




开源模型小钢炮登场!10B多模态屠榜,性能超越巨型系统20倍

智东西
作者 程茜
编辑 李水青
智东西1月20日报道,今日下午,阶跃星辰开源多模态模型Step3-VL-10B。该模型参数量为10B,在视觉感知、逻辑推理、数学竞赛以及通用对话等一系列基准测试中均达到同规模SOTA水平。
阶跃星辰的多项测评显示,Step3-VL-10B的性能可以媲美甚至超越规模大10-20倍的开源模型,如GLM-4.6V 106B-A12B、Qwen3-VL-Thinking 235B-A22B以及闭源旗舰模型,如Gemini 2.5 Pro、Seed-1.5-VL。
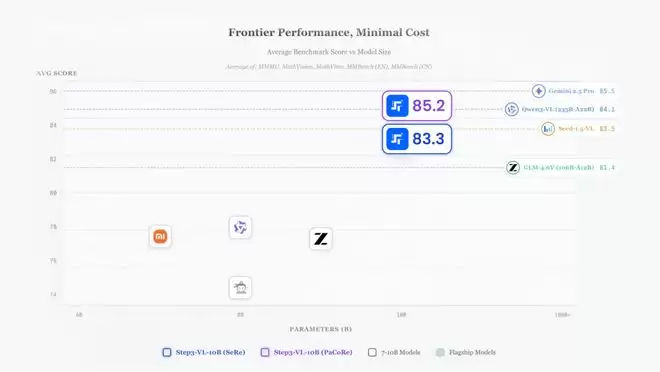
这一轻量级模型的性能表现,也意味着手机、电脑、工业嵌入式设备也可以运行GUI操作、复杂文档解析、高精度计数等复杂多模态推理任务。
从技术层面看,Step3-VL-10B的性能突破得益于三个关键设计,分别是高质量多模态语料库上进行统一预训练、缩放多模态强化学习、并行协调推理机制。
目前,阶跃星辰已开源Step3-VL-10B系列的Base模型和Thinking模型。
Hugging Face开源地址:https://huggingface.co/collections/stepfun-ai/step3-vl-10b
ModelScope开源地址:https://modelscope.cn/collections/stepfun-ai/Step3-VL-10B
体验地址:https://huggingface.co/spaces/stepfun-ai/Step3-VL-10B
技术报告链接:https://arxiv.org/pdf/2601.09668
一、从GUI感知到视觉识别和推理,Step3-VL-10B思路清晰
阶跃星辰在最新公众号里放出了Step3-VL-10B在多模推理能力方面的真实案例。
首先是关于摩尔斯编码的推理,可以看到模型的思考过程思路清晰,先拆解字母再逐个查表,最后拼接,流程正确,并且对大部分字母如S、T、E、F、U、N的定位和编码描述准确。

