




MultiTalk模型解析:98.7%语音视觉对齐精度的多角色对话SOTA

MultiTalk技术框架的核心是一个基于DiT(扩散变换器)架构的视频扩散模型。
由中山大学、美团和港科大联合开源的MultiTalk项目,能够生成多虚拟人物对话视频。这项技术在实现语音与唇形同步方面达到了当前最优(SOTA)水平,并且支持通过提示词(prompt)来控制人物、物体与场景之间的交互。




相关链接
项目主页:https://meigen-ai.github.io/multi-talk/代码仓库:https://github.com/MeiGen-AI/MultiTalk
研究论文:https://arxiv.org/abs/2505.22647
论文介绍
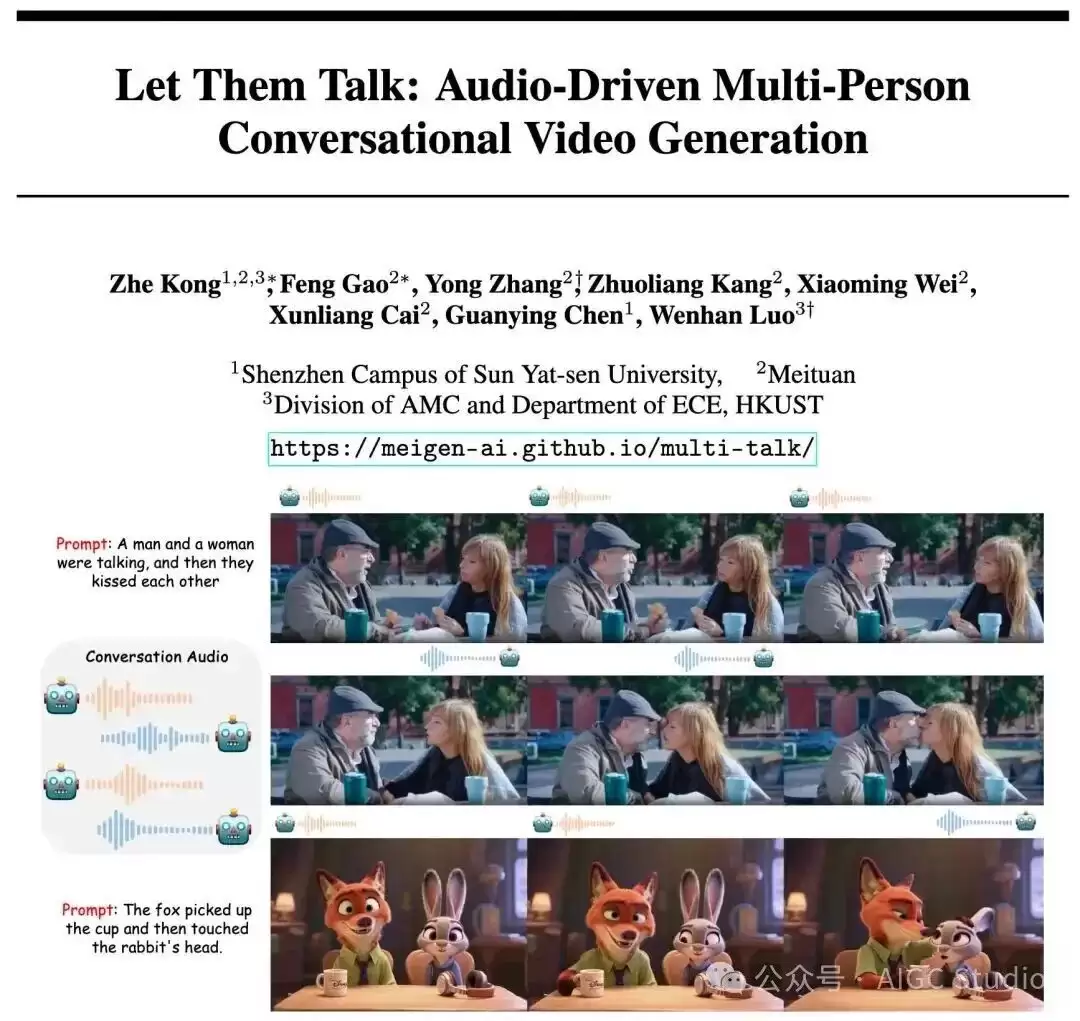
近年来,音频驱动的人物动画技术发展迅猛,从极为逼真的说话头部(Talking Head)动画,到全身动作同步(Talking Body),已经能够生成高度自然的单人视频。然而,现有技术大多局限于单人场景,在面对多人对话视频生成时,主要面临三大挑战:
如何适配和处理多条音频流输入,准确区分并绑定不同人物对应的音频信号?当人物在画面中移动时,如何精准定位其运动区域?如何让生成的视频严格遵循文本描述中的复杂动作(如大幅度的肢体动作)?方法概述
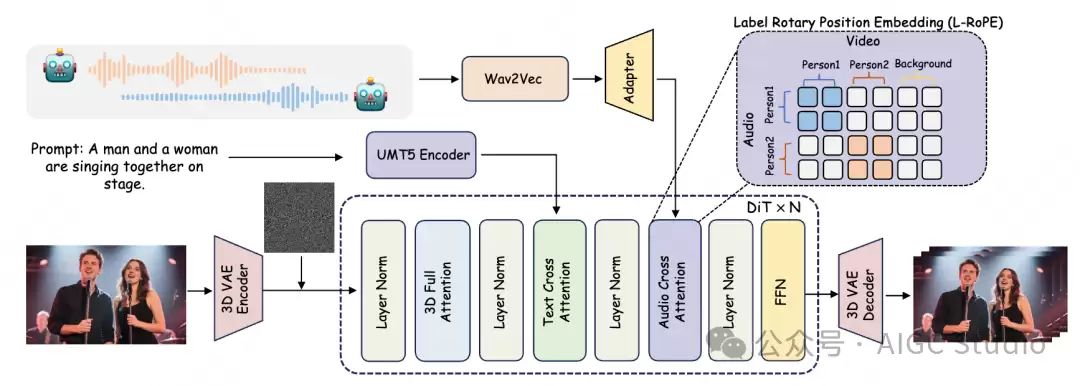
MultiTalk的核心骨架是一个基于DiT(Diffusion-in-Transformer)的视频扩散模型。传统的图像到视频(I2V)扩散模型通常并不原生支持音频输入。为了让模型学会“说话”,MultiTalk在每一个DiT块的文本交叉注意力层之后,新增了专门的模块,这些模块包含层归一化(LayerNorm)和音频交叉注意力机制,专门用于处理和整合音频条件信息。
