




英特尔锐炫Pro+B60配96GB显存,实测满足千人同时在线聊天

一、前言:当前最具性价比的96GB 192GB AI推理卡凭借深耕多年的CUDA护城河,NVIDIA在AI领域一度拥有 "定价权 ",这也让这家公司的GPU及相关产品的售价逐渐脱离普通的消费者。然而,随
一、前言:当前最具性价比的96GB/192GB AI推理卡
凭借深耕多年的CUDA护城河,NVIDIA在AI领域一度拥有"定价权",这也让这家公司的GPU及相关产品的售价逐渐脱离普通的消费者。
然而,随着硬件巨头Intel向"全栈AI公司"快速转型,这种绝对垄断正在被打破。
早在2019年,Intel就发布了oneAPI 跨架构编程模型,旨在让代码在 CPU、GPU、NPU 之间通用。这意味着开发者用一套代码即可调用 Intel 的所有算力,降低了迁移成本。
oneAPI还允许开发者将原本仅能NVIDIA CUDA环境下运行的代码,通过其迁移工具(SYCLomatic)快速转换到Intel硬件上,为Arc系列显卡运行主流大模型打下了坚实的软件基础。

去年,Intel发布了基于第二代Xe2架构(Battlemage)的专业级显卡—Intel Arc Pro B60。随后,以Maxsun(铭瑄)、SPARKLE(撼与)、GUNNIR(蓝戟)为代表的核心伙伴正式将其推向全球市场,直指高性能AI推理领域。
Intel Arc Pro B60与此前发布的消费级Intel Arc B580一样,都采用了完整的BMG-G21 GPU 核心, 拥有20个Xe2核心,2560个FP32单元(也可以说是2560个流处理器),20个光追单元和160个XXM AI引擎。

每颗BMG-G21 GPU可提供12.28 TFLOPS的FP32浮点性能以及197 TOPS的INT8 AI性能。
在显存方面,Intel Arc Pro B60设计了192bit位宽、19Gbps GDDR6显存,显存带宽高达456GB/s,显存容量则从Intel Arc B580的12GB直接翻倍到了24GB。
与更贵的NVIDIA RTX Pro 2000相比,Intel Arc Pro B60不论是显存容量还是显存带宽都比对手高出了50%。
而在大模型推理中,显存容量决定了模型的参数上限,带宽则决定了吐字速度。
相比之下,NVIDIA同样显存规格的AI加速卡,售价往往是Arc Pro B60的3至4倍。
随着DeepSeek等大规模 MoE 模型爆发的,Intel Arc Pro B60成为了目前市面上构建 96GB(4卡) 到 192GB(8卡)超大显存池最具性价比的方案。

此次我们收到了来自于长城的世恒X-AIGC工作站,这台主机搭载了Intel Xeon w5-3435X处理器、256GB(4x64GB)DDR5 ECC 6400MHz内存、2600W金牌电源以及4张Intel Arc Pro B60 24GB显卡,共计96GB显存。
二、英特尔锐炫Pro B60和长城世恒X-AIGC工作站图赏