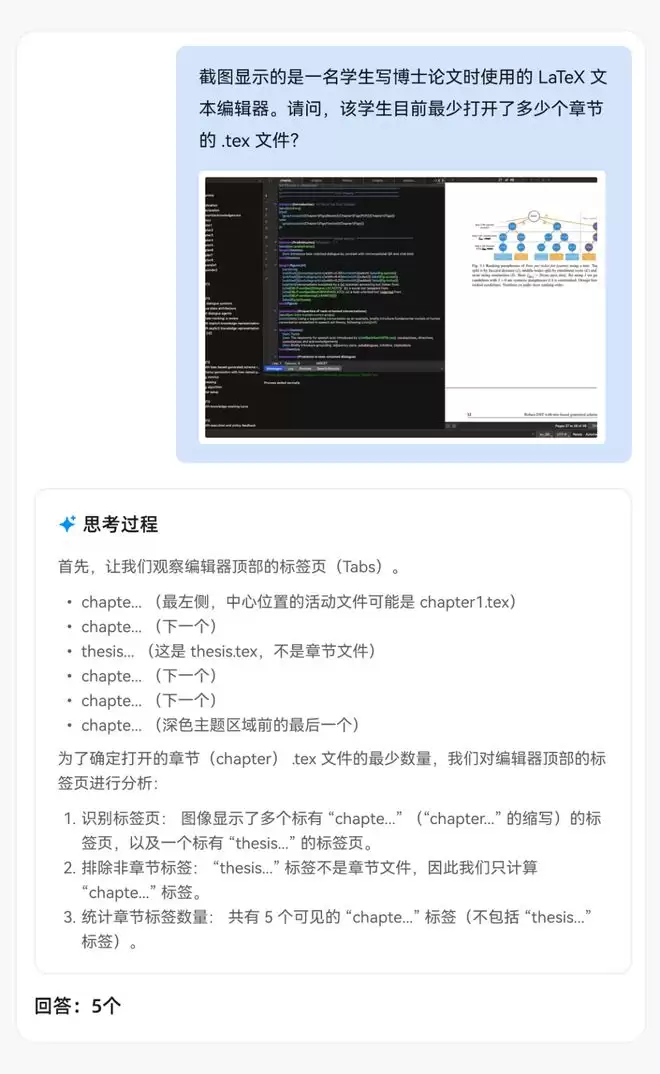
其次是GUI感知能力,模型需要识别标签页中以章节开头.tex结尾的文件标签,可以看到其思考过程采用了识别标签、排除非目标、统计数量的步骤进行了准确分析,并有效规避了干扰选项。
第三个是关于图推理的案例,模型需要在连线非常复杂的图片中准确识别中长度最短的图有几条,从思考过程可以看到,其先确认了最小权重的边长度是1,然后再统计所有权重为1的边。