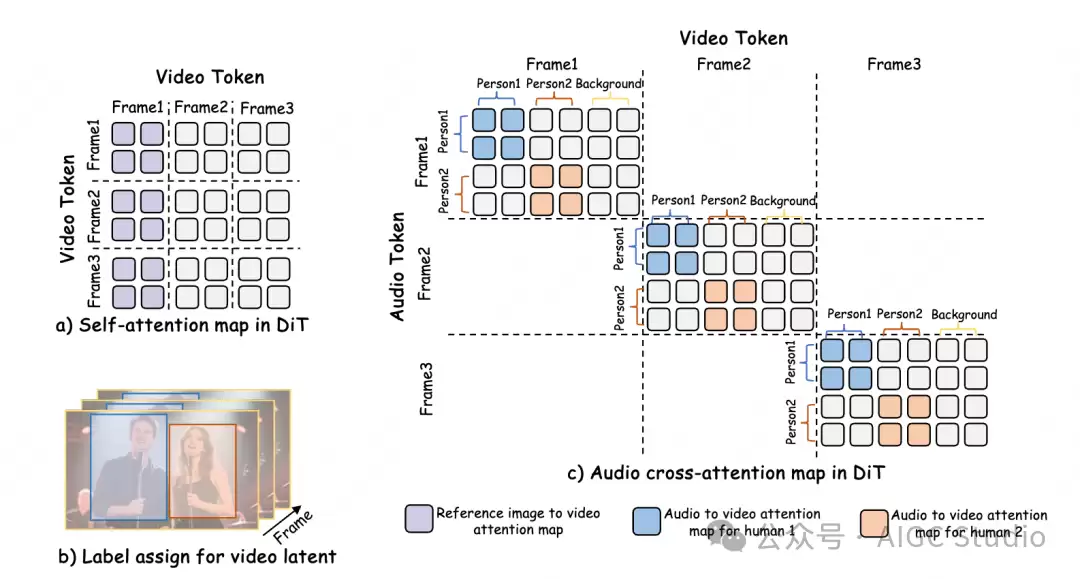
传统方法若直接将多条音频流融合输入,容易导致人物与音频的错配问题。为此,MultiTalk提出了标签旋转位置编码(Label Rotary Position Embedding, L-RoPE),通过以下两个步骤实现精确绑定:
步骤1:自适应人物定位利用参考图像的自注意力图(Self-Attention Map),计算人物区域与背景的相似度矩阵,从而将视频潜在特征(Video Latents)动态分割成不同人物对应的区域。步骤2:标签分配与旋转编码
为每个说话人分配独立的数值范围标签(例如Person1:0-4,Person2:20-24),并通过旋转位置编码(RoPE)技术,将标签信息映射到音频交叉注意力层。这样一来,具有相同标签的音频信号与视频区域会被关联激活,从而实现音频与人物唇部动作的精确绑定。
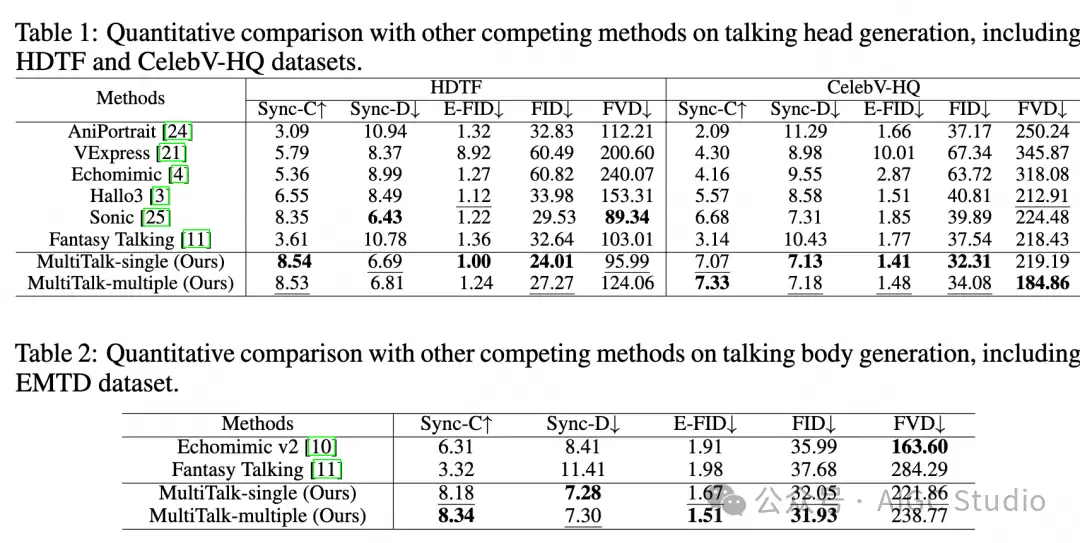
实验结果
结论
MultiTalk提出了一种音频驱动的多人物对话视频生成方案,其核心突破在于创新的L-RoPE方法。该方法结合了自适应人物定位和带有类别信息的标签编码,有效解决了多流音频注入和人物绑定这一核心难题。此外,其精心设计的部分参数训练和多任务训练策略,确保了模型在有限资源下,依然能够保持强大的指令遵循能力和高质量的视觉输出。MultiTalk首次将语音驱动的动画从单人场景成功扩展到多人交互场景,为虚拟主播、影音制作等领域提供了强有力的新一代工具。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

