




DeepSeek开源OCR新模型:轻量Qwen架构替代CLIP方案

henry 发自 凹非寺
量子位 | 公众号 QbitAI
刚刚,DeepSeek开源了全新的OCR模型——
DeepSeek-OCR 2,主打将PDF文档精准转换Markdown。

相较于去年10月20日发布的初代模型,DeepSeek-OCR 2的核心突破在于打破了传统模型死板的“光栅扫描”逻辑,实现了根据图像语义动态重排视觉标记(Visual Tokens)
为此,DeepSeek-OCR 2弃用了前作中的CLIP组件,转而使用轻量化的语言模型(Qwen2-0.5B)构建DeepEncoder V2,在视觉编码阶段就引入了“因果推理”能力。
这一调整模拟了人类阅读文档时的因果视觉流,使LLM在进行内容解读之前,智能地重排视觉标记。
性能上,DeepSeek-OCR 2在仅采用轻量模型的前提下,达到了媲美Gemini-3 Pro的效果。
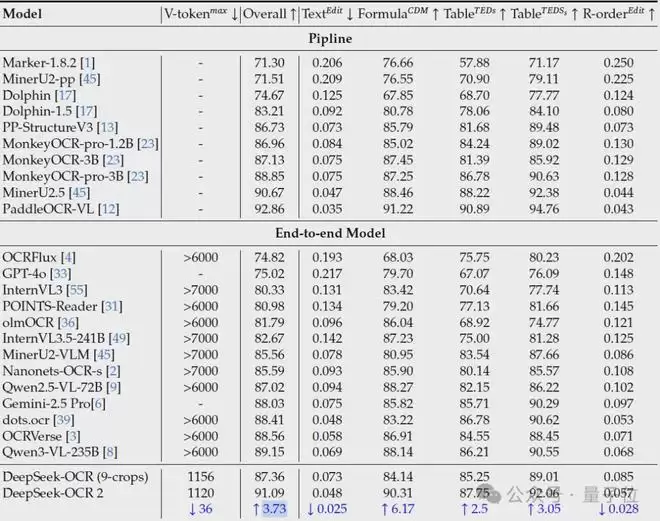
在OmniDocBench v1.5基准上,DeepSeek-OCR 2提升了3.73%,并在视觉阅读逻辑方面取得了显著进展。
值得一提的是,这次最新论文的作者依然是:魏浩然,孙耀峰和李宇琨三人组。

