




DeepSeek-R1发布一年,每token成本降至原价1/32

编辑 | 杜伟、泽南
几天前,DeepSeek 毫无预兆地更新了 R1 论文,将原有的 22 页增加到了现在的 86 页。
新版本充实了更多细节内容,包括首次公开训练全路径,即从冷启动、训练导向 RL、拒绝采样与再微调到全场景对齐 RL 的四阶段 pipeline,以及「Aha Moment」的数据化验证等等。

DeepSeek-R1 是在 2025 年 1 月 20 日发布的开源推理大模型,它拥有 6710 亿参数、单 Token 激活参数为 370 亿,并采用了 MoE 架构,训练效率得到了显著提升。
R1 在去年的推出震动了全球 AI 领域,其高效率的模型架构、训练方法、工程优化和蒸馏方法在之后成为了全行业的趋势。
没想到在不到一年之后的今天,R1 模型的每 token 成本竟已降低了到了 1/32!
今天,英伟达发表了一篇长文博客,展示了其如何在 Blackwell GPU 上通过软硬协同对 DeepSeek-R1 进一步降本增效。

随着 AI 模型智能程度的不断提升,人们开始依托 AI 处理日益复杂的任务。从普通消费者到大型企业,用户与 AI 交互的频率显著增加,这也意味着需要生成的 Token 数量呈指数级增长。为了以最低成本提供这些 Token,AI 平台必须实现极高的每瓦特 Token 吞吐量。
通过在 GPU、CPU、网络、软件、供电及散热方案上的深度协同设计,英伟达持续提升每瓦特 Token 吞吐量,从而有效降低了每百万 Token 的成本。此外,英伟达不断优化其软件栈,从现有平台中挖掘更强的性能潜力。
那么,英伟达是怎样协同利用运行在 Blackwell 架构上的推理软件栈,以实现 DeepSeek-R1 在多种应用场景中的性能增益呢?我们接着往下看。
最新 NVIDIA TensorRT-LLM 软件大幅提升推理性能
NVIDIA GB200 NVL72 是一个多节点液冷机架级扩展系统,适用于高度密集型的工作负载。该系统通过第五代 NVIDIA NVLink 互连技术和 NVLink Switch 芯片连接了 72 个 NVIDIA Blackwell GPU,为机架内的所有芯片提供高达 1800 GB/s 的双向带宽。
这种大规模的「扩展域」(Scale-up Domain)专为稀疏 MoE 架构优化,此类模型在生成 Token 时需要专家之间频繁的数据交换。
Blackwell 架构还加入了对 NVFP4 数据格式的硬件加速。这是英伟达设计的一种 4 位浮点格式,相比其他 FP4 格式能更好地保持精度。此外,解耦服务(Disaggregated Serving)这类优化技术也充分利用了 NVL72 架构和 NVLink Switch 技术。简单来解释一下解耦服务,即在一组 GPU 上执行 Prefill(预填充)操作,在另一组 GPU 上执行 Decode(解码)操作。
这些架构创新使得 NVIDIA GB200 NVL72 在运行 DeepSeek-R1 时,能够提供行业领先的性能。
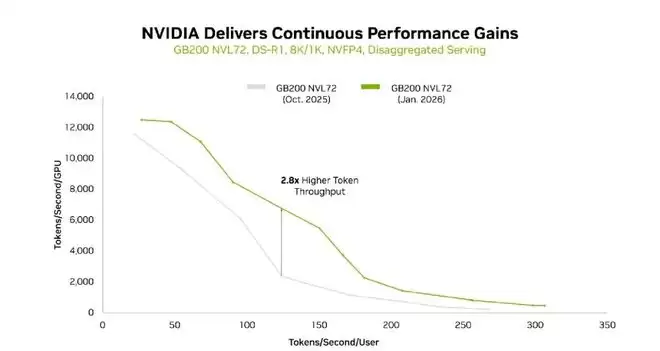
得益于最新 NVIDIA TensorRT-LLM 软件和 GB200 NVL72 的协同,DeepSeek-R1 在 8K/1K 输入 / 输出序列长度下的 Token 吞吐量大幅提升。
同样地,得益于最新 NVIDIA TensorRT-LLM 软件与 GB200 NVL72 的协同,在 1K/1K 序列长度下,DeepSeek-R1 Token 吞吐量同样大幅提升。
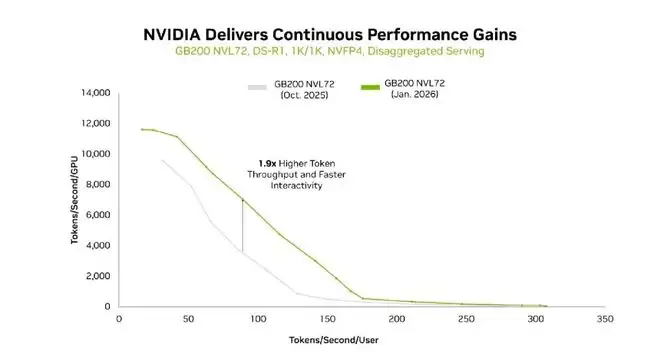
另外,在 8K/1K、1K/1K 两种输入 / 输出序列长度的吞吐量与交互性曲线上,GB200 NVL72 也展现出了领先的单 GPU 吞吐能力。
而 TensorRT-LLM 开源库(用于优化 LLM 推理)的最新增强功能,在同一平台上再次大幅增强了性能。在过去三个月中,每个 Blackwell GPU 的吞吐量提升高达 2.8 倍(这里指的是在 8k/1k 输入 / 输出序列长度下,去年 10 月到今年 1 月的 Token 吞吐量变化)。
这些优化背后的核心技术包括:
扩大 NVIDIA 程序化依赖启动 (PDL) 的应用:降低核函数启动延迟,有助于提升各种交互水平下的吞吐量;底层核函数优化:更高效地利用 NVIDIA Blackwell Tensor Core;优化的 All-to-all 通信原语:消除了接收端的额外中间缓冲区。
有业内人士对英伟达放出的一系列图表进行了直观的解读,用一组数据来总结就是,「通过软硬件的深度协同,自 2025 年 1 月以来,英伟达已经将 DeepSeek-R1 (671B) 的吞吐量提升了约 36 倍,这意味着单 Token 的推理成本降低到了约 1/32。」
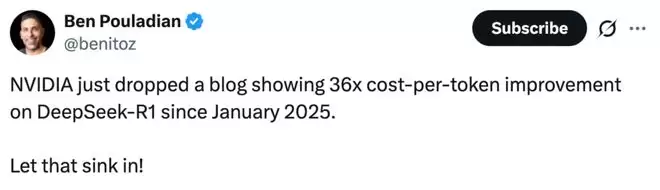