长城世恒X图形工作站包含4张Arc Pro B60显卡,不过为了运输安全,发货时,显卡会单独包装,并不会直接安装在主机里面。

Arc Pro B60 24GB公版显卡正面照,双槽厚度,配备一个涡轮风扇。

显卡背面有全尺寸的金属背板,大量的片式聚合物电容也放在背面。

3个DP 2.1和一个HDMI 2.1接口。

2个8Pin供电接口放在了显卡尾端。

长城世恒X图形工作站。


超大的水冷头与水泵采用了分离设计,水泵在其中一根水冷管上。



将4张Arc Pro B60安装进去。

长城世恒X图形工作站与4张Arc Pro B60合体。
三、GPT-OSS-120B MXFP4多并发性能测试:能满足千人同时在线聊天
GPT-OSS-120B是OpenAI首个开源的千亿级参数模型,总参数 1170 亿 (117B),被认为是测试多卡并联(Multi-GPU Parallelism)和分布式计算性能的标杆。
我们将GPT-OSS-120B模型下载至容器的llmmodels目录下,并开启vLLM OpenAI API服务,具体参数如下:
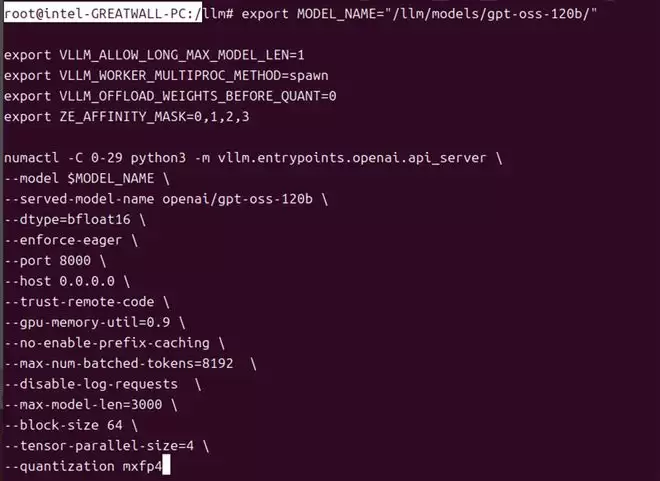
由于120b占用显卡超过66GB,只能4卡并联进行测试,推理精度bfloat16,单次批处理的最大Token总数为 8192,最大上下文长度(Token 数)为 3000,GPU 显存利用率上限为 90%(预留10%给系统),使用MXFP4(混合精度 FP4)进行量化压缩。

vLLM OpenAI API 服务已经成功启动,下面单开一个窗口进行测试。
vLLM版本是最新的0.5.0,无法使用过去的benchmark_serving.py脚本进行测试,因此我们直接使用vllm bench serve命令,分别测试并发数1,10,20,30,40,50,60,70,80,90,100时的AI性能。
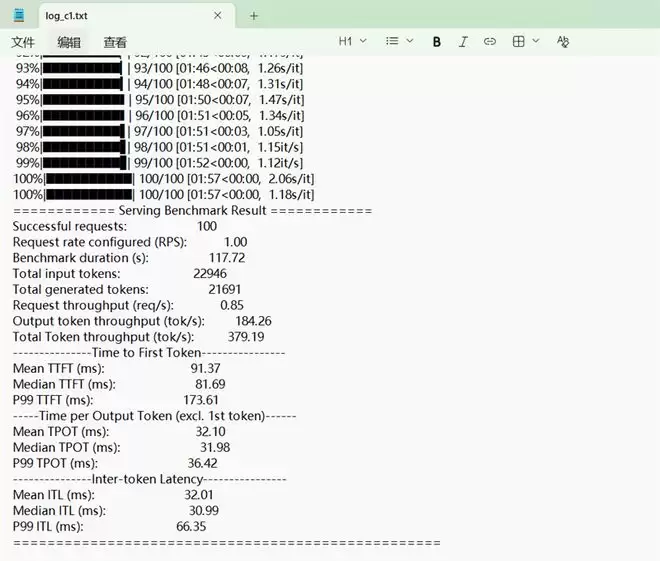
这是并发数为1的测试成绩日志,请求成功率 100%,在处理 120B 这种超大规模模型时,100 个请求全部成功且无一报错,说明4卡 Arc Pro B60 + MXFP4运行测试时非常稳定。
TTFT (首字延迟)仅为91.37ms,说明Arc Pro B60预填充(Prefill)阶段的爆发力极强。
平均 ITL (逐词延迟) 为 32.01 ms,输出吞吐量则为184tok/s。
下面是并发数从1,10,20,30,40,50,60,70,80,90,100的性能变化。

当并发数从1~10时: 系统的吞吐量呈现指数级增长,从 184 飙升至 613 tok/s。
不过并发数达到60之后,吞吐量为701 tok/s,基本上已经达到了这套系统的极限,即便请求数增加到100之后,总吞吐量也就增加了1%左右。

