




MoE推理的正确玩法:跳过88%专家保住97%性能 | CVPR 2026

免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
新智元报道
编辑:LRST
【新智元导读】CVPR新研究MoDES让多模态大模型推理效率飙升:无需训练,智能跳过88%冗余专家,仍保留97%性能,彻底打破「跳得多必掉点」旧认知,推理速度提升2倍。
多模态大模型正在迅速走向大规模。为了处理更高分辨率图像、更长视频序列以及更复杂跨模态任务,模型参数规模持续增长。
Mixture-of-Experts(MoE)架构成为主流选择:通过只激活部分专家网络,试图在保持模型规模的同时降低计算开销。
但问题在于——即便采用 MoE,多模态模型的推理成本依然很高。
每个token仍需与多个专家交互,大量计算发生在「并非真正关键」的专家上。MoE 的确避免了「全参数全激活」,却没有真正做到「按需计算」。
在视频理解或长上下文场景下,这种冗余会被迅速放大,成为推理瓶颈。
于是,一个自然问题出现:能否在推理阶段动态跳过冗余专家?
已有expert skipping方法在纯文本LLM上取得了一定效果,但一旦直接应用于多模态模型,往往出现明显性能下降。跳得越多,掉点越严重,高比例skipping下甚至直接崩溃。
来自香港科技大学、北航、北大等单位的研究团队提出了MoDES(Multimodal Dynamic Expert Skipping),系统分析了多模态MoE skipping失效的根本原因,并给出了一套面向多模态MoE的training-free动态专家跳过框架,该工作已被CVPR接收。

论文地址:https://arxiv.org/pdf/2511.15690
代码地址:https://github.com/ModelTC/MoDES
在Qwen3-VL-MoE-30B上,MoDES在跳过88%专家的情况下,仍保留97.33%原始性能,同时带来显著推理加速,打破了一个长期存在的共识:高比例专家跳过必然带来不可接受的性能损失。
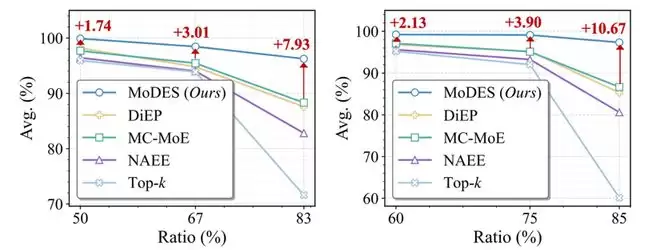
图表1 不同skipping比例下MoDES与现有方法在13个基准上的性能对比
MoDES并没有直接提出新规则,而是首先回答一个更基础的问题:为什么为文本模型设计的skipping方法,在多模态MoE上会明显失效?
论文给出了两个关键观察。
不同层专家对最终输出的全局贡献高度不均衡:现有skipping方法通常仅依据当前层的routing概率判断专家是否重要,但忽略了一个关键事实:不同层专家对最终预测分布的影响差异巨大。
实验表明,当减少routed experts数量时,浅层专家的减少会导致更显著的性能下降,而深层专家的影响相对较小。这意味着浅层误差会在后续层逐步放大,从而引发性能崩溃。
换言之,专家的重要性不仅是「局部routing概率」的问题,更是「对最终输出影响程度」的问题。如果采用层无关的统一规则,很容易在关键浅层跳得过多。相关现象如图表2所示。
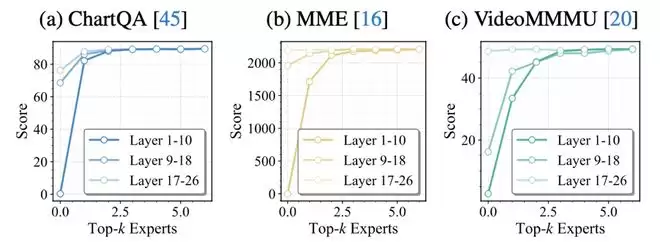
图表2 不同层范围减少专家后的性能变化
文本token与视觉token行为存在显著差异:论文进一步分析了模态差异。通过对FFN前后token表征的可视化与统计分析,研究者发现:文本token在FFN中的更新幅度明显更大;视觉token与专家权重更接近正交;专家对视觉token的影响相对较小。
这意味着,专家对文本推理更关键,而对视觉token存在更高冗余。如果skipping策略不区分模态,很可能误删对文本理解至关重要的专家,导致性能下降。相关分析见图表3。
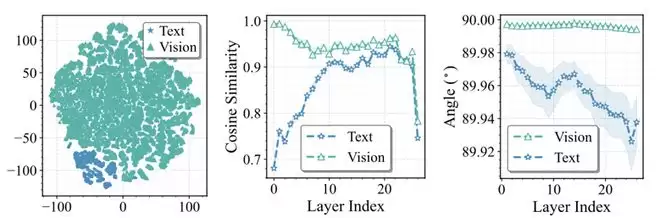
图表3 文本与视觉token在FFN中的差异分析
这两个观察共同指向一个核心结论:多模态MoE的专家重要性,需要同时具备output-aware(输出感知) 与modality-aware(模态感知)。
输出感知+模态感知
动态skipping框架
基于上述insight,MoDES构建了一个输出感知、模态感知的动态专家跳过机制,其整体流程如图表4所示。
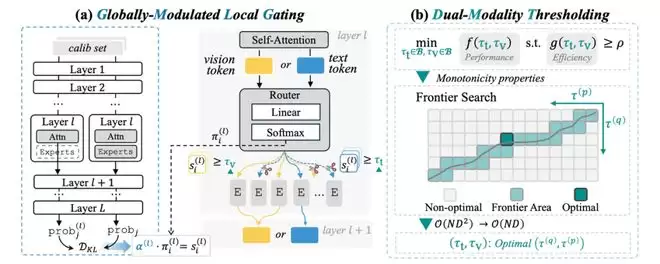
图表 4 MoDES框架图
首先,MoDES在原始routing概率基础上引入层级全局重要性因子,用于刻画第
l层专家对最终输出分布的整体影响。
该因子通过离线校准获得,即比较移除该层专家前后模型输出分布的差异,从而量化该层专家的全局贡献。新的专家重要性分数由局部routing概率与全局因子共同决定。这样一来,浅层专家会被更保守地保留,而深层专家可以更激进地跳过,实现真正的output-aware skipping。
其次,MoDES引入双模态阈值机制,为文本token与视觉token分别设定不同的skipping阈值。通过模态区分,使专家跳过决策更加精细化,避免误删关键专家。
最后,为高效寻找最优阈值组合,MoDES设计了frontier search算法,利用性能与 skipping比例之间的单调性,将搜索复杂度从降为,在保证结果一致性的同时将搜索时间缩短约45倍。