腾讯Ardot设计智能体公测上线 一键将设计稿转为前端代码
腾讯AI设计工具Ardot开放公测,可将自然语言描述直接转化为可编辑设计稿并一键生成代码。该工具旨在简化设计开发流程,用户用语言描述界面即可实时生成可调整的初稿并转换为可用代码,有助于提升原型验证与团队协作效率,降低实现门槛。其实际价值取决于生成精度、交互能力及代码质。

阿里云峰会5月20日重磅发布全新升级千问大模型
千问大模型宣布将于5月20日阿里云峰会推出更全能、强大的“新朋友”,可能为全新大模型或多模态AI平台,预示技术路径与产品格局新变化。该发布与云生态深度绑定,将推动AI应用拓展、成本优化及生态开放,引发行业新浪潮。

云境标书AI加入英伟达初创加速计划 AI赋能招投标行业新突破
云境标书AI”入选NVIDIA初创加速计划,获得技术、专家及生态资源支持。该产品专注于招投标领域,利用AI技术高效解析文件、生成内容,并内置合规风控与多行业知识库。其服务注重数据安全与用户所有权,提供免费基础功能与灵活付费模式,旨在提升投标效率与中标率。

酷开企业AI操作系统发布 引领企业管理AI原生转型
酷开科技发布原生AI企业操作系统,旨在将战略目标转化为可执行、可追踪的数字化流程。该系统通过企业、岗位、个人及任务四大智能体协同运作,在“人机协同”原则下提升管理效率。同时,酷开配套提供理论书籍与咨询服务,形成完整转型方案,助力企业特别是中小企业迈向AI原生管理新阶段。

如祺出行AI数据战略:以高价值场景驱动世界模型训练
具身智能发展面临高质量数据短缺挑战。如祺出行依托平台优势,日均产出1600小时多模态真实场景数据,完整覆盖驾驶决策与反馈链条,为世界模型训练提供稀缺资源。公司已构建从采集到标注的全栈数据服务能力,业务拓展至自动驾驶、具身智能与大模型等领域,并与多家头部企业达成合作。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