整个测试期间,ITL (逐词延迟)稳定得出奇,在达到并发 30 后,ITL 甚至随着并发增加而轻微下降。也就是说在高负载下,计算核心被填充得更满,单步推理的效率反而由于批处理效应而略微提升。
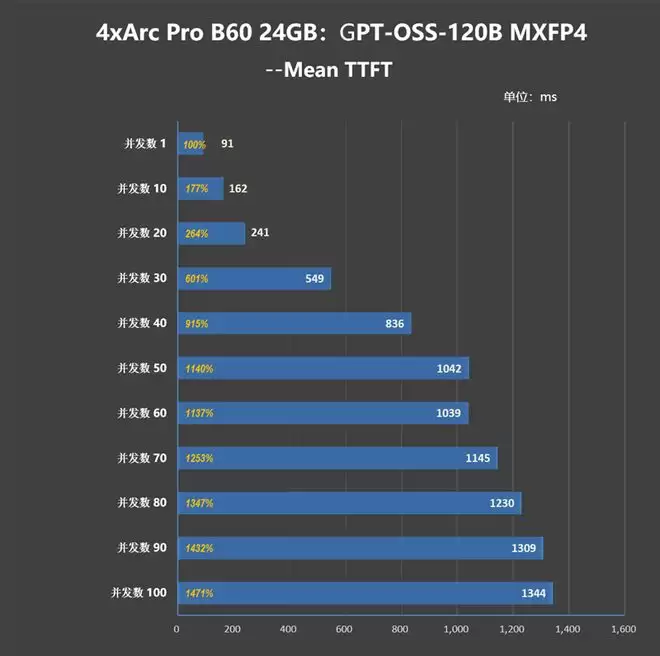
TTFT (首字延迟)震动比较剧烈,并发数为1时仅有91ms,并发数20时为241ns,并发数100时已经到了1344ms。
对于大多数用户而言,10 tok/s即可拥有丝滑的访问体验,根据长城世恒X图形工作站700tok/s的极限性能计算,它可以承受70个用户同时请求回答。
再按1:15的活跃比计算,这台工作站可以支持1000人同时在线聊天。
四、Llama-3.1-8B测试:比同价位RTX Pro 2000 16GB要快50%
1、Llama-3.1-8B
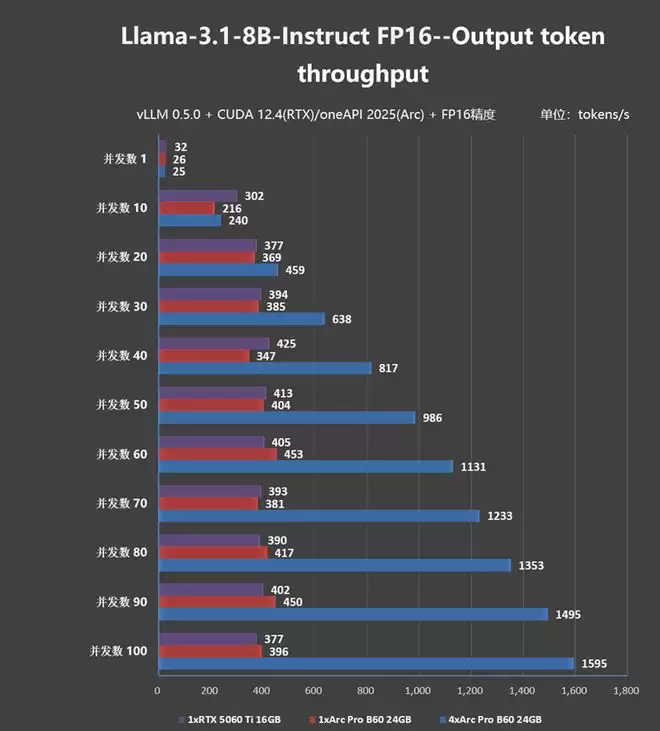
Llama-3.1-8B的显存需求只有7GB左右,因此不仅可以对Arc Pro B60 24GB进行单卡、双卡、4卡测试,我们还能测试桌面版RTX 5060 Ti 16GB的推理性能并与之进行对比!
vLLM 0.5.0 正式建立了对 Intel Arc GPU的原生支持,不再是以往那种简单的代码迁移,而是针对 Intel 的计算单元架构做了适配:
在并发数下,RTX 5060 Ti 16GB的性能略胜于单卡Arc Pro B60 24GB,但随着并发数的提升,Arc Pro B60 24GB随着并发数的提升,Arc Pro B60 24GB凭借大显存的优势开始逆袭,并发数90时,可以领先RTX 5060 Ti 16GB约10%左右。
