




量子计算瓶颈:处理器再快,也需应对数据延迟难题

【文 观察者网专栏作者 徐令予】 关于量子计算的争论,大多在量子比特的数字游戏与工程实现的泥潭中打转。公众叙事中默认了一个近乎迷信的前提:只要处理器足够快,算力便会如期而至。然而,这个在计算技术发
【文/观察者网专栏作者 徐令予】
关于量子计算的争论,大多在量子比特的数字游戏与工程实现的泥潭中打转。公众叙事中默认了一个近乎迷信的前提:只要处理器足够快,算力便会如期而至。然而,这个在计算技术发展史中早已被证伪的命题,正借着量子的外壳重新还魂。
现代计算的战场,不在于运算本身,而在于数据的“搬运”与“等待”。 过去数十年取得的算力红利,其实主要来自数据调度与存储架构的持续演进。英伟达的黄仁勋在2026年CES展会上强调指出:当前AI算力的瓶颈已从传统的算术计算单元扩展到内存带宽、数据移动效率及系统级延迟,这源于AI模型规模的指数级增长和物理AI对实时性的严苛要求。
本文并非试图否定量子计算的研究价值,而是希望从计算体系结构与算力本体的角度,重新审视量子计算的技术承诺。文章将首先澄清“算力并不等同于处理器速度”这一常被忽视的基本事实,继而讨论量子计算在存储与数据调度层面所面临的结构性约束,从而为当前量子计算的争议提供一个新的视角。

