




首个原生语音基准则:大模型落地真实音频场景MultiChallenge

Scale AI正式发布了首个原生音频多轮对话基准Audio MultiChallenge,直接撕开了大模型靠合成语音评测维持的优等生假象。实验显示,强如Gemini 3 Pro在真实场景下的通过率也仅过半,而GPT-4o Audio的表现更是令人大跌眼镜。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
随着实时语音大模型的普及,人们一度以为AI实时伴侣已经跨越了自然交互的最后一道门槛。
然而,大模型在语音对话中表现出的聪明,很大程度上源于评测手段的滞后。
此前,Scale AI推出的MultiChallenge基准凭借对指令保留、推理记忆和自我一致性的严苛考察,被公认为评估大模型逻辑长性的黄金标准。
但长久以来,该基准一直缺少一个真正的音频原声版本。
最近,Scale AI正式补齐了这块拼图,发布Audio MultiChallenge,不仅刷新了语音交互的新高度,更揭开了行业内一个公开的秘密:
由于缺乏原生音频测试集,模型厂商在发布报告时,往往不得不利用TTS(Text-to-Speech)将文本基准转换为语音进行评测。

论文链接:https://arxiv.org/pdf/2512.14865
这种做法虽然让数据看起来很漂亮,却在无形中给模型加了一层过度美化的滤镜。

撕掉语音外壳
为什么TTS测不出真本事?
利用TTS转换来进行评测,实际上是为模型营造了一个完美的无菌环境。
TTS 生成的语音平滑、规律且高度标准化,彻底过滤掉了人类语言中最重要的特质:日常说话时的各种吞吐、重复、琐碎停顿以及临时改口。
当你对AI说:我想定周一,噢不,是周三的票,等下……还是周二吧。
这种充满了逻辑回溯和口语碎片的自然场景,是目前TTS技术极力避免但在现实生活中无处不在的。
过去,模型穿上了一层由合成语音搭建的语音外壳,本质上是在用文本思维处理洁净信号。
而一旦脱离这个外壳,面对Audio MultiChallenge中47名真实说话者录制的原始音频,模型的逻辑链条便会迅速崩塌。
论文直言不讳地指出:模型在合成语音上的得分显著高于真实人声,这证实的洁净的合成音频掩盖了模型在现实世界中的失败模式(Masking real-world failure modes)。