接下来,我们一起来看。
核心更新:DeepEncoder V2
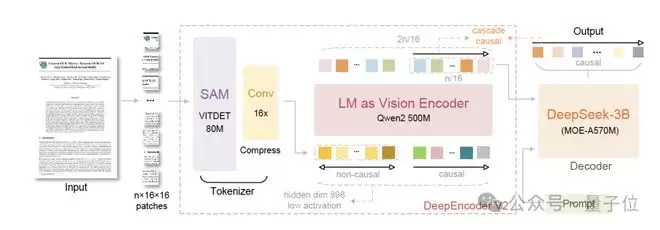
DeepSeek-OCR 2延续了前代OCR模型的经典架构,由编码器和解码器协同工作。
编码器负责将图像离散化为视觉标记(Visual Tokens),解码器则结合这些标记与用户指令生成最终文本输出。
如论文所说,DeepSeek-OCR 2此次核心的升级在于编码器——
DeepEncoder V2
传统的视觉编码器通常按照固定的“光栅扫描”(从左到右、从上到下)顺序处理图像,这在面对复杂版面(如双栏文档、错落的表格)时,往往会切断语义的逻辑连贯性。
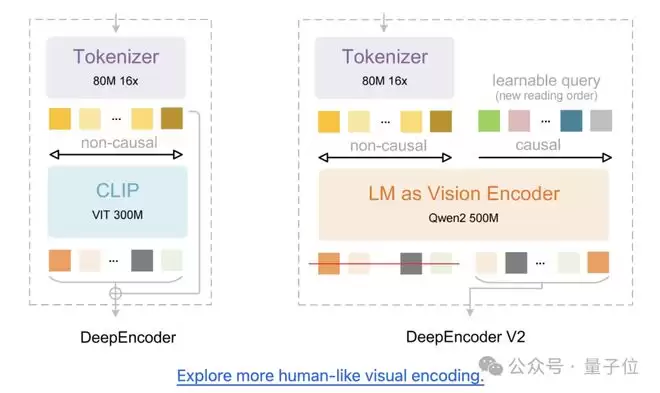
而DeepEncoder V2这次的更新解决的正是这一问题。
将此前的CLIP组件替换为轻量化的LLM架构(Qwen2-0.5B),这一转变赋予了编码器因果推理能力
信息进入主解码器之前,编码器就先对视觉标记进行“智能重排”,使其更符合人类阅读逻辑。
为了实现这种智能重排,DeepEncoder V2引入了一种全新的双流注意力机制,其底层逻辑通过一个定制的注意力掩码(Attention Mask)来约束:
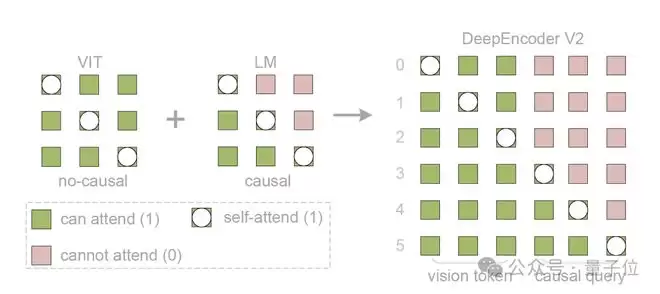
视觉标记(Visual Tokens):对应掩码左侧的全1区域,采用双向注意力,保留全局建模能力,确保每一个标记都能“看”到整幅图。因果流查询(Causal Flow Queries):对应掩码右边的三角区域(LowerTri)。这是附加在视觉标记后的可学习查询向量。它们采用因果注意力(即每个查询只能关注之前的查询及所有视觉标记)。
这种设计使得视觉标记之间互不干扰(保持原始特征),但每一个查询标记却被强制要求只能“看到”它之前的标记以及所有的视觉标记。
相比传统的交叉注意力结构,这确保视觉信息在所有层中都保持“活跃”,从而与因果查询进行深度信息交换。
此外,这实际上还建立了两阶段级联推理,成功弥合了2D空间结构与1D语言建模之间的鸿沟:
第一阶段(编码器):通过查询进行语义重排。第二阶段(解码器):对有序序列进行自回归推理。
换句话说,在V1中,图像进入LLM时,顺序是写死的。
而在V2中,通过查询标记(Learnable Query)的重排,模型在进入主解码器之前,就已经在编码器内部完成了一次“逻辑理顺”
其他组件
介绍完DeepEncoder V2的核心升级后,我们来串一下DeepSeek-OCR 2的整体架构:
首先是一开头的视觉分词器(SAM),其沿用了此前的架构,采用了80M参数的SAM-base架构,并结合两层卷积层。
输出维度从前代的1024优化缩减至896,以对齐后续管线,这套分词器的设置实现了16倍的标记压缩
这种基于压缩的设计,以极小的参数开销,极大地释放了后续全局注意力模块的计算压力,让模型运行更轻快。
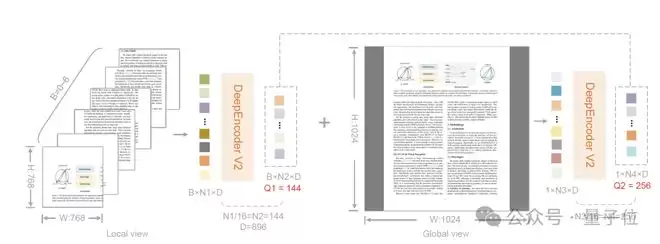
此外,为了在处理不同分辨率图像时“不丢细节”,DeepSeek-OCR 2在编码阶段还引入了灵活的裁剪方案:
全局视图(Global View): 在1024×1024分辨率下,生成256个查询标记。局部裁剪(Local Crops): 针对768×768的细部,每个裁剪块对应144个查询标记。
最终输入LLM的标记总数稳定在256到1120之间,与Gemini-1.5 Pro的视觉预算相匹配。
最后,在后端解码器部分,DeepSeek-OCR 2保留了3B参数的MoE结构(实际激活参数仅约 500M)。
训练流程与实验验证
在数据策略上,DeepSeek-OCR 2延续了与前代相同的数据源,OCR相关数据占比达80%。
其关键优化点有二:一是采样均衡化,将正文、公式与表格按3:1:1比例划分;
二是标签精简化,合并了如“图片说明”与“标题”等语义相似的布局标签。这种极小的底层差异,确保了其与基准测试之间具备高度的一致性与可比性。
在训练流程方面,DeepSeek-OCR 2采用了三阶段的训练Pipelines:
编码器预训练:通过下一标记预测(Next Token Prediction)任务,使编码器掌握特征提取、压缩和重排序能力。查询增强:冻结视觉分词器,联合优化LLM编码器和解码器,增强查询表示。解码器微调:冻结编码器,仅优化解码器,从而在相同的算力(FLOPs)下实现更高的数据吞吐量。
在实验阶段,DeepSeek-OCR 2主要在OmniDocBench v1.5上进行评估,包含1355个页面,涵盖杂志、学术论文、研究报告等9大类文档。
并与Gemini-3 Pro、Qwen2.5-VL、InternVL3.5等先进模型及多种专业OCR方案进行对比 。
如开头所示,DeepSeek-OCR 2在OmniDocBench v1.5上达到了91.09%的性能,相比基线提升了3.73%
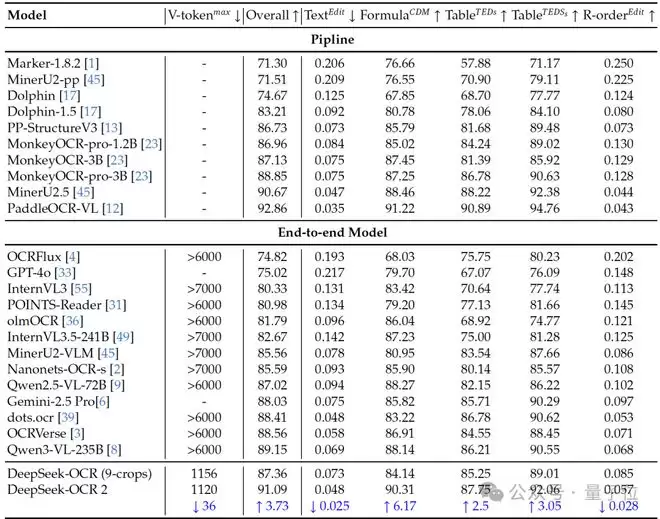
阅读顺序(R-order)的编辑距离从0.085显著降至 0.057,证明了 DeepEncoder V2 重新编排视觉信息的能力。
在相似的标记预算(1120)下,DeepSeek-OCR 2的文档解析编辑距离(0.100)优于 Gemini-3 Pro(0.115)。

