




32倍压缩性能反超25点!长文本压缩翻车难题破解

COMI团队 投稿
量子位 | 公众号 QbitAI
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
为什么现有上下文压缩方法在高压缩率下集体“翻车”?当模型把32K长文本压到1K,为何性能断崖式下跌?
长文本压缩中容易保留大量“高度相似却重复”的内容,陷入“信息内卷”:看似保留了相关片段,实则堆砌了语义雷同的冗余token,反而误导模型生成错误答案。
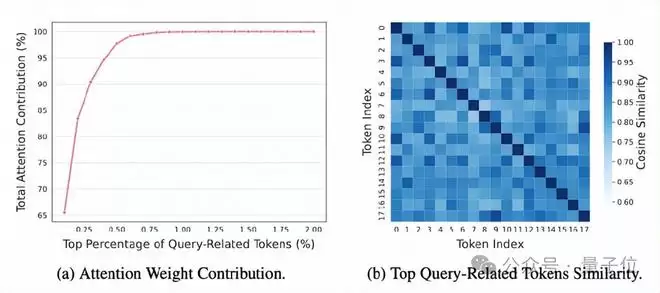
来自阿里巴巴未来生活实验室的研究团队发现,这背后是压缩目标的根本错位:现有方法只关注“相关性”,却忽略了“多样性”。当多个高度相似的token同时被保留,它们非但不能叠加信息量,反而会相互干扰(相关不等于正确),让模型在高度相似的冗余信息中迷失方向。
为破解这一困局,研究团队提出一个颠覆性观点:高质量的压缩,需要同时优化“与查询的相关性”和“信息单元间的多样性”。基于此,他们推出创新框架COMI(COarse-to-fine context compression via Marginal Information Gain),通过“边际信息增益”指标与粗到细压缩策略,在32倍高压缩率下仍能精准保留多样化的关键证据链,论文已中稿ICLR 2026。
压缩的“智能标尺”:边际信息增益(MIG)
研究团队发现,现有压缩方法存在盲区:过度依赖相关性导致冗余堆积,而忽略了token间语义相似性引发“信息内卷”。为此,他们使用边际信息增益(MIG)指标,将压缩决策从“单维度相关性”升级为“相关性-冗余性”双维度权衡:
MIG = 本单元与查询的相关性 - 与其他单元的最大相似度
这一指标如同为每个token配备“信息价值计分卡”:既奖励与问题高度相关的片段,又惩罚与已选内容高度重复的片段。
粗到细自适应压缩,让每比特都“物有所值”
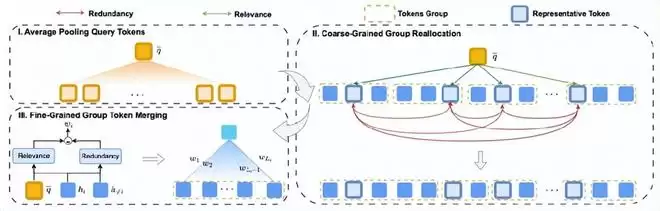
有了智能标尺,如何实现精准压缩?COMI采用两阶段策略,像经验丰富的编辑一样“先谋篇布局,再精雕细琢”
第一阶段:粗粒度组重分配——动态调配“压缩预算”
将长文本划分为等长片段后,COMI不再“一刀切”地均匀压缩,而是基于组间MIG动态调整各段压缩率:信息密度高、冗余度低的片段(如包含关键证据的段落)获得更宽松的压缩率;而信息稀疏或高度重复的区域则被大幅压缩。这种自适应分配确保有限的压缩预算精准投向“高价值信息区”
第二阶段:细粒度token融合——加权融合避免“信息稀释”