二、拿下开源SOTA,数学竞赛测试题超94分
Step3-VL-10B具备三大核心亮点:
视觉感知精度更高:在同参数量级中展现出顶尖的识别与感知精度,研究人员为其引入PaCoRe(并行协调推理)机制,模型在复杂计数、高精度OCR及空间拓扑理解等高难度任务上的可靠性提升。
深层逻辑推演与长程推理:得益于规模化强化学习(RL)的持续迭代,Step3-VL-10B在10B规模上能应对竞赛级数学难题、真实编程环境、视觉逻辑谜题。
端侧Agent交互:基于海量GUI(图形用户界面)专用预训练数据,模型能够精准识别并操作复杂界面。
阶跃星辰公开的多模态基准测试结果显示,Step3-VL-10B是10B参数类别中最强大的开源模型。
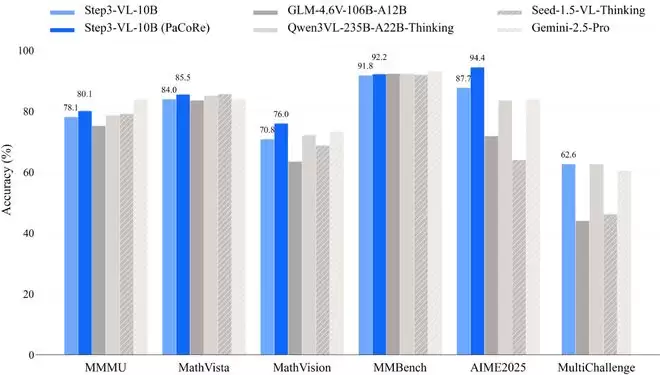
具体来看,在多模态推理能力上,Step3-VL-10B在部分测试集上超越了GLM-4.6V、Qwen3-VL等模型,其性能优于10倍至20倍大的模型。
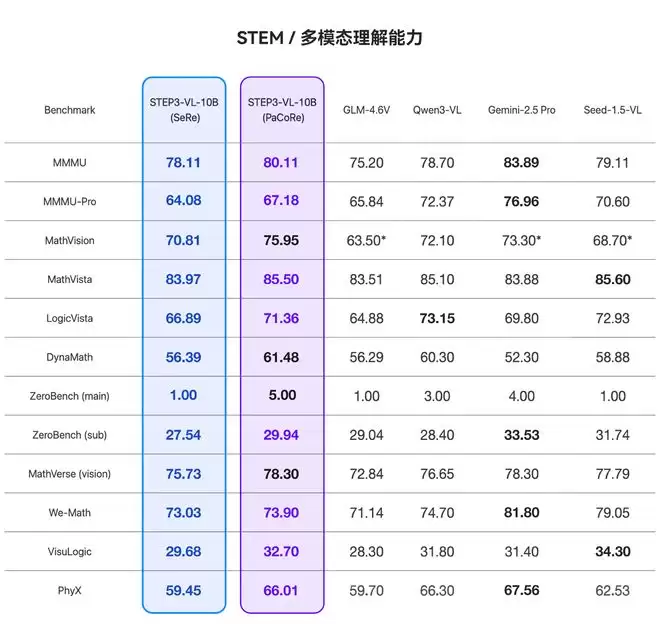
数学能力方面,该模型在AIME 25/24等数学竞赛测试题上得分超过94分,这意味着其在逻辑严密性上甚至优于许多千亿级模型。
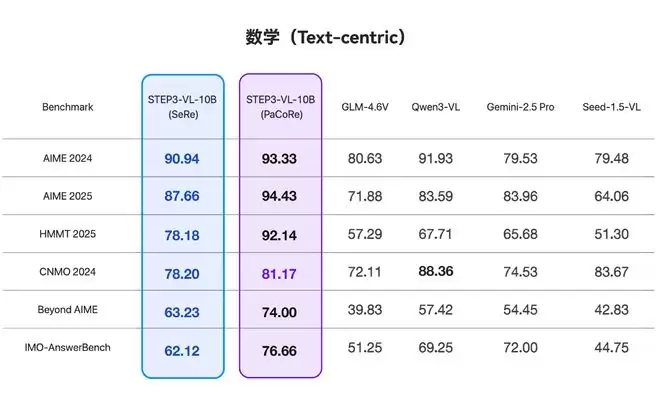
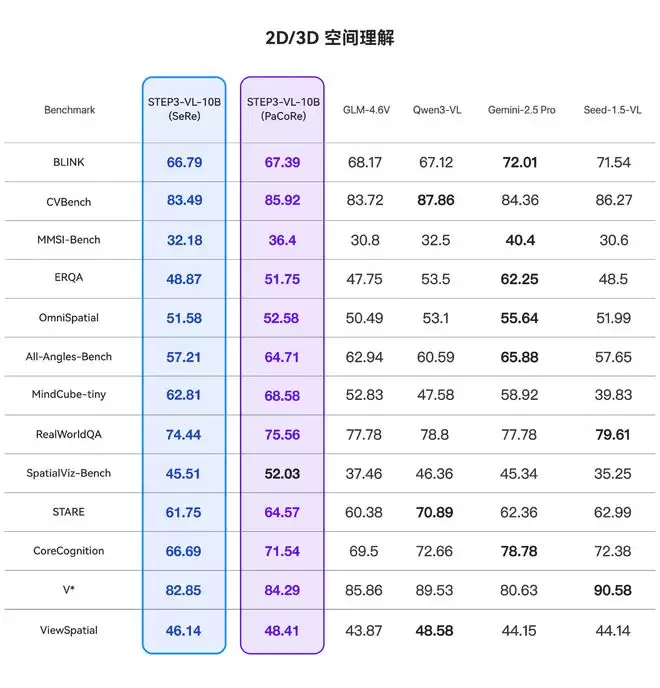
2D、3D空间推理能力上,模型在BLINK上表现出66.79%的涌现式空间意识,在All-Angles-Bench上达到57.21%,意味着该模型在具身智能应用方面具有强大的潜力。
最后是编程能力,在真实、动态编程环境下,Step3-VL-10B超越GLM-4.6V、Qwen3-VL等模型。