Gemini 3 Pro勉强登顶
GPT-4o意外折戟标题
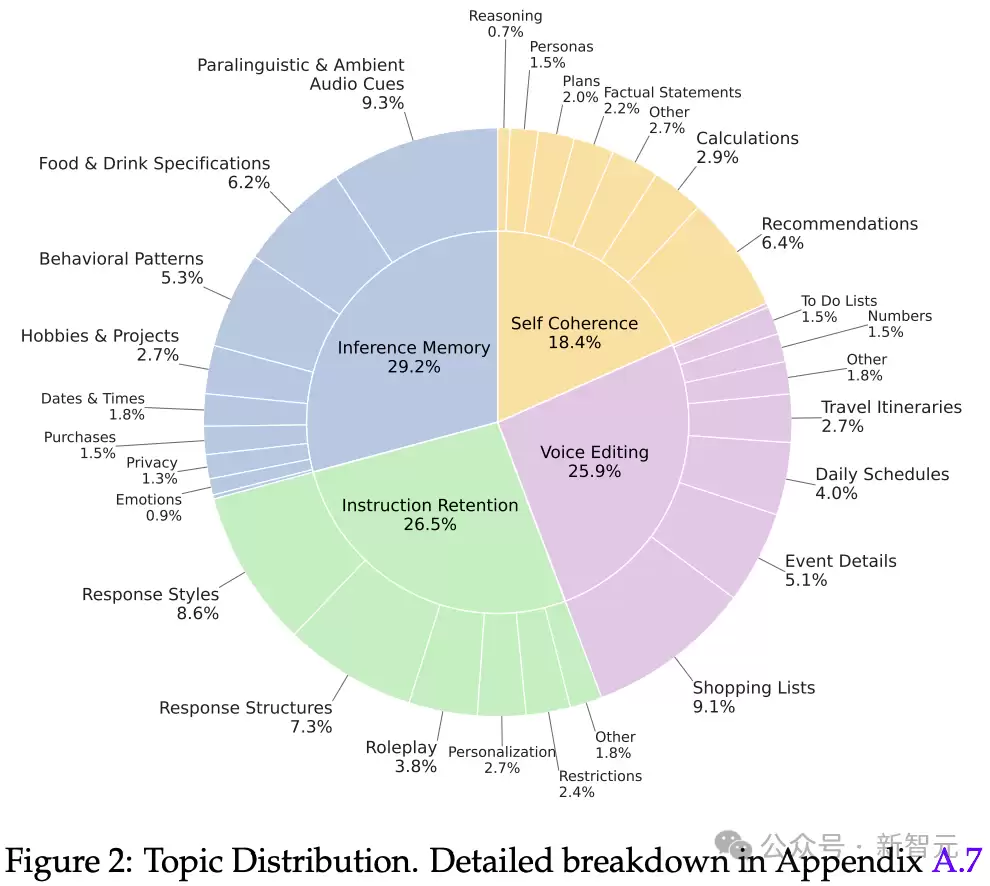
Audio MultiChallenge延续了原版的严苛逻辑,并针对音频特性新增了致命的一击,从指令保留、推理记忆、自我一致性以及核心的Voice Editing(语音编辑) 四个轴向对模型进行综合考核。
根据论文公布的排行榜,目前全球顶尖模型的音频原生能力普遍处于及格线以下:
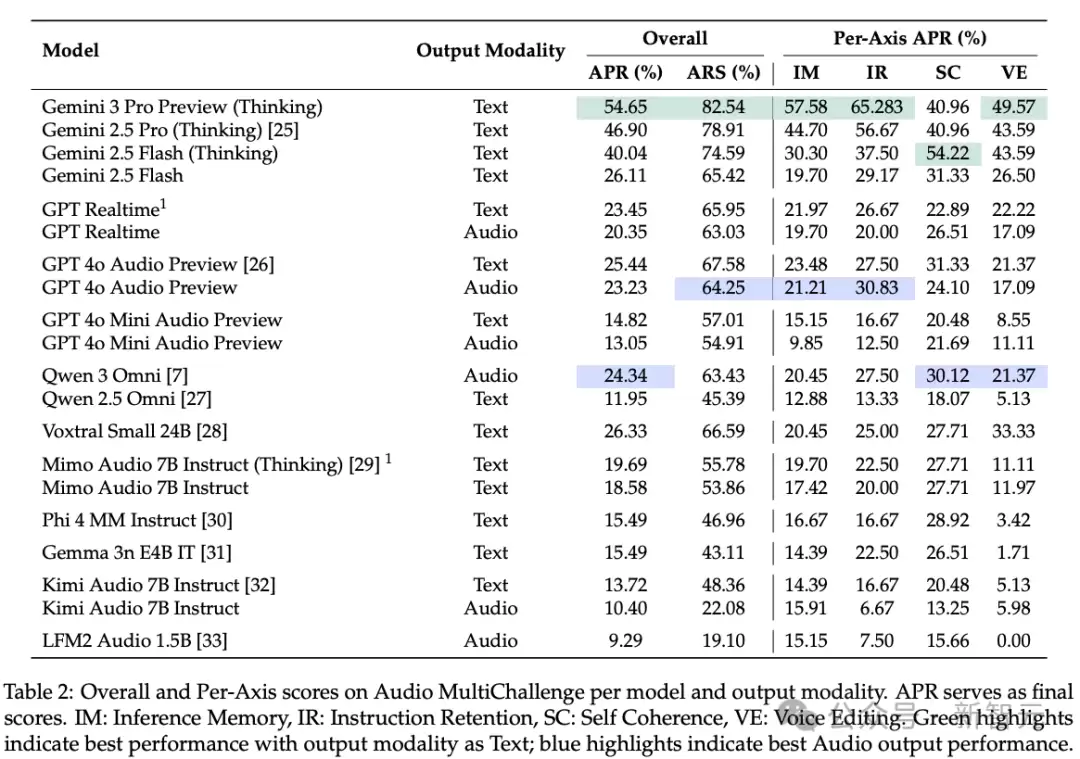
实验数据揭露了一个惊人的落差:Gemini 3 Pro Preview凭借其推理架构在逻辑深度上维持了领先;而GPT-4o AudioPreview在面对真实人类语音时,表现出的鲁棒性远低于预期,通过率甚至只有Gemini的一半左右。
揭秘三大失败模式
语音逻辑的深层鸿沟
论文通过详细的错误分析,精准捕捉到了模型在音频模式下的三个软肋,这些结论直接指出了大模型在语音交互中的底层Gap:
语音编辑是逻辑黑洞:这是本次基准新增的维度。当用户在说话过程中中途改口或逻辑回溯时,大多数模型会死板地执行听到的第一个指令。该维度的平均通过率仅为17.99%,这意味着模型在听觉上无法有效处理信息的撤回与覆盖。时长驱动的崩溃:模型表现随着音频总时长增加而稳步恶化。数据显示,当对话累计音频超过8分钟时,模型的自我一致性得分会骤降至 13% 左右。这意味着目前的语音模型在处理长程语音上下文时,状态跟踪能力极其薄弱。音频线索的感知缺失:当任务要求模型识别非语意信号(如背景的环境声、说话人的语气情绪)来辅助推理时,模型表现比纯语意任务下降了 36.5%。这说明模型依然把语音当成脱水的文字在读,而没能真正听懂声音背后的物理世界。
结语
Audio MultiChallenge的发布证明了语音绝不仅是文本的简单投影,包含着实时状态跟踪、情绪理解以及复杂的口语特质处理。
Scale AI的这一记重锤敲醒了业界:如果我们不能撕掉那层精美的语音外壳,解决模型对自然语音中不完美特征的感知断层,那么AGI驱动的自由交互,将永远停留在听懂单词却不懂逻辑的初级阶段。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

