




代码泄露曝DeepSeek下一代“王炸”模型架构细节


智东西
作者 江宇
编辑 冰倩
智东西1月21日报道,DeepSeek-R1发布一周年之际,来自DeepSeek的神秘新模型“MODEL1”悄然现身GitHub代码库。
多位社区开发者推测,MODEL1很可能正是DeepSeek内测中的V3终极版本(V4模型),也有人猜测它可能代表一个完全独立于V系列的新模型。
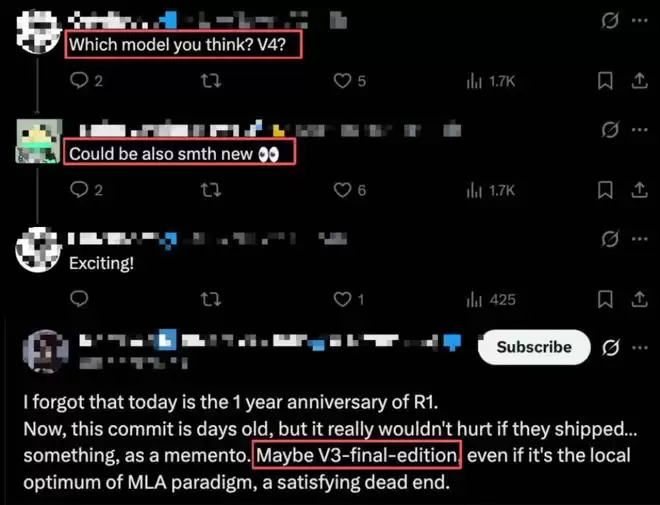
▲海外开发者在X平台讨论MODEL1身份
近日,DeepSeek向其核心推理内核FlashMLA推送了一系列更新,而在这些提交中,一个此前从未公开亮相的模型命名引发了社区的高度关注——MODEL1。
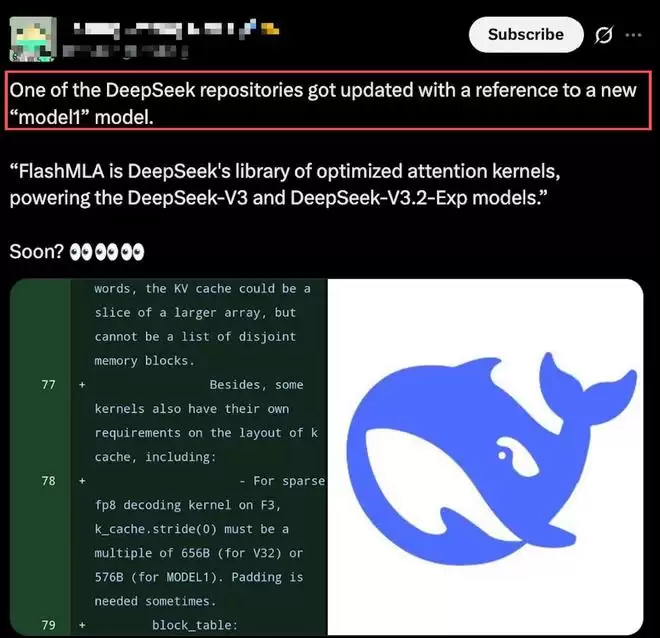
▲DeepSeek代码库出现MODEL1相关(图源:X)
这一名称不仅出现在SM90架构相关的.cu内核实例化文件中,还贯穿在多个针对FP8稀疏解码路径的模板定义与内存布局注释里。
更关键的是,据海外开发者推测,MODEL1的背后将是一整套新的推理机制、算子结构与底层内存配置,会与DeepSeek现有V3.2模型呈现出完全不同的技术路径。
在相关代码文件中可以看到,MODEL1被用于核心解码函数的多个实例中,显式适配了头维度为64和128的场景,并专门部署在SM90和SM100架构上。