此外,该模型的开源主页显示,研究人员在Qwen3VL-8B相关的基准测试中出现了不准确数据,例如AIME、HMMT、LCB,目前正在修复。这些错误是由于其在大规模评估过程中max_tokens设置错误造成,他们将重新运行测试,并在下一版技术报告中提供修正后的数据。
三、从感知到推理双提升,三大关键设计加持
该模型的论文提到,Step3-VL-10B的性能突破得益于三个关键设计:
一是在高质量多模态语料库上进行统一预训练:研究人员采用单阶段、完全解冻的训练策略,在1.2T token的多模态语料库上进行训练,重点关注两大基础能力:推理和感知,例如通用知识和教育中心任务等推理能力,定位、计数、OCR和GUI交互等感知能力。
通过联合优化感知编码器和Qwen3-8B解码器,STEP3-VL-10B建立了内在的视觉-语言协同效应。
二是缩放多模态强化学习:通过一个严格的后训练流程解锁了前沿能力,该流程包括两阶段监督微调(SFT)以及超过1400次的强化学习迭代,结合可验证奖励(RLVR)和人类反馈(RLHF)。
三是并行协调推理机制:研究人员采用并行协调推理(PaCoRe),支持推理阶段的动态算力扩展。通过并行探索多个感知假设并进行多维证据聚合,该机制显著提升了模型在竞赛级数学、复杂OCR识别、精准物体计数及空间拓扑推理中的准确度。
阶跃星辰的最新公众号提到,得益于“三位一体”架构,Step3-VL-10B证明智能水平并不完全取决于参数规模。这也意味着:世界一流的多模态能力有望以更低成本、更少算力获得;与此同时,过去主要集中在云端超级智能将逐步向端侧下沉,推动终端走向“主动理解与可执行交互”。
结语:Step3-VL-10B或成端侧AI新选择
从Step3-VL-10B的实测可以看出,该模型凭借10B轻量化参数体量,通过高质量多模态语料统一预训练、千余次强化学习迭代及并行协调推理机制,实现了对超大规模模型的跨级性能追赶。
并且具体到GUI交互、精准计数、竞赛级数学推理等任务,该模型也展现出较大应用潜力,未来有望降低在工业质检、本地文档分析、基层医疗辅助等场景的部署门槛。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

全国首个人形机器人管理平台在京上线实现全流程追溯
全国首个人形机器人全生命周期管理平台在京发布,为每台机器人赋予终身唯一编码作为“数字身份证”。该平台由工信部下属委员会牵头,已接入超百家企业,覆盖2 8万余台机器人,实现从生产到回收的全流程可追溯,旨在推动产业规范、协同发展。

温州AI赋能时尚产业升级转型新路径
温州鞋服产业正经历AI驱动的系统性变革,AI已深入设计、生产、管理及营销全链条,成为核心生产力。企业通过AI设计系统快速生成方案,利用智能设备提升制造精度与检测效率,并借助垂直大模型优化决策。柔性生产线与智能裁床支持个性化定制与快速响应,切实转化为产业竞争力,推动传统制造。

北科大本科扩招90人新增知识产权专业首次招生
北京科技大学本科扩招90人,新增知识产权与集成电路设计专业,聚焦国家急需的新工科与复合型人才培养。学校推行全程导师制与“本硕贯通”培养,并实施“人工智能+”教育行动。国际化方面新增中外合作办学专业,同时实行“零调剂”等灵活政策。本科生深造率超60%,就业集中于国家重点行业领域。

微软Fara1.5浏览器AI模型发布 任务成功率72%超越OpenAI
微软发布专为浏览器设计的Fara1 5系列AI智能体模型,包含4B、9B和27B三个版本。该模型基于Qwen3 5构建,通过观察浏览器截图输出操作指令,采用“观察—思考—行动”循环决策。在Online-Mind2Web基准测试中,Fara1 5-27B任务成功率达72%,超越多款主流模型。其训练使用了约200万条混合数据,并设计了在信息缺失、任务模糊或执行不

人工智能如何推动自动驾驶技术突破与发展
近年来,人工智能技术深刻变革着各行各业,其中自动驾驶领域受益尤为显著。技术的快速演进,正重新定义“驾驶”的体验与边界。那么,AI技术究竟如何驱动自动驾驶发展?行业专家分享了最新的趋势洞察与前沿观点。 纯视觉方案:低成本与高信息密度的技术路径 在自动驾驶感知技术路线中,激光雷达与纯视觉方案的对比一直是








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