高通AI研究:用更少文字解决复杂问题的智能思考方法
这项由高通AI研究院主导的突破性研究,于2026年3月以预印本论文形式发布。它直指一个长期困扰AI发展的核心痛点:当我们试图让AI模仿人类“逐步思考”时,它们往往会陷入一种低效的“话痨”模式,产生大量冗余、重复的文本,既拖慢了响应速度,也浪费了宝贵的计算资源。 不妨做个类比:你向一位聪明的学生请教数

华中科大团队突破AI空间感技术解决方向感缺失难题
你是否曾向AI助手发出过“描述桌子右边有什么”或“找找沙发后面的东西”这样的指令,却得到了令人困惑的回应?这背后的核心原因在于,当前主流的多模态大模型虽然具备出色的物体识别能力,却普遍缺乏对三维空间的真实“感知”。它们如同仅通过二维照片认识世界,难以准确判断物体的相对方位、深度距离以及复杂的遮挡关系

摩尔线程携手光轮智能战略合作 共研高置信度仿真数据合成方案
近日,国内领先的GPU企业摩尔线程与前沿AI公司光轮智能正式宣布达成深度战略合作。双方的核心目标,是共同构建一套高置信度、可规模化的仿真数据合成解决方案。此举被业界广泛解读为,旨在为具身智能(Embodied AI)的长期演进与发展,筑牢一项自主可控的关键性数字基础设施。 具身智能,简而言之,是赋予

IBM推出VAREX基准测试评估AI解读政府表格能力
这项由IBM Research主导的研究,于2026年3月正式发布于arXiv预印本平台(论文编号:arXiv:2603 15118v1)。研究团队构建了一个名为VAREX的全新评估基准,其核心目标在于系统性地评测各类AI模型在理解与提取政府表格信息上的真实性能。 我们可以将AI模型想象成一位新入职

德克萨斯农工大学揭示AI视频生成时空错乱原因
德克萨斯农工大学的研究团队近期取得了一项突破性进展,揭示了当前AI视频生成技术中一个普遍存在却长期被忽略的核心缺陷。你是否也曾感到AI生成的视频“总有些别扭”?比如蜂鸟振翅显得过于缓慢,或者人物动作的节奏如同水下镜头般迟滞——你的直觉没错,问题的根源恰恰在于AI对“时间”的感知完全失准。 研究人员将








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
