




研究发现大模型“长脑子”:LLM中层会自发模拟人脑进化

编辑|Panda
生物智能与人工智能的演化路径截然不同,但它们是否遵循某些共同的计算原理?
最近,来自帝国理工学院、华为诺亚方舟实验室等机构的研究人员发表了一篇新论文。该研究指出,大型语言模型(LLM)在学习过程中会自发演化出一种协同核心(Synergistic Core)结构,有些类似于生物的大脑。

论文标题:A Brain-like Synergistic Core in LLMs Drives Behaviour and Learning论文地址:https://arxiv.org/abs/2601.06851
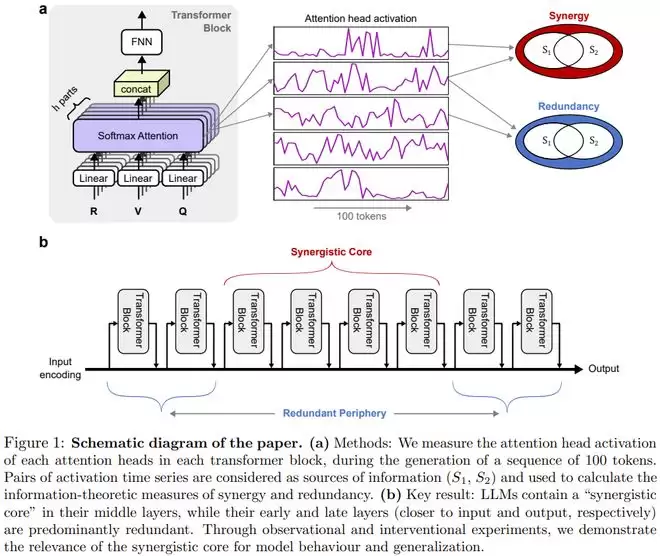
研究团队利用部分信息分解(Partial Information Decomposition, PID)框架,对 Gemma、Llama、Qwen 和 DeepSeek 等模型进行了深度剖析。
他们发现,这些模型的中层表现出极强的协同处理能力,而底层和顶层则更偏向于冗余处理。
协同与冗余:LLM 的内部架构
研究团队将大型语言模型视为分布式信息处理系统,其核心实验设计旨在量化模型内部组件之间交互的本质。为了实现这一目标,研究者选取了 Gemma 3、Llama 3、Qwen 3 8B 以及 DeepSeek V2 Lite Chat 等多种具有代表性的模型系列进行对比分析。
实验方法与量化指标
在实验过程中,研究者向模型输入了涵盖语法纠错、逻辑推理、常识问答等 6 个类别的认知任务提示词。
针对每一个提示词,模型会生成一段 100 个 Token 的回答,实验设备则同步记录下每一层中所有注意力头或专家模块的激活值。
具体而言,研究人员计算了这些输出向量的 L2 范数,以此作为该单元在特定时间步的激活强度数据。
基于这些时间序列数据,研究团队应用了整合信息分解(Integrated Information Decomposition, ID)框架。
这一框架能够将注意力头对之间的交互分解为「持续性协同」和「持续性冗余」等不同原子项。
通过对所有注意力头对的协同值和冗余值进行排名并求差,研究者得到了一个关键指标:协同-冗余秩(Synergy-Redundancy Rank)。该指标能够清晰地标示出模型组件在处理信息时,究竟是倾向于进行独立的信号聚合,还是在进行跨单元的深度集成。
跨模型的空间分布规律
实验数据揭示了一个在不同架构模型中高度一致的空间组织规律。在归一化后的模型层深图中,协同分布呈现出显著的「倒 U 型」曲线 :
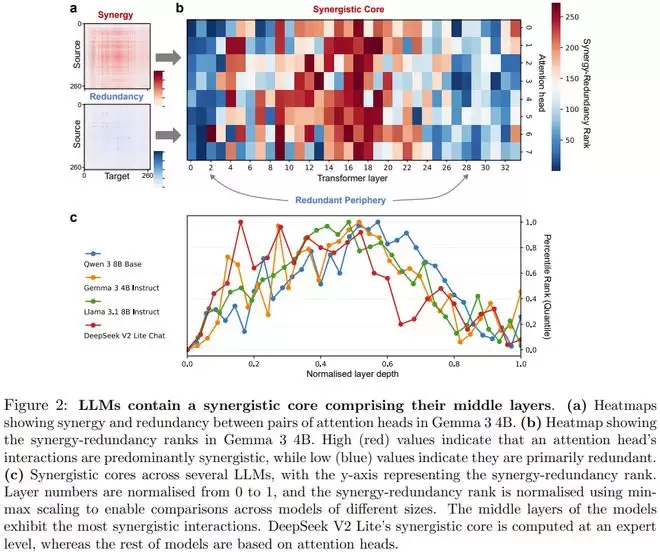
冗余外周(Redundant Periphery):模型的早期层(靠近输入端)和末期层(靠近输出端)表现出极低的协同秩,信息处理以冗余模式为主。在早期层,这反映了模型在进行基本的解词元化(Detokenization)和局部特征提取;而在末期层,则对应着 Token 预测和输出格式化的过程。协同核心(Synergistic Core):模型的中层则展现出极高的协同秩,形成了核心处理区。例如,在对 Gemma 3 4B 的热图分析中,中间层的注意力头之间表现出密集且强烈的协同交互,这正是模型进行高级语义集成和抽象推理的区域。