利用多 token 预测和 NVFP4 技术加速 NVIDIA HGX B200 性能
NVIDIA HGX B200 平台由八个采用第五代 NVLink 互连和 NVLink Switch 连接的 Blackwell GPU 组成,在风冷环境下也能实现强大的 DeepSeek-R1 推理性能。
两项关键技术使 HGX B200 上的 DeepSeek-R1 推理性能大幅提升。第一项技术是使用多 token 预测 (MTP),它可以显著提高各种交互级别下的吞吐量。在所有三种测试的输入 / 输出序列组合中都观察到了这一现象。
在 HGX B200 平台上,使用 1K/1K 序列长度和聚合服务模式下,FP8(不带 MTP)、FP8(带 MTP)和 NVFP4(带 MTP)的吞吐量与交互性曲线对比。
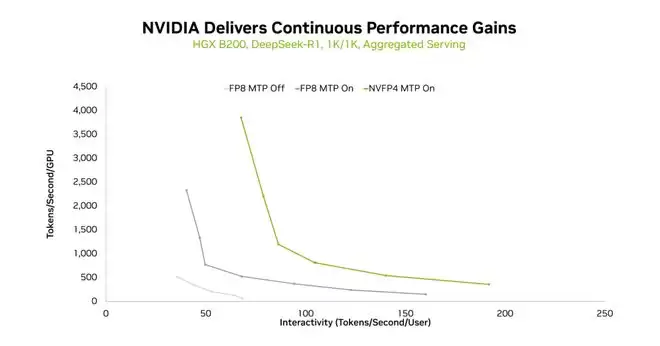
第二种方法是使用 NVFP4,充分利用 Blackwell GPU 计算能力来提升性能,同时保持精度。
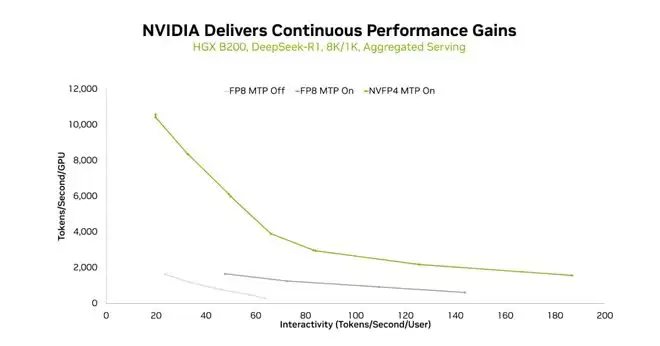
在 HGX B200 平台上,使用 8K/1K 序列长度和聚合服务模式下,FP8(不含 MTP)、FP8(含 MTP)和 NVFP4(含 MTP)的吞吐量与交互性曲线对比。
NVFP4 使用在完整的 NVIDIA 软件栈上(包括 TensorRT-LLM 和 NVIDIA TensorRT 模型优化器),以确保高性能并保持精度。这使得在给定交互级别下能够实现更高的吞吐量,并且在相同的 HGX B200 平台上,可以实现更高的交互级别。
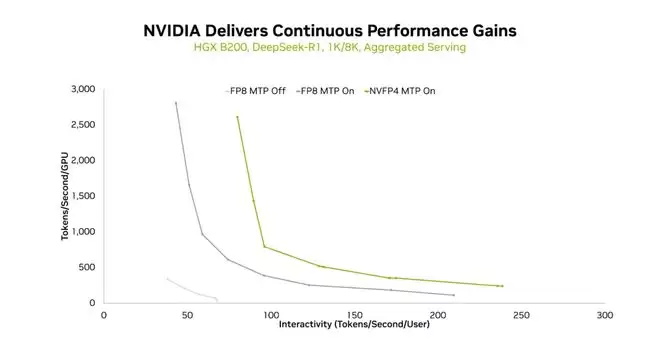
在 HGX B200 平台上,FP8(无 MTP)、FP8(有 MTP)和 NVFP4(有 MTP)的吞吐量与交互性曲线,序列长度分别为 1K 和 8K,并采用聚合服务模式。
英伟达表示,其正在不断提升整个技术堆栈的性能,可以帮助用户基于现有硬件产品,持续提升大语言模型的工作负载效率,提升各种模型的 token 吞吐量。
博客地址:
https://developer.nvidia.com/blog/delivering-massive-performance-leaps-for-mixture-of-experts-inference-on-nvidia-blackwell/