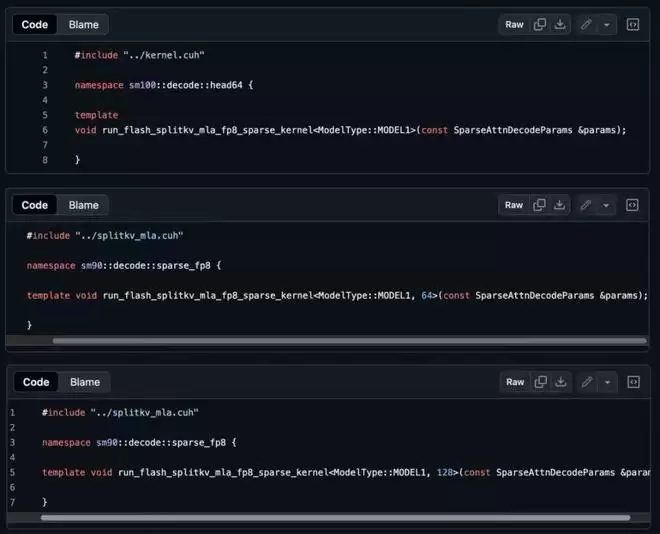
▲DeepSeek FlashMLA源码截图(图源:GItHub)
代码中多处调用了“ModelType::MODEL1”,与其对应的还有一套独立的持久化内核。这些文件与V32版本的持久化内核文件并行存在,这显示出DeepSeek或许已为该模型设计了与V3系列完全不同的编译路径与执行逻辑。
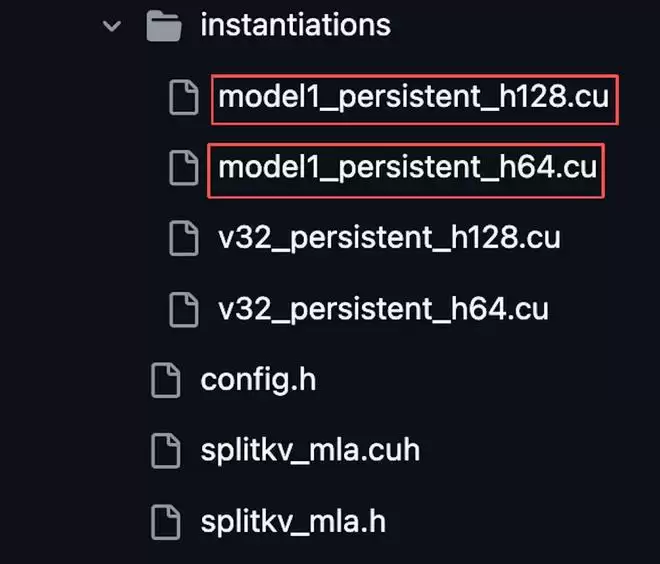
▲DeepSeek FlashMLA源码文件树(图源:GItHub)
更值得注意的是,在代码中,有一条特别注释写道:对于F3架构(即SM90平台)下的MODEL1模型,其KV缓存的内存stride必须是576B的整数倍。
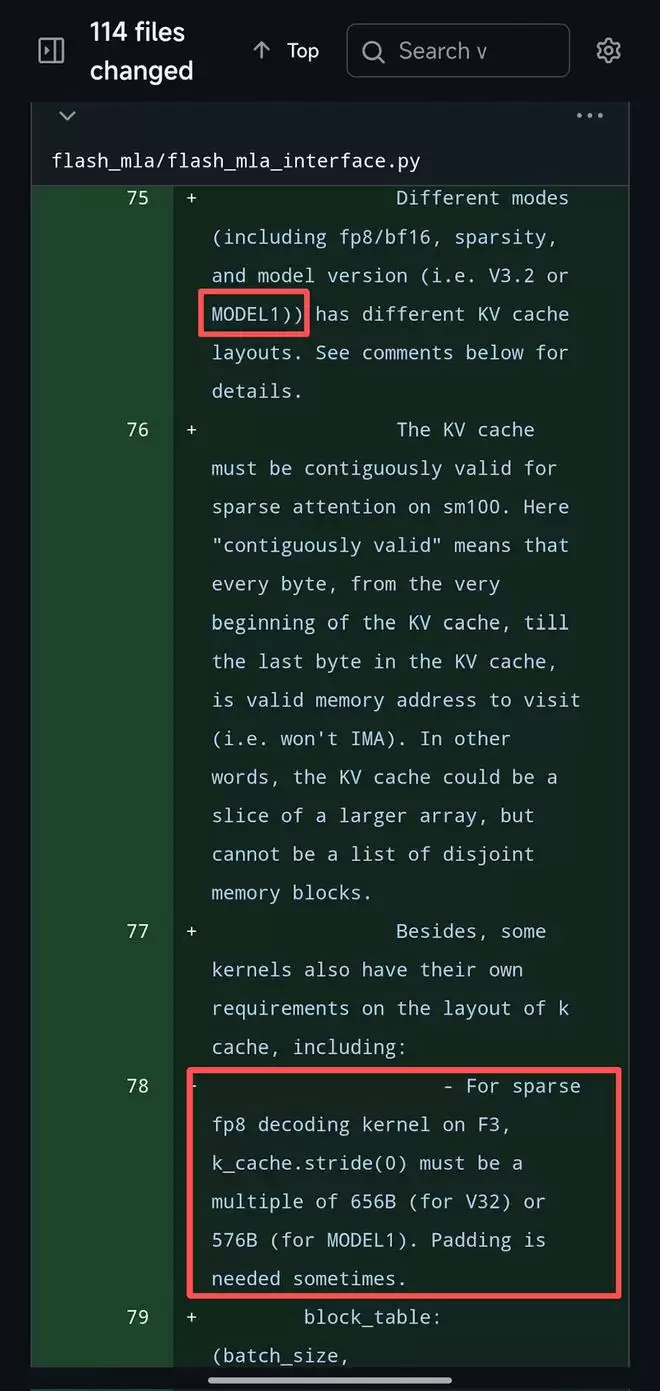
▲海外网友推文截图(目前该条注释已于代码库内删除)
这一配置区别于V3.2的656B,暗示着MODEL1对底层内存对齐和调度有更为严格的要求,可能与其更复杂的运行时行为与动态缓存机制有关。
一位海外网友也对这部分代码进行了深入解读,他认为,MODEL1在整体结构上展现出更强的实验性特征,支持动态Top-K稀疏推理逻辑,还引入了额外的KV缓存区。
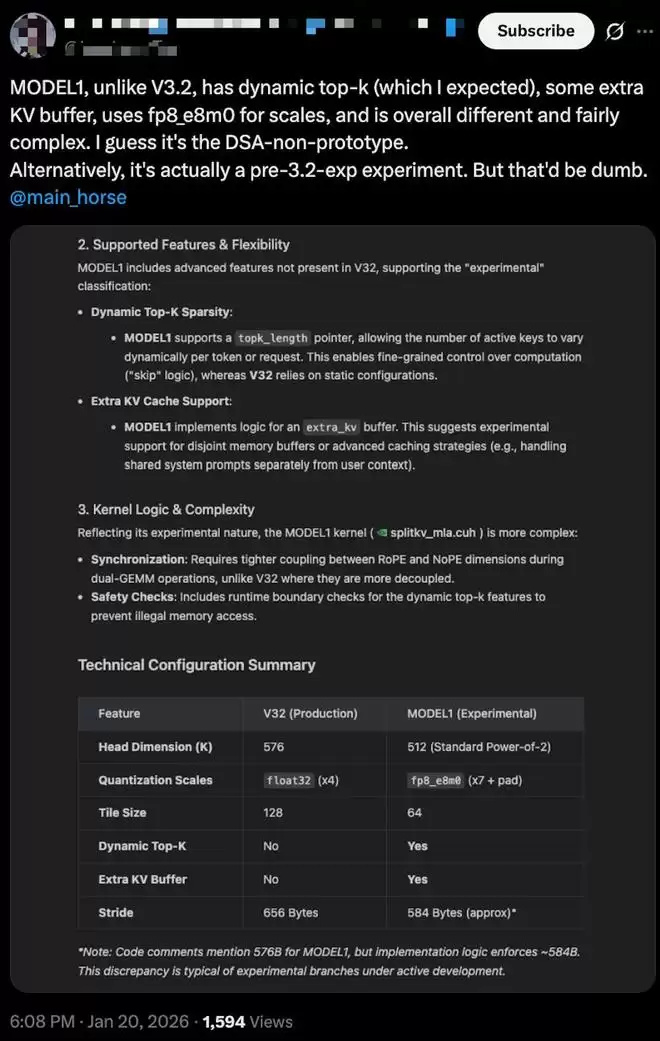
▲海外开发者的分析(图源:X)
