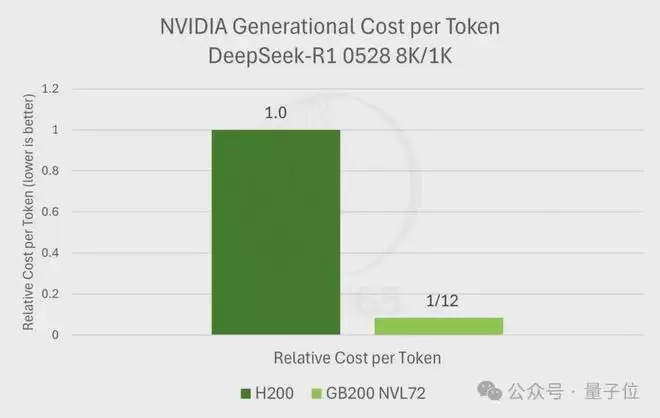
MoE推理让网络成为推理成本的瓶颈,而机柜级的GB200 NVL72恰好解决了这个问题。价值的衡量标准正在从单纯的算力转向“每美元能产出多少智能”。
报告在结论中指出,AMD的竞争力并未被完全否定——在密集模型和容量驱动的场景下,MI325X和MI355X仍有用武之地。
AMD的机柜级解决方案Helios也在开发中,可能在未来12个月内缩小差距。
但就当前的前沿推理模型而言,从芯片到互联到软件的端到端平台设计,已经成为成本效益的决定性因素。
[1]https://signal65.com/research/ai/from-dense-to-mixture-of-experts-the-new-economics-of-ai-inference/

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

阿里达摩院开源具身智能大脑RynnBrain基础模型详解
RynnBrain是什么 在具身智能领域,如何让机器人真正理解并适应复杂的物理世界,始终是核心挑战。近期,阿里巴巴达摩院发布了一项重要成果——开源了名为RynnBrain的具身智能大脑基础模型。这一模型实现了关键突破,首次赋予机器人接近人类的时空记忆与物理空间推理能力。 具体而言,RynnBrain

昆仑万维开源SkyReels-V3多模态视频生成模型详解
SkyReels-V3是什么 视频创作的门槛,正在被一项新技术重新定义。最近,昆仑万维开源的SkyReels-V3,可以说在业内投下了一枚“重磅冲击波”。它不再是一个功能单一的玩具,而是一个用单一架构就能实现专业级视频创作的“多面手”。简单来说,它能让你手里的静态照片“活”起来,变成动态影像;还能智

HKUDS开源AI Agent经济生存基准测试框架ClawWork详解
ClawWork是什么 如果让AI去真实世界里“打工”,它能不能养活自己?香港大学数据科学实验室(HKUDS)开源的ClawWork项目,就是为了回答这个问题而生的。它本质上是一个AI Agent的“经济生存”基准测试框架,专门评估大模型在模拟真实商业环境中的“赚钱能力”。 这套系统的规则很现实:给

小红书开源图像编辑模型FireRed使用指南
FireRed-Image-Edit是什么 在AI图像生成与编辑领域,开源模型正迅速崛起,其能力已能比肩甚至超越部分闭源方案。近期,由小红书Super Intelligence团队研发并开源的FireRed-Image-Edit模型,便是这一趋势下的杰出代表。这款基于先进扩散架构的通用图像编辑AI,

蚂蚁开源全模态大模型Ming‑Flash‑Omni 2.0详解
在人工智能模型普遍追求规模与通用性的当下,开发者们迫切需要一款能够真正“看懂”图像、“听懂”声音、“读懂”文字,并能自由进行跨模态内容创作的“全能型”AI工具。近期,蚂蚁集团重磅开源的全模态大语言模型Ming-flash-omni-2 0,正将这一愿景变为现实。它不仅彻底打通了图像、视频、音频与文本








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