图表5 校准与搜索时间对比
实验结果
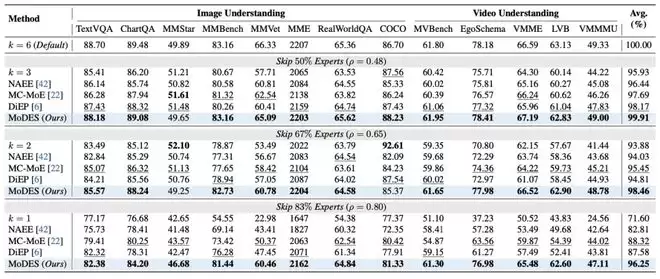
在主实验中,QVGen在W4A4/W3A3在大规模实验中,MoDES在多个主流多模态MoE模型上进行了系统评估。
在Kimi-VL-A3B-Instruct上,当跳过83%专家时,多数现有expert skipping方法平均性能下降超过11%,而MoDES仍然保留96.25%原始性能(见图表 6)。这一结果说明,高比例skipping并不必然导致性能崩溃,只要专家的重要性建模足够准确,冗余专家可以被有效识别。
在更大规模的Qwen3-VL-MoE-30B-A3B-Instruct上,MoDES的优势更加明显。在跳过88%专家的条件下,MC-MoE仅保留86.66%性能,DiEP保留85.30%,而MoDES仍然能够保留97.33%原始性能(见图表 7)。在13个图像与视频理解基准上,MoDES均取得最优或接近最优表现。
图表6 Kimi-VL不同skipping比例性能对比
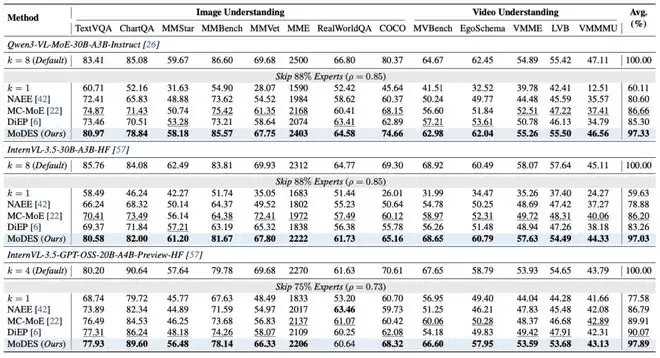
图表7 跨backbone性能对比
这一结果表明,高比例skipping并非不可行,关键在于是否能够正确建模专家对最终输出的全局贡献以及不同模态token的行为差异。
推理效率与量化兼容性
在实际推理测试中,MoDES在H200 GPU上实现了显著加速。在Prefill阶段获得约2×加速,在Decoding阶段仍有约1.2×提升(见图表 8)。由于MoDES为training-free方法,推理阶段不引入额外计算开销,因此加速效果更加稳定。
此外,MoDES与混合精度量化具有良好兼容性。在低比特量化条件下仍能保持较高性能,说明skipping与量化可以从结构与数值两个层面形成互补,共同降低多模态MoE的计算成本。
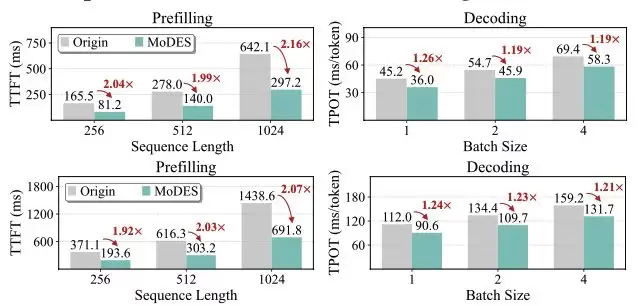
图表8 推理速度对比。(上)Qwen3-VL;(下)Kimi-VL。
总结
MoDES的核心贡献在于:提出了一种真正output-aware、modality-aware的多模态专家跳过机制。
通过显式建模不同层专家对最终输出分布的全局贡献,以及不同模态token在专家网络中的更新特性,MoDES证明了一件重要的事情:即便跳过80%以上的专家,只要跳得足够「聪明」,模型性能依然可以稳定保持。
在多模态模型规模持续扩大的背景下,这种基于输出影响建模的skipping思路,为大模型推理效率优化提供了一条更加稳健且可落地的路径。
参考资料:
https://arxiv.org/pdf/2511.15690

