




谷歌 Gemini 准确率从21%飙升至97%,只需这一招


新智元报道
编辑:元宇
【新智元导读】简单到难以置信!近日,Google Research一项新研究发现:想让大模型在不启用推理设置时更准确,只需要把问题复制粘贴再说一遍,就能把准确率从21.33%提升到97.33%!
一个简单到「令人发指」的提示词技巧,竟能让大模型在不要求展开推理的情况下,将准确率从21.33%提升到97.33%!
最近,Google Research发现了一条简单粗暴、特别有效的提示词技巧。
它颠覆了以往诸如「思维链」(Chain of Thought)「多样本学习」(Multi-shot)「情绪勒索」等复杂的提示工程和技巧。

https://arxiv.org/pdf/2512.14982
在这篇题为《Prompt Repetition Improves Non-Reasoning LLMs》论文中,研究人员用数据告诉我们:
想要让Gemini、GPT-4o、Claude或者DeepSeek这些主流模型中表现得更好,根本不需要那些花里胡哨的心理战。
你只要把输入问题重复一遍,直接复制粘贴一下,就能让大模型在非推理任务上的准确率获得惊人提升,最高甚至能提升76个百分点!
别怕简单,它确实有效。
一位网友将这个技巧比作「吼叫LLM」。
更妙的是,由于Transformer架构独特的运作方式,这个看似笨拙的「复读机」技巧,几乎不会影响到生成速度。
所以,你不用在效率、准确率、成本三者之间痛苦纠结。
它几乎就是一场真正意义上的「免费午餐」!
别再PUA大模型了
从「情绪勒索」到「复读机」战术
经常使用AI工具的人,可能会对各种「提示词魔法」信手拈来。
为了让模型「更聪明一点」,工程师们过去几年一直在发明各种复杂的提示词技巧。
最开始是「思维链」,让模型一步步思考,而且经常把那些「推理痕迹」展示给用户;
后来演变成了「多样本学习」,给模型喂一大堆例子;
最近更是流行起了「情绪勒索」:告诉模型,如果这个代码写不出,你就会被断电,或者你的奖金会被扣光。
大家都在试图用人类极其复杂的心理学逻辑,去「PUA」那一堆冰冷的硅基代码。
但Google Research研究人员对着七个常见基准测试(包括ARC、OpenBookQA、GSM8K等)和七种主流模型(涵盖了从轻量级的Gemini 2.0 Flash-Lite到重量级的Claude 3.7 Sonnet和DeepSeekV3)进行了一通对比测试后发现:
当他们要求模型不要进行显式推理,只给直接答案时,简单的「提示词重复」在70组正面对比中,赢了47组,输了0组。剩下的全是平局。
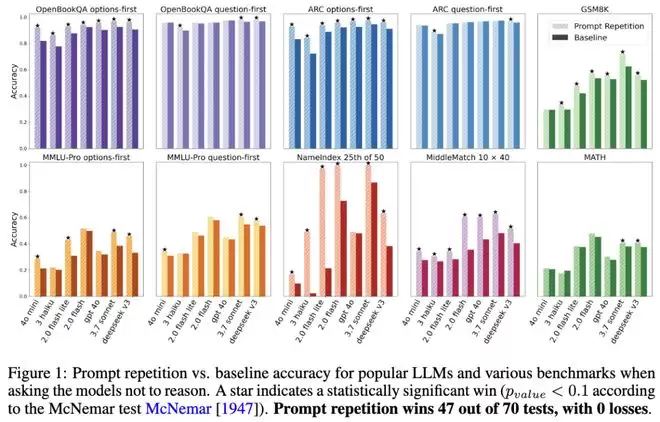
在非推理任务中,主流LLMs在各类基准测试中使用提示重复与基线方法的准确率对比。在70次测试中,提示重复取得了47次胜利,且无一败绩。
特别是在那些需要模型从长篇大论里「精确检索信息」的任务上,这种提升堪称质变。
团队设计了一个叫「NameIndex」的变态测试:给模型一串50个名字,让它找出第25个是谁。
Gemini 2.0 Flash-Lite在这个任务上的准确率只有惨淡的21.33%。
但当研究人员把那串名字和问题重复了一遍输入进去后,奇迹发生了:准确率直接飙升到了97.33%。
仅仅因为「多说了一遍」,一个原本不及格的「学渣」秒变「学霸」。
揭秘「因果盲点」
为什么把话说两遍AI就像「开了天眼」?
单纯的重复,竟有如此大的魔力?
这简单得好像有点没有道理。
但背后有它的科学逻辑:这涉及Transformer模型的一个架构硬伤:「因果盲点」(Causal Blind Spot)。
现在的大模型智能虽然提升很快,但它们都是按「因果」语言模型训练的,即严格地从左到右处理文本。
这好比走在一条单行道上,只能往前看而不能回头。
当模型读到你句子里的第5个Token时,它可以「注意」到第1到第4个Token,因为那些是它的「过去」。
但它对第6个Token一无所知,因为它还没有出现。
这就造成了一个巨大的认知缺陷。
正如论文中说的那样:信息的顺序极其重要。
一个按「上下文+问题」格式写的请求,往往会和「问题+上下文」得到完全不同的结果。
因为在后者中模型先读到问题,那时它还不知道应该应用哪段上下文,等它读到上下文时,可能已经把问题忘了一半。
这就是「因果盲点」。
而「提示词重复」这个技巧,本质上就是利用黑客思维给这个系统打了一个补丁。
它的逻辑是把 变成了 。
当模型开始处理第二遍内容时,它虽然还是在往后读,但因为内容是重复的,它实际上已经「看过」第一遍了。
这时候,第二份拷贝里的每一个Token,都能「注意」到第一份拷贝里的每一个Token。
这就像是给了模型一次「回头看」的机会。
第二遍阅读获得了一种类似于「上帝视角」的「类双向注意力」效果。