前者通过引入一个可变的topk_length指针,允许模型在推理时根据token或请求动态决定参与计算的key数量,提升了计算资源的精细调度能力;后者则通过extra_kv缓冲区,提供了将系统提示与用户上下文分离存储的可能,为Agent架构或多段上下文场景提供支持。
据社区开发者分析,MODEL1在同步逻辑与边界控制上可能比V3.2更加复杂。其中RoPE与NoPE维度在双GEMM运算中耦合更紧,可能意味着其在位置编码与张量路径调度上做出了显著调整。
分析还提到,MODEL1引入了运行时边界检查机制,旨在规避动态Top-K推理中潜在的非法内存访问。
此外,尽管最新注释中标明MODEL1的stride应为576B,但据社区开发者基于代码结构估算,其实际内存分配逻辑可能接近584B。这种细微差异被认为反映出该分支仍处于调试或快速迭代阶段。
在更早的1月9日,外媒援引知情人士称,DeepSeek将于2月中旬,也就是春节前后发布其下一代模型,主打编程能力,并在内部测试中已经在多个基准上超越了Claude与GPT系列。
结合目前模型文件结构已覆盖64和128两个头维度、FP8稀疏解码路径已完成适配、内存规范已强制定义等迹象来看,MODEL1很可能已接近训练完成或推理部署阶段,正等待最终的权重冻结和测试验证。
在海外社交平台上,不少用户对MODEL1的曝光反应热烈。一位用户调侃道:“我已经能听见‘新模型将带来99.97%成本下降’了。”