4张Arc Pro B60 24GB在低并发数时性能优势并不明显,但随着并发数的提升,特别是达到100并发后,4张Arc Pro B60 24GB的性能几乎是单卡的4倍。
下面将精度降为FP8,重复上面的测试,但将N卡换成RTX Pro 2000。
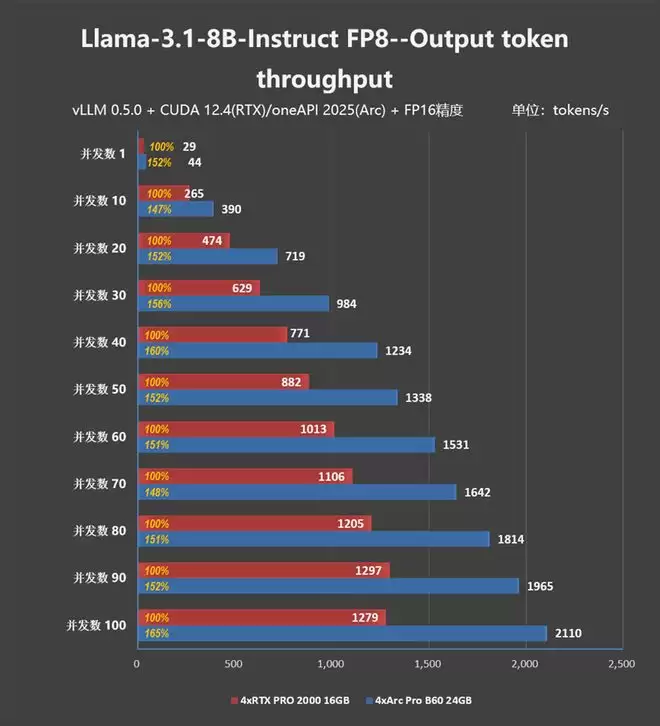
与同价位的NVIDIA RTX Pro 2000 16GB相比,Arc Pro B60 24GB几乎展现出了碾压性优势。
同样是4卡并行进行运算,4xArc Pro B60 24GB比起4xRTX Pro 2000 16GB要强了50%左右,在并发数为100的情况下,凭借96GB大显存,Intel的领先幅度甚至达到了65%。
五、小结:用入门级N卡的价钱 买了接近旗舰级N卡的显存容量和推理性能
凭借CUDA生态的支持,NVIDIA的GPU在特定的生产力与AI方面的确有无可比拟的性能优势。
但是在大模型时代,显存即正义。
96GB显存意味着你可以本地运行参数量更大的模型,比如千亿级参数GPT-OSS-120B、LLaMA-3-130B对于4卡Arc Pro B60 24GB完全不是问题。
同样价位的NVIDIA RTX Pro 2000 16GB,4卡合计64GB显存,这是一个相对尴尬的显存容量,只能运行70B模型。在面对千亿级模型时必须极致量化压缩显存,且仅支持短上下文低负载推理,完全无法支持训练和微调。