在每个片段内部,COMI根据token级MIG进行加权融合:高MIG token(相关且独特)在融合中占主导权重,低MIG token(冗余重复)被自然稀释。这一机制有效避免了传统平均池化导致的“关键细节被平滑掉”的问题,使压缩后的表示既紧凑又富含多样化信息
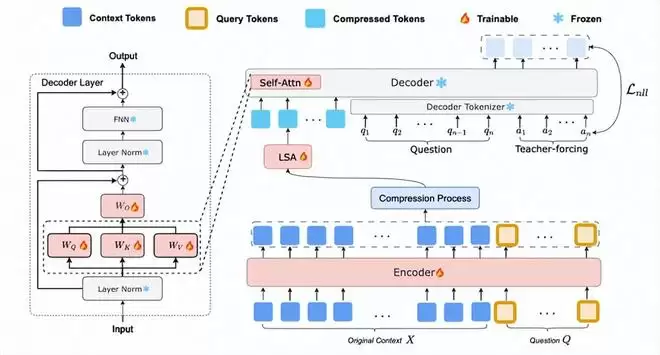
整个框架在NaturalQuestions、HotpotQA等5个数据集上仅需单次训练,即可执行问答、摘要等多种长上下文任务。
实践出真知:高压缩率下的优越性能与深刻洞察
下游任务表现卓越
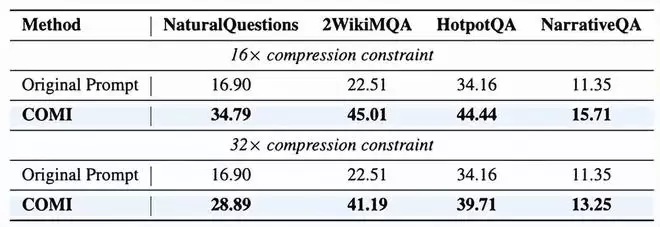
在32倍压缩约束下,COMI以Qwen2-7B为基座,在NaturalQuestions上实现49.15的Exact Match(EM)分数,比次优基线高出近25个点。即使面对32K超长文本(NarrativeQA),COMI仍能稳定保留推理链关键节点,证明其在极端压缩场景下的鲁棒性。
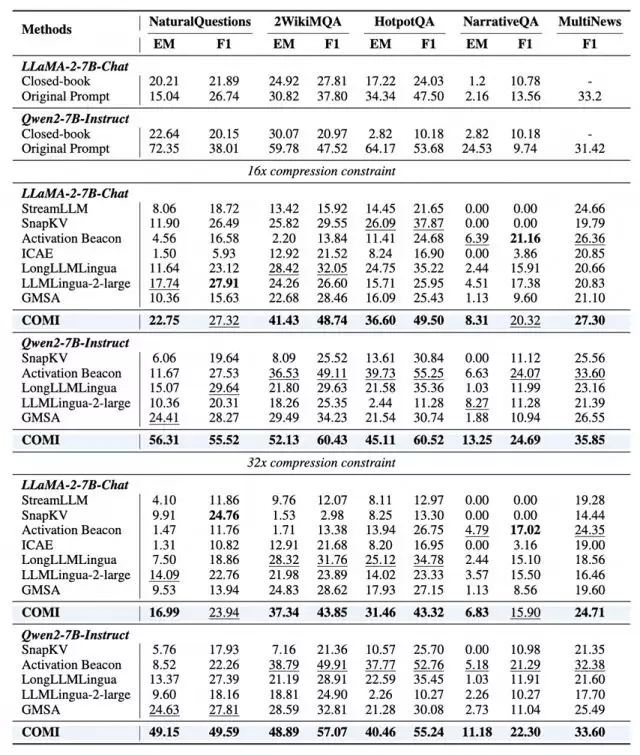
压缩不是“删减”,而是“提纯”
COMI甚至能提升原生支持256K上下文的Qwen3-4B性能。在NaturalQuestions上,32倍压缩后的COMI达到28.89的F1分数,远超直接输入完整上下文的16.90。这证明高质量压缩不仅是“减负”,更是通过消除冗余干扰实现“信息提纯”,让模型更聚焦于核心证据。
效率与效果兼得
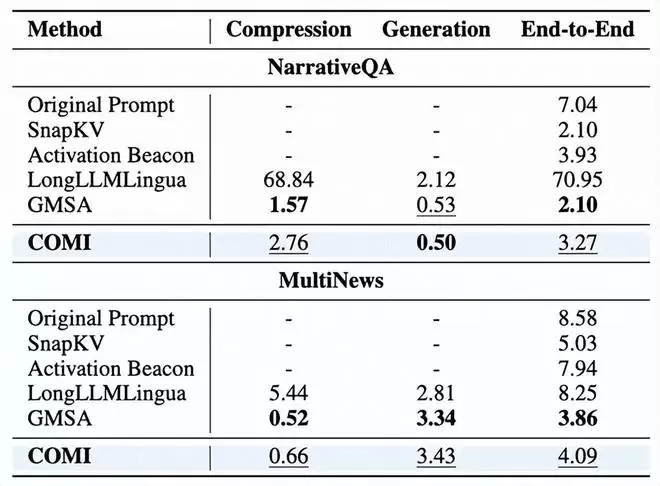
在32倍压缩下,COMI实现端到端推理速度2倍以上提升,且压缩阶段仅引入轻量级开销(NarrativeQA任务中压缩耗时2.76秒,生成仅0.50秒),为工业级部署铺平道路。
总结
COMI工作为长上下文高效推理提供了新范式:
它通过边际信息增益这一简洁而深刻的指标,将压缩目标从“保留相关片段”升级为“保留相关且多样化的信息”,从根本上破解了高压缩率下的性能瓶颈。粗到细的自适应策略则确保了压缩过程既符合全局信息分布,又保留局部语义细节。
这项研究证明,真正的高质量压缩不是简单的“删减”——让每一比特都承载多样化的信息价值,为大模型走向轻量化、实用化迈出关键一步。
论文标题:
COMI: Coarse-to-fine Context Compression via Marginal Information Gain
论文链接:
https://arxiv.org/abs/2602.01719
代码链接:
https://github.com/Twilightaaa/COMI