而另一位开发者则认为,如果DeepSeek再次开放权重,势必将对闭源巨头形成压力,推动前沿模型进一步走向开放。

恰逢DeepSeek R1发布一周年,Hugging Face最新博客也发布了特别文章《One Year Since the “DeepSeek Moment”》,系统回顾了过去一年中国开源社区的集体爆发,明确提及DeepSeek的开源策略已从一次事件演化为生态策略。

▲Hugging Face最新博客:One Year Since the “DeepSeek Moment”
文章称,R1模型的开源不仅降低了推理技术、生产部署与心理三个门槛,更推动了国内公司在开源方向上形成非协同但高度一致的战略走向。
从百度、字节跳动到月之暗面、智谱AI,各大机构在过去一年中陆续加入Hugging Face并发布高质量模型,在社区下载、点赞与引用榜单上频频登顶。
与此同时,越来越多西方开源模型的底座也开始使用DeepSeek系列做微调,DeepSeek-V3更是成为Cogito v2.1等海外模型的底层基座。
结语:一年之后,DeepSeek再次站在开源演进的起点
如今,距离R1发布仅一年,DeepSeek的“MODEL1”很有可能在系统架构、执行路径与推理机制上展现出全面超越V3.2的能力。
如果接下来如传闻所述在春节前后正式发布,DeepSeek或许将再次改写国内开源格局,也可能为全球前沿开源模型树立新的标杆。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

2026北京车展荣威家越07概念车首发 AI赋能家庭出行新方案
在2026北京国际汽车展览会上,上汽荣威正式发布了其全新“家越”序列的首款概念车型——家越07。作为一款定位大五座的智能SUV,它精准聚焦于AI技术深度赋能的家庭出行场景,通过创新的设计语言与深度融合的智能科技,旨在重新定义家用汽车的功能边界与体验标准。根据官方规划,家越07的量产版本将于今年6月正

吉利银河M9黑金智曜版上市 豪华智能大六座SUV驾控体验升级
吉利银河旗下备受瞩目的AI科技大六座旗舰SUV——银河M9黑金智曜版,现已正式上市。新车官方指导价为26 98万元,并推出限时先享价25 98万元,同时附赠价值丰厚的购车权益。作为现款银河M9的进阶版本,这款新车在豪华设计、智能驾驶与驾控性能三大核心维度实现了显著升级,其目标清晰:旨在进一步夯实其在

淘宝天猫上线AI假图识别模型维护商家权益
在电商行业竞争日益激烈的今天,买卖双方的权益平衡始终是平台治理的核心。然而,近年来出现了一种新型的不当牟利手段,令众多商家倍感困扰——部分消费者利用人工智能(AI)技术生成的虚假图片作为所谓“证据”,在申请售后时提出“仅退款”而拒绝退货,企图空手套白狼,导致商家遭受不必要的经济损失。 面对这种利用高

Canva可画免费在线设计工具使用指南
不少朋友都在问,Canva可画这个在线设计工具的免费体验入口到底在哪?其实,它的官方地址一直很稳定。下面,我们就来全面梳理一下这个平台的核心功能与使用体验。 模板资源:覆盖全面,深度优化 首先,它的模板库确实够广。从节日庆典、职场办公到教育课件、社交媒体和电商海报,数十个主题场景下还有上百个细分方向

视觉生成模型对齐新方法TGO无需偏好对仅用标量反馈
新加坡国立大学团队提出TGO方法,无需依赖成对偏好数据,可直接利用单个样本的标量评分优化视觉生成模型。该方法通过估计分数阈值划分伪正负例,并依分数距离加权训练,在图像与视频生成任务中有效提升性能,为利用真实场景标量反馈提供了新途径。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