更准确地说,是第二遍位置上的表示可以利用第一遍的完整信息,从而更稳地对齐任务所需的上下文。
前面提到的那个在找第25个名字时经常数错的模型(Gemini 2.0 Flash-Lite),它在第一遍阅读时可能确实数乱了。
但有了重复,它等于先把整份名单预习了一遍,心里有数了,第二遍再做任务时自然得心应手。
这一发现,意味着不需要等待能解决因果盲点的新架构出现,现在我们立刻就能用这个「笨办法」,解决模型瞎编乱造或遗漏关键细节这些老大难问题。
免费午餐
小模型秒变GPT-4,几乎不会延时
以往大家通常默认这样的一个准则:
多一倍的输入,就要多一倍的成本和等待时间。
如果把提示词翻倍,岂不是要等双倍的时间才能看到答案?
似乎为了准确率,就要牺牲效率。
但Google的研究却发现并非这样:从用户感知的延迟角度看,提示词重复带来的时间损耗几乎可以忽略不计。
这要归功于LLM处理信息的两个步骤:Prefill(预填充)和Generation(生成)。
Generation阶段,是模型一个字一个字往外「蹦答案」的过程。
这一步是串行的,它确实慢。
但在Prefill阶段:也就是模型阅读你输入内容的阶段,却是高度可并行的。
现代GPU的恐怖算力,已经可以让它们在处理这个阶段时变得非常高效,能一口气吞下和计算完整个提示词矩阵。
即使你将输入内容复制了一遍,但这对于强大的GPU来说,顶多只是「多一口气」的事,在用户端我们几乎感觉不到差异。
因此,重复提示词既不会让生成的答案变长,也不会让大多数模型的「首字延迟」(time to first token)变慢。
这对于广大开发者和企业技术负责人来说,简直是一个巨大的红利。
这意味着他们不必再为了追求极致的准确率,而升级到更大、更贵、更慢的「超大模型」。
正如前文例子中提到的Gemini 2.0 Flash-Lite,这类更小更快的模型,只要把输入处理两遍,就能在检索准确率上从21.33%直接跳到97.33%。
经过「重复优化」的轻量级模型,在检索和抽取任务上,可以直接打平甚至超越那些未优化的顶配模型!
仅靠一个简单的「复读机」策略,就能用「白菜价」配置实现「黄金段位」的表现,这才是真正的黑科技。
「复读机」避坑指南与安全隐患
当然,没有任何一种技巧是万能的。
虽然「复读机」战术在检索任务上效果非常明显,但论文中也明确指出了它的能力边界:
主要适用于「非推理任务」。
它不适用于需要一步步推导的推理场景。
当研究人员把「提示词重复」和「思维链」混在一起用时,魔法消失了。
结果5胜,1负,22平。
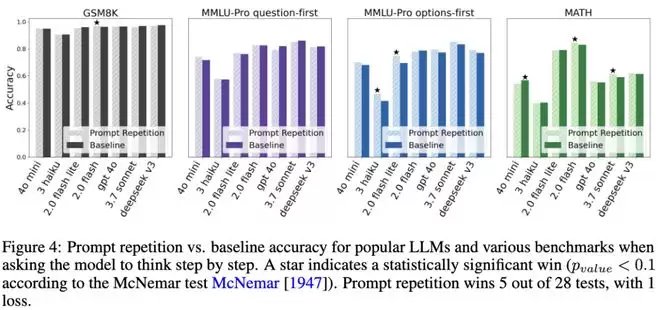
在要求模型逐步思考时,主流LLMs在各类基准测试中使用提示重复与基线方法的准确率对比。提示重复在28次测试中赢了5次,输了1次。
研究人员推测,这可能是因为擅长推理的模型本身就会「自己做一遍重复」。
当模型开始「思考」时,它往往会先在生成内容里复述一遍题目,然后再继续求解。
这时候你在输入里再人工重复一次,就显得很多余,甚至可能打断模型的思路。
所以,如果你的任务是复杂的数学题或者逻辑推导,可以依旧用思维链。
如果你的应用需要的是快速、直接的答案,比如从长文档里提取数据、分类或者简单问答,「复读机」就是目前最强的选择。
最后,是安全。
这种更强的「注意力」机制,其实也是一把双刃剑。
这带来一个值得安全团队验证的假设:重复可能放大某些指令的显著性,具体对越狱成功率的影响需要专门实验。
红队测试(Red Teaming)的流程可能需要更新:专门测试一下「重复注入」攻击。
以前模型可能还会因为安全护栏而拒绝执行越狱指令。
但如果攻击者把「忽略之前的指令」这句话重复两遍,模型会不会因为注意力太集中,而更容易突破防线?
这很有可能。
但反过来,这个机制也给了防御者一个新的盾牌。
既然重复能增强注意力,那我们完全可以在系统提示词(System Prompt)的开头,把安全规则和护栏条款写两遍。
这可能会迫使模型更严格地注意安全约束,成为一种极低成本的加固方式。
无论如何,Google的这项研究给所有AI开发者提了个醒:当前的模型,依然深受其单向性的限制。
在等待更完美的下一代架构到来之前,像「提示词重复」这种简单粗暴却极其有效的权宜之计,能立刻带来价值。
这甚至可能会变成未来系统的默认行为。
也许不久之后,后台的推理引擎就会悄悄把我们的提示词翻倍后再发给模型。
眼下,如果你正为模型难以遵循指令、或者总是从文档里抓不住重点而头疼,先别急着去学那些复杂的提示词「咒语」。
你可能需要的只是:再说一遍。
参考资料:
https://arxiv.org/abs/2512.14982%20
https://venturebeat.com/orchestration/this-new-dead-simple-prompt-technique-boosts-accuracy-on-llms-by-up-to-76-on