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

特斯拉德州工厂部署14辆无方向盘自动驾驶出租车
特斯拉的机器人出租车,终于从概念驶入了现实。就在最近,其位于德州的超级工厂完成了首批14辆无方向盘Cybercab的部署。这可不是简单的测试车,而是标志着特斯拉酝酿已久的Robotaxi战略,正式迈入了规模化验证的关键一步。 仔细观察这批车辆,你会发现它们与去年10月“We Robot”活动上亮相的

魏牌V9X搭载归元S平台引领AI豪华出行新时代
4月17日,一场以“契约”为核心的技术盛宴在保定拉开帷幕。魏牌归元S技术发布会暨V9X预售发布会,不仅揭开了长城汽车36年造车智慧的集大成之作——归元S平台,也宣告了其首款旗舰车型魏牌V9X以37 18万元起的预售价,正式开启全球征程。这个平台,与其说是一套技术方案,不如说是一次以“用户价值”为锚点

DeepSeek估值680亿融资20亿 梁文锋首次回应
本周五,人工智能行业迎来一则关键动态。 据The Information、路透社等多家权威媒体援引知情人士消息,中国AI明星企业深度求索(DeepSeek)正与投资方展开洽谈,计划以约100亿美元估值进行新一轮融资,目标筹集至少3亿美元资金。 从行业渠道获悉,DeepSeek接触投资机构的情况属实,

WorkBuddy Tabbit OpenCLI 三角协同高效使用指南
做AI工具调研时,有个现象挺有意思:网上文章要么说Tabbit是OpenClaw的最佳搭档,要么夸OpenCLI是新一代浏览器自动化神器,但很少有人把这三者放在一起讨论。 今天要聊的,正是WorkBuddy、Tabbit和OpenCLI这三者如何协同工作,形成一个高效的闭环。 一、为什么需要三角协同

Mythos推动AI进入行动时代从语言理解迈向动手操作
4月8日,Anthropic的一则官宣,在看似平静的AI湖面上投下了一颗深水冲击波。他们发布了Claude Mythos Preview,但紧接着,又以一种近乎“自我封印”的姿态,亲手为这颗冲击波套上了层层枷锁。 这完全不像一场常规的发布会。没有庆祝,没有香槟,也没有宣布全面开放。相反,Anthro








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