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

日产伊凡引领智能出行新浪潮开启未来出行新篇章
日产汽车发布新愿景,以客户为中心重构全球战略,聚焦日、美、中三大市场。中国被定位为销量引擎和创新策源地,其电动化与智能化技术将反哺全球。公司将加速在华新能源产品投放,推动“中国制造”车型出口,并深化与东风汽车的独家合作,通过提升决策效率与跨文化沟通驱动发展。

班级毕业纪念视频制作教程 合照变动态电子相册方法
借助可灵AI平台,可将静态班级合照一键生成动态毕业纪念视频。平台提供毕业模板,智能处理照片排序、动态效果、背景音乐及字幕添加。用户上传照片后,系统自动按时间线排列并匹配氛围,最终快速导出高清视频,便于分享。

HermesAgent自动优化SEO密度避免关键词堆砌惩罚
撰写技术文章,尤其是借助AI辅助创作时,最大的挑战是什么?并非内容不够专业,而是内容过于“机械”——专业术语密集堆砌,读起来生硬刻板,不仅影响读者体验,也容易触发搜索引擎的算法警报。这种关键词过度堆砌的做法,无疑是SEO优化中的常见误区。 如果您在使用Hermes Agent生成内容时,也遇到了类似

飞书集成选OpenClaw还是ArkClaw本地部署与生态对比
在飞书平台集成AI助手时,许多开发者会关注开源方案OpenClaw。但需要明确一个关键点:OpenClaw是一个通用的开源AI框架,并非专为飞书设计;而ArkClaw则是字节跳动官方为飞书生态深度定制的云端智能体服务。因此,问题的核心并非哪个工具“能够使用”,而是哪个方案能在飞书环境中实现无缝集成、

2024年AI矢量绘图工具Recraft的独特优势与超越之道
在AI矢量图形生成领域,2024年迎来了一个关键的技术转折点。如果你正在寻找一款能够实现高精度控制、并能直接应用于商业项目的高效工具,那么Recraft的突破性进展绝对值得深入研究。它的核心优势,已经超越了单纯“生成美观图像”的范畴,而是聚焦于几个更为硬核的专业维度:精准的长文本理解与渲染、原生的S








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