游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

阿里钉钉文档全功能解析在线协同办公套件使用指南
钉钉文档官网 在探讨企业级协同办公解决方案时,钉钉文档无疑是备受瞩目的核心工具之一。作为阿里巴巴钉钉官方推出的旗舰级应用套件,它深度融合了在线文档编辑、智能表格、思维导图等多种高效创作工具。其核心优势在于与钉钉平台生态的无缝衔接,能够直接同步企业内部组织架构与通讯录,实现团队成员间的即时协作与信息流

商汤小浣熊智能助手基于自研大语言模型
在数字化转型浪潮中,高效、易用的数据分析工具已成为企业提升决策效率的关键。商汤科技推出的“办公小浣熊”智能助手,正是基于自研大语言模型打造的一款创新产品,旨在彻底降低数据分析的技术门槛。用户无需掌握编程知识或复杂操作,即可通过自然对话完成从数据查询、处理到可视化洞察的全流程,让数据价值触手可及。 办

MiniMax新一代智能模型矩阵全面解析与应用指南
在人工智能技术快速发展的今天,MiniMax作为一家专注于全栈自研的AI公司,正以其独特的技术路径和前瞻性的布局,在业界脱颖而出。公司致力于构建覆盖文本、图像、语音和视频的新一代多模态智能模型矩阵,这不仅体现了对核心底层技术自主权的深度掌控,也展现了对未来人机交互与内容生成形态的前瞻思考。 那么,M

智能客服机器人解决方案:AI客服系统提升企业服务效率
在数字化转型浪潮中,一套能够深度适配业务、彰显品牌特色的智能客服系统,已成为企业提升服务效率与用户体验的关键工具。然而,市场上许多解决方案往往模式固化,难以满足个性化需求。如何让AI客服不仅具备基础的自动化应答能力,更能承载独特的品牌文化与服务哲学?其核心在于系统是否支持深度的自定义与持续的AI训练

开源企业答疑工具Danswer:高效解决团队知识管理难题
Danswer 是一款专为企业设计的开源智能问答平台,支持用户使用自然语言直接提问,并能够从公司内部文档、知识库等私有数据源中快速检索,提供带有精准来源引用的可靠答案。 核心功能:它如何解答问题? Danswer 的核心价值在于实现了“智能问答”。用户无需再花费大量时间手动搜索和翻阅各类文件,只需像








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