架构差异与一致性
值得注意的是,这种「协同核心」的涌现并不依赖于特定的技术实现。
在 DeepSeek V2 Lite 模型中,研究者即使是以「专家模块」而非「注意力头」作为分析单位,依然观察到了相同的空间分布特征。
这种跨架构的收敛性表明,协同处理可能是实现高级智能的一种计算必然,而非单纯的工程巧合。
这种组织模式与人脑的生理结构形成了精确的映射:人脑的感官和运动区域同样表现出高冗余性,而负责复杂认知功能的联合皮层则处于高协同的「全局工作空间」中心。
智能的涌现:学习驱动而非架构使然
一个关键的问题在于:这种结构是 Transformer 架构自带的,还是通过学习习得的?
研究人员通过分析 Pythia 1B 模型的训练过程发现,在随机初始化的网络中,这种「倒 U 型」的协同分布并不存在。随着训练步数的增加,这种组织架构才逐渐稳定形成。
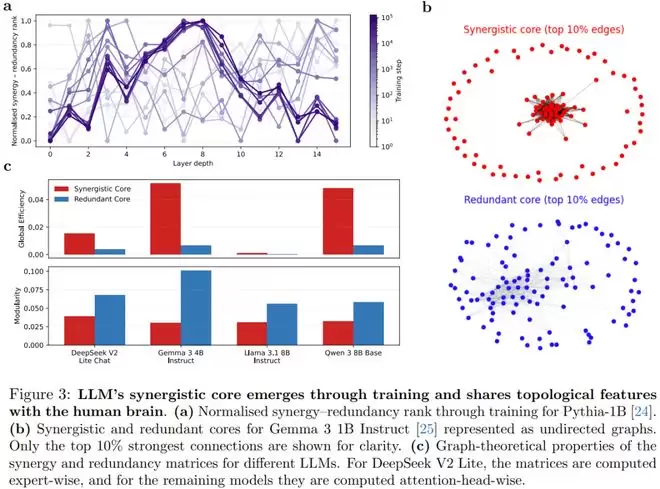
这意味着,协同核心是大模型获得能力的标志性产物。
在拓扑性质上,协同核心具有极高的「全局效率」,有利于信息的快速集成;而冗余外周则表现出更强的「模块化」,适用于专门化处理。这种特征再次与人类大脑的网络架构形成了精确的平行关系。
协同核心的功能验证
为了验证协同核心是否真的驱动了模型行为,研究团队进行了两类干预实验:消融实验和微调实验。
消融实验:研究发现,消融那些高协同性的节点,会导致模型出现灾难性的性能下降和行为背离,其影响远超随机消融或消融冗余节点。这证明协同核心是模型智能的核心驱动力。
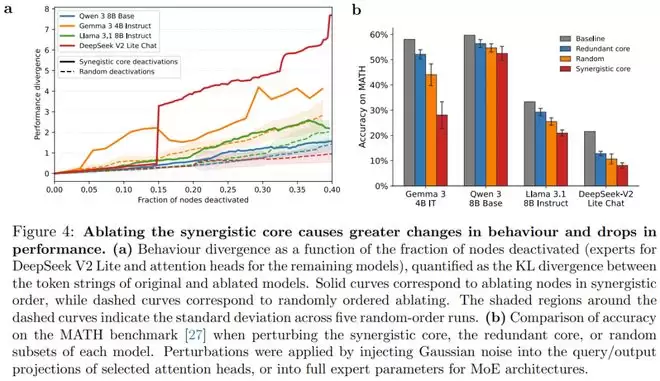
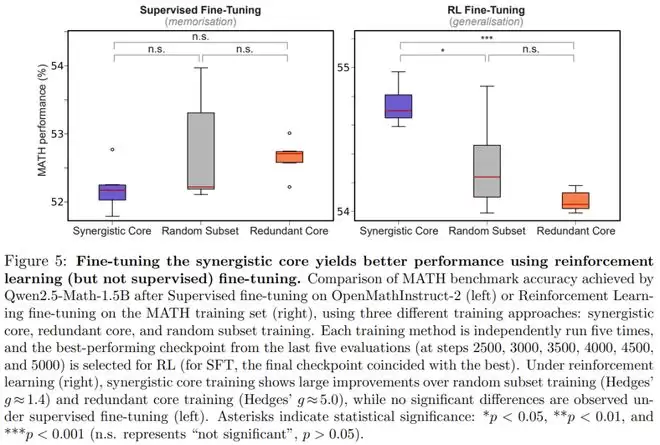
微调实验:在强化学习微调(RL FT)场景下,仅针对协同核心进行训练,获得的性能提升显著优于针对冗余核心或随机子集的训练。有趣的是,在监督微调(SFT)中这种差异并不明显。研究者认为,这反映了 RL 促进通用化而 SFT 更多倾向于记忆的特性。
结语
这项研究为大模型的可解释性开辟了新路径。它表明,我们可以从「自上而下」的信息论视角来理解模型,而不仅仅是「自下而上」地寻找特定的电路。
对于 AI 领域,识别协同核心有助于设计更高效的压缩算法,或者通过更有针对性的参数更新来加速训练。对于神经科学,这提供了一种计算上的验证,预示着协同回路在强化学习和知识迁移中可能扮演着至关重要的角色。
大模型虽然基于硅基芯片和反向传播算法,但在追求智能的过程中,它们似乎不约而同地走向了与生物大脑相似的组织模式。这种智能演化的趋同性,或许正是我们揭开通用智能奥秘的关键线索。
更多详情请参阅原论文。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