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

阿伯丁大学揭秘AI时间推理机制词汇切分与内部表征作用解析
这项由阿伯丁大学和格勒诺布尔阿尔卑斯大学联合开展的研究(论文编号arXiv:2603 19017v1),揭示了一个我们日常使用AI时可能都遇到过,却未必深思的现象:当你用中文、阿拉伯语或其他非英语语言,向ChatGPT等助手询问“2024年3月15日往后推90天是什么时候”这类时间问题时,它们的表现

AI提升编程效率30%为何软件交付速度反而下降
许多企业正面临一个普遍困境:AI工具将开发者的编码效率提升了30%以上,但软件交付的整体速度与可预测性却未见明显改善,甚至出现波动。症结何在?关键在于,企业往往只聚焦于“编码”环节的优化,而忽视了测试、集成、部署与运维所组成的完整交付链路。 提升开发者的编码速度固然重要,但如果后续的测试验证与发布流

Prompt优化技巧:如何让你的提示词比代码更有价值
去年四月,Anthropic 推出的 Claude Design 产品引发了广泛关注。用户只需用自然语言描述界面或网页设计需求,几十秒内就能获得可用的高保真原型。这种将自然语言直接转化为设计稿的效率,在当时确实令人印象深刻。 大约一周后,GitHub 上出现了一个名为 open-design 的开源

智能体评估演进:从单次交互到全流程轨迹分析
过去一年,大语言模型(LLM)应用评估的重心,悄然发生了一场深刻的转变:从早期的“输出质量”,到后来的“检索质量”(RAG场景),如今正全面聚焦于“轨迹质量”(Agent场景)。这并非简单的指标叠加,而是评估对象与方法论的一次根本性升级。 设想一下,你在生产环境部署了一个智能体(Agent)系统。每

德黑兰大学揭示波斯语音频理解面临的实际挑战与难点
这项由德黑兰大学电气与计算机工程学院与基础科学研究院合作完成的研究,已入选2026年的Interspeech会议。对技术细节感兴趣的读者,可通过论文编号arXiv:2603 14456v1查阅全文。 想象这样一个场景:一位伊朗友人正为你朗诵一首优美的波斯古诗。即便不解其意,你也能被那独特的韵律和节奏








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