而在性能方面,Arc Pro B60 24GB几乎展现出了碾压性优势。
同样是4卡并行运算(Llama-3.1-8B-Instruct FP8),4xArc Pro B60 24GB比起4xRTX Pro 2000 16GB要强了50%左右,在并发数为100的情况下,凭借96GB大显存,高负载(Batch 100)下,Intel 方案达到了 2110 Tokens/s,而同样价位的NVIDIA方案仅为 1279 Tokens/s。
Intel的领先幅度超过了65%。
在运行1200亿参数的GPT-OSS-120B时,Arc Pro B60 24GB在预填充(Prefill)阶段展现出了极强的爆发力,并发数为1的时候,Mean TFT (首字延迟)仅为91.37ms。
当并发数达到60之后,4张Arc Pro B60 24GB的吞吐量超过了701 tok/s,能满足千人同时在线聊天。
对于想要组建高性能本地 LLM 推理站的企业而言,5000元的Arc Pro B60 24GB显然是更具性价比的选择。
要知道NVIDIA类型算力的24GB专业卡,其售价几乎是Arc Pro B60 24GB的4倍左右。
很简单的结论:Arc Pro B60 24GB能让用户以入门级N卡的价钱,买了接近旗舰级N卡的显存容量和推理性能。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

索尼PS平台3A单机首周销量占比达75%–80%
先来看一组颇具参考价值的市场数据。近期行业调查显示,在主机平台发售的3A级单机游戏首周销量中,索尼PlayStation平台几乎占据了75%至80%的份额,而Xbox平台的表现则相对低调。不过,在多人在线游戏领域,情况出现了明显变化——两个平台的市场占比差距显著收窄。 深入分析这些数据,可以发现背后

吴启华授权AI复刻20岁形象主演新片引领数字影视创新
2026年6月,62岁的香港资深演员吴启华在出席新剧宣传时,公布了一项颇具前瞻性的决定——正式进军AI数字影视领域。具体而言,他授权影视制作团队,利用自己20岁时的肖像数据,通过AI技术重建青年形象,用于一部即将上映的电影。更关键的是,片中的男主角将完全由这一数字化形象出演,无需他本人亲临片场参与拍

苹果MacBook Pro等新品将支持95% BT.2020色域
苹果这一步棋,瞄准的是下一代旗舰屏幕标准。2026年6月30日,研究机构TrendForce在最新的AMOLED技术与市场分析报告中明确点出:苹果正计划在未来的MacBook Pro、iPad Pro和iMac上,逐步引入色域覆盖率达到95% BT 2020的OLED显示面板。 BT 2020是什么

《昨夜将至》大结局被批烂尾观众直言一言难尽
有时候,确实会对自己的判断力产生怀疑。 有些电视剧明明前期表现尚可,一旦进入结局阶段,剧中人物就像“失控”一般,开始各种出格行为,仿佛只盼着能排队领盒饭。无论是剧情节奏还是人物塑造,前后水平判若云泥,追到最后还以为前半段剧情只是一场幻觉。 没错,说的就是《昨夜将至》。要说这部剧,其实拍到第五集就应该

《潜伏》背后的信仰启示与解读
近日,经典谍战剧《潜伏》在B站等平台意外翻红。这部2008年首播的老剧,凭借其扎实的剧情与深刻的人物刻画,俘获了大量年轻观众。在弹幕与评论区里,满屏的“全体起立”,是年轻人向隐蔽战线上的革命先辈表达最崇高的敬意。这部没有流量明星、没有华丽特效的谍战佳作,为何能引发当下年轻人的集体共鸣?答案,深藏在五








- 热门数据榜



 相关攻略
相关攻略
 2026-07-10 06:25
2026-07-10 06:25
2026-07-10 06:25
2026-07-10 06:25
2026-07-10 06:24
2026-07-10 06:24
2026-07-10 06:24
2026-07-10 06:24
热门教程
2026-07-10 06:25
2026-07-10 06:25
2026-07-10 06:25
2026-07-10 06:25
2026-07-10 06:24
2026-07-10 06:24
2026-07-10 06:24
2026-07-10 06:24
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
