QoderWake数字分身动作捕捉与还原技术详解
QoderWake数字分身通过五大核心技术实现动作精准捕捉与还原。基于Session账本三维锚定行为轨迹,确保可追溯与复现。Harness-First架构隔离意图与执行,保障操作安全。Critic-Refiner机制自动验证动作质量并闭环纠偏。防腐治理动态评估动作有效性,防止模板老化。Connector生态建立跨工具动作映射,确保异构系统间操作一致。这些技术

简历工作经历优化技巧 AI助你告别流水账式写法
简历应避免流水账式经历和空洞评价。工作经历需用“动词+成果+数据”结构突出价值,如具体增长或性能提升数据。自我评价应基于事实,清晰展示核心优势与证明。AI工具可辅助优化结构,但关键数据、业务背景及岗位匹配逻辑需自行把控,核心在于用结果和证据展现个人价值。

阿里云发布全栈芯片路线图 平头哥真武M890性能提升三倍
阿里云推出平头哥新一代AI芯片真武M890,配备144GB显存,算力性能达上一代3倍,支撑智能体高频模型调用。该芯片已实战验证,未来将推出后续型号。平头哥坚持软硬一体策略,通义千问大模型在其上自主运行并实现性能提升,阿里云目标以此扩大AI市场份额。

QClaw培训考试试卷自动生成与评分操作指南
QClaw是一款自动化培训考试工具,通过微信指令驱动,可自动生成结构化Word试卷。它支持依据标准答案批改电子答卷并输出成绩表,还能通过OCR识别纸质答题卡图像,生成带批注的PDF和成绩汇总,实现从出题到评分的全流程自动化。

OpenClaw批量改写工具使用教程与技巧详解
实现OpenClaw批量内容改写需完成几个关键步骤:首先绑定支持长文本与重写的AI模型;其次构建YAML模板以约束语义、统一风格;接着通过命令行高效执行并发任务;还可利用协同工具进行审阅驱动式修改;最后能通过PythonSDK深度定制条件化改写逻辑,满足复杂需求。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