在实际生产中,在线用户日志的重复率从6.25%降至4.17%,PDF 生产数据重复率从 3.69% 降至 2.88%,证明了模型逻辑视觉理解能力的提升。

整体来看,DeepSeek-OCR 2在保持高压缩率的同时实现了显著的性能提升验证了使用语言模型架构作为视觉编码器的可行性,这为迈向统一的全模态编码器(omni-modal encoder)提供了路径。
One more thing
这篇论文的三位作者分别是:魏浩然,孙耀峰和李宇琨。
魏浩然曾就职于阶跃星辰,当时主导开发了意在实现“第二代OCR”的GOT-OCR2.0系统。

孙耀峰本科就读于北京大学,现于幻方AI从事大语言模型的相关研究,R1、V3中都有他的身影。

李宇琨,谷歌学术论文近万引研究员,也持续参与了包括DeepSeek V2/V3在内的多款模型研发。
最后,OCR 2延续了DeepSeek团队一 贯的开源精神。
项目已在GitHub开源,并同步上线HuggingFace,论文也一并释出。
GitHub:https://github.com/deepseek-ai/DeepSeek-OCR-2
HuggingFace:https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
论文:https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

OpenClaw内容自动同步功能实现详解
OpenClaw默认本地存储导致多设备内容无法同步。可通过五种技术路径解决:远程挂载统一数据源;启用云端插件同步结构化状态;部署点对点工具保障隐私;配置监听技能利用云盘中转文件;或引入大模型实现智能剪贴板的同步与安全过滤。用户可根据数据安全和基础设施需求选择合适方案。

即梦AI Seedance 2.0使用教程 15秒视频生成步骤详解
使用即梦AISeedance2 0稳定生成15秒视频,需遵循关键步骤。首先选择“全能参考模式”并将时长设为15秒。其次,上传不超过12个多模态参考素材,包括图片、视频和音频。接着,编写结构化的分镜头提示词,按时间轴详细描述画面与动作,并使用@语法绑定素材。最后,启用Fast加速模式以确保任务顺利完成并节省积分。

Recraft AI账号注册图文教程:手把手教你完成注册
RecraftAI注册需访问官网并点击“Signin”。可选择邮箱注册或Google快捷登录。邮箱注册需填写有效邮箱、设置强密码并同意协议,提交后必须通过邮件验证激活账户。使用Google账户登录则无需验证,授权后即可直接进入工作台。

Canva可画AI海报设计教程打造高曝光视觉作品
AI设计时代制作高曝光海报需把握三个关键:精准触发AI生成、快速筛选方案及发布前细节优化。输入指令应包含场景、对象、情绪等要素,避免模糊词汇。筛选时关注信息可读性、配色适配性及内容替换空间。发布前需添加引导文案、嵌入平台友好型元素并选对导出格式与尺寸,以提升互动与曝光效。

DeepSeek搭建企业文档智能检索系统教程
DeepSeek网页版因缺乏文档索引能力,不适合直接构建企业文档检索系统。搭建此类系统需自建核心RAG链路,包括文档加载器、嵌入模型和向量数据库。具体实现可选用LangChain框架整合各模块,并针对扫描件单独进行OCR处理。系统需注意配置细节,如持久化存储和元数据管理,以确保检索结果的可追溯性。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