一、算力不只是处理器速度,内存往往才是决定因素。
在关于计算能力的讨论中,长期存在一个误区:算力等同于中央处理器(CPU)的运算速度。这种理解或许符合人们对“计算”的朴素想象,却并不符合现代计算机系统的真实状况。当代计算计的性能瓶颈往往并不来自CPU本身,而是来自数据的存储、调度与访问。
这一事实是由数字计算机的基本结构所决定。经典的冯·诺依曼计算机结构,将计算系统明确划分为处理单元、存储单元以及连接二者的数据通道。程序与数据统一存储于内存,处理器必须通过有限带宽与内存交换信息。这一结构性安排决定了一个基本事实:处理器再快,也必须等待数据——这就是绕不开的“内存瓶颈”(Memory Wall)。
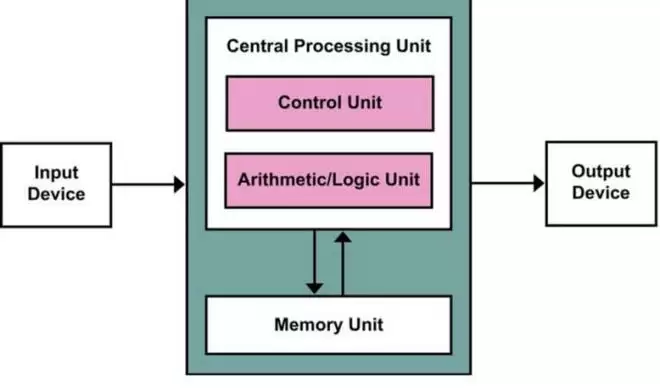
从更深一层看,现代计算对算力的巨大需求,并不源于对单一数据的反复计算,而是源于所需处理的数据规模持续增长。在计算复杂度研究中,问题的核心始终是当规模参数 (N) 增大时,系统如何应对由此带来的运算、存储与访问的总体负担。无论是数值计算、搜索问题,还是近年来迅速发展的机器学习,其难点往往并不在于“如何算得更快”,而在于“如何处理不断增长的数据量”。
这一趋势在大语言模型等人工智能系统中表现得尤为突出。当前主流模型的参数规模已达到数百亿乃至上千亿量级,模型训练与推理的主要挑战,早已不再是算术操作的速度,而是如此庞大的参数与中间状态能否被有效存放、调动并高效访问。正是在这一意义上,内存容量与存取速度,便成为了算力上升的天花板。
由此,现代计算机体系结构的核心进展,主要体现在缓存层级、内存带宽优化、数据局部性设计以及分布式存储等围绕“存储—计算协同”的工程创新,而非单纯提升CPU 的速度。这一现实在当下的人工智能计算中体现得尤为清楚。在大规模模型训练的工程实践中,超过一半的时间与能耗并不发生在算术运算本身,而是消耗在参数与激活值的读写、不同存储层级之间的数据搬运,以及跨节点同步等与存储和通信相关的环节上。
由此可见,算力从来不是一个孤立的“速度指标”,而是一种系统能力。它取决于信息能否被稳定存储、快速调度并反复利用。任何脱离存储条件谈论算力其实都是不切实际的空想。正是在这一意义上,理解内存在计算体系中的核心地位,构成了重新评估包括量子计算在内的一切算力承诺的必要前提。
二、量子计算仍然离不开经典内存,而且问题更严苛、更复杂。
量子处理器门操作速度的提升,并不能自动转化为可持续的算力增长,算力是否能够真正释放,最终仍取决于数据能否被高效地保存、调度与访问。量子计算不仅无法摆脱对经典内存的依赖,反而在数据存储与调度层面遭遇更为严苛的结构性约束。
首先,量子比特并不适合作为可扩展的“存储设备”。与经典内存可以长期稳定保存比特不同,量子态天然易挥发:相干性会随时间衰减,误差会在演化、控制与环境耦合中不断积累。量子比特可以被用来承载短时的量子态演化,但若将其作为大规模、可长期保持、可反复调用的存储介质,其物理基础便会立刻变得异常脆弱;在这一意义上,“存得住”往往比“算得快”更难。
其次,即便从理论与工程两方面看,量子存储本身也几乎无法承担经典内存的角色。理论上,量子不可克隆性意味着量子态不能被简单复制:经典内存依靠复制实现的读写、备份与缓存,在量子态上不存在直接对应机制。工程上,量子纠错虽然可以延长有效存储时间,却要求用成百上千甚至更多物理量子比特来编码一个逻辑量子比特;在这种资源开销下,试图构造“几十 GB 量级”的量子存储空间,在可预见的技术路径上都没有可行性。换言之,量子存储既缺乏数据的读写机制,也缺乏容量可大规模扩展的基础。
更关键的是,量子计算机的输入与输出仍然是经典数据:问题的描述、数据的装载、结果的提取与验证,都必须通过测量与经典控制系统来完成。
以上这三点共同决定了量子计算不可避免地依赖经典内存来组织与承载计算流程,因此经典内存也必然成为量子计算系统的瓶颈。更何况,量子处理器与经典内存之间的数据交换,不仅在速度与带宽上受限,而且在接口、控制与测量层面远比经典处理器—内存通道复杂;这一“量子—经典边界”本身,很可能成为严重制约整体性能的瓶颈中的瓶颈。
设想一种极端情形:量子处理器的运算速度趋于无限,算术操作的时间成本可以完全忽略,量子计算的总体算力增长依然非常有限。正如前文所述,在大规模计算任务中,超过一半的时间与能耗本就发生在数据移动与存储相关环节。在这种情况下,处理时间即使被压缩为零,系统总耗时中与内存相关的那一半是降不下来的。这意味着,量子计算机的总耗时不可能小于经典计算机的一半以下。因此,对于绝大多数的实际应用,量子计算机的整体算力在理论上不可能比经典计算机高出一倍以上。
因此,量子计算面临的关键挑战并不只是“让量子门更快”或“让量子比特更多”,而在于:它仍然必须依赖经典内存来组织与支撑计算,而量子比特自身又难以成为一种可扩展、且长期保真的存储体系。在一个由数据规模驱动算力需求的时代,这一结构性矛盾决定了量子计算的许多宏大承诺,至少在可预见的技术路径上,值得高度审慎地看待。
结论
综上所述,量子计算的核心挑战不仅在于量子比特规模或工程实现,更在于底层体系结构的深刻矛盾:算力最终需通过数据流动与存储来兑现,而量子计算在这一维度上缺乏可扩展的基础。
在数据驱动算力的时代,内存容量、带宽与调度能力决定了算力上限。量子计算既无法摆脱对经典内存的依赖,又难以将脆弱的量子态转化为持久、可复制、可扩展的存储体系。这一底层缺失,让所有关于“通用算力跃迁”的宏大设想,在面对大数据计算任务时都显得格外地虚幻。
为何这一命题在量子计算的叙事中被长期忽视?究其原因,正视内存瓶颈意味着必须承认量子计算在体系结构上存在无法克服的障碍,这对于量子计算的推动者无异于自断生路,于是采用驼鸟策略成了他们唯一选择。同时,由于量子计算仍处于概念演示阶段,有足够多的办法把数据存储与调动环节排除在系统之外,实质上就是把问题和困难留给未来。
然而,计算技术发展史昭示了一个残酷规律:决定系统上限的结构性矛盾,从不在概念验证期显现,而只会在走向真实应用时爆发。对量子计算而言,内存瓶颈并非是事后可以补救的工程细节,而是决定其能否跨越实验室门槛的先决条件。任何脱离存储与调度条件的算力承诺,终究只是画饼充饥而已。

本文系观察者网独家稿件,文章内容纯属作者个人观点,不代表平台观点,未经授权,不得转载,否则将追究法律责任。关注观察者网微信guanchacn,每日阅读趣味文章。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

小米回应新车未上市被曝起火实为SkyNomad遭AI污染
小米新系列尚未正式发布,搜索“SkyNomad”即出现“起火”“事故”等联想词及疑似AI生成的“车祸”视频。小米官方紧急辟谣,已收集相关证据并与平台沟通,指出这是利用AI技术批量造谣的有组织的舆论攻击行为。

沃尔玛沃集鲜推出药食同源系列新品
沃尔玛自有品牌沃集鲜推出“药食同源”系列,覆盖饮品、烘焙、零食等品类,分日常与衍生两大产品梯队,联合老字号拓展消费场景,同时加速全国门店升级,以商品力与门店网络推动全渠道增长。

聆思科技获近5亿元B轮融资
聆思科技完成近5亿元B轮融资,由安徽与合肥国资领投。资金将用于新一代端侧大模型AI推理芯片研发,从感知模型升级至认知大模型。首颗Nebula系列预计2026年底推出。公司已推出23款芯片,累计出货超1 5亿片,广泛用于家居家电、教育办公等领域。

北通鲲鹏70异环联名手柄上市安魂曲薄荷双色699元
北通鲲鹏70《异环》联名款手柄上市,售价699元,提供安魂曲与薄荷双色。礼盒内含定制手柄及周边,前12000套赠游戏道具兑换卡。手柄搭载AI触觉反馈肩键、双切扳机、阻尼可调摇杆,支持星闪2000Hz回报率,兼容PC、NS、手机和车机。

全球电动汽车需求持续增长趋势研究机构报告
6月全球电动汽车注册量连续第四个月增长,达200万辆,同比增7%。欧洲市场表现抢眼,注册量飙升31%,北美受税收政策影响下滑13%。德国车企面临挑战,保时捷上半年销量降16%,大众营业利润跌54%。








- 热门数据榜



 相关攻略
相关攻略
 2026-07-11 12:56
2026-07-11 12:55
2026-07-11 12:55
2026-07-11 12:54
2026-07-11 12:54
2026-07-11 12:54
2026-07-11 12:54
2026-07-11 12:53
热门教程
2026-07-11 12:56
2026-07-11 12:55
2026-07-11 12:55
2026-07-11 12:54
2026-07-11 12:54
2026-07-11 12:54
2026-07-11 12:54
2026-07-11 12:53
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
















