




英伟达重塑AI单用户性能:2万Tokens/秒,能耗骤降千倍

3月23日消息,如果说前几年的AI重点是训练,那么现在的重点是推理,NVIDIA上周的GTC大会上已经发布了全新的LPU芯片,就是要重塑AI推理。
在GTC大会期间,NVIDIA首席科学家Bill Dally跟谷歌首席科学家Jeff Dean两位大神有了一番精彩的深度访谈,其中Dally就谈到了NVIDIA在做的一些研究进展。
AI推理对延迟的要求很高,Dally指出目前的瓶颈已经不是算力本身,瓶颈在通信开销上,NVIDIA正在研究片上通信的静态调度,将会彻底取消路由开销、排队和仲裁,通信速度接近光速本身。
目前的技术方案中,芯片从一角到另一角的延迟有几百纳秒之多,NVIDIA的技术方案可以做到30纳秒。
片外通信中,之前的方案是一步步提高带宽速率,现在做到了400Gbps甚至800Gbps,但这样的带宽也带来了复杂的信号处理及纠错机制,但速度如果从400Gbps降低到200Gbps,复杂问题反而会消失,只做序列化延迟的话,几个时钟周期就能完成。
Dally表示他有信心未来AI推理可以做到单用户每秒10000到20000Token的推理速度——作为对比,大家要知道目前很多人用在大模型AI推理速度,普遍在100Token每秒以内,甚至每秒60Token以上的速度就算高速了。
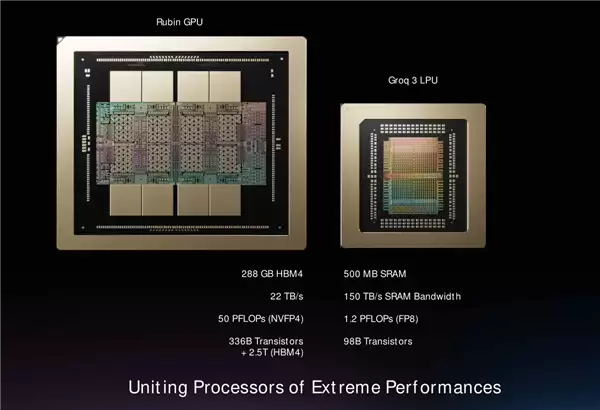
Dally表示做到这样的速度前提是用对了架构,他还以NVFP4精度做了例子对比,用这种精度做一次乘加运算需要消耗10飞焦的能量,但HBM4从外部读取数据大约消耗15皮焦能量,差距是1000倍以上。
改用SRAM缓存的话,读取数据的能耗也会变成10飞焦了,跟计算过程的消耗一个级别。
不过SRAM也不是没代价的,芯片成本比HBM还会高的,GTC大会上NVIDIA发布的LPU芯片LPU30也只能集成500MB SRAM缓存,跟GPU集成的288GB HBM4不是一个量级的。


游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

内存条标签频率参数代表什么含义
内存标签上的频率代表等效数据传输速率(MT s),是厂商经过稳定性测试确认的可靠上限,实际运行需平台支持并开启XMP EXPO才能达到。高频内存对游戏和创意工作有明显提升,日常办公场景差异不大。

荣耀v30语音助手权限开启教程
荣耀V30开启YOYO语音助手需进入系统设置中的智慧助手与智慧语音,开启语音唤醒、语音输入和后台运行权限;跨应用操作还需在应用管理中为YOYO助理开通微信的无障碍服务及通知使用权。

奔驰纯电GLC城市通勤表现实测解析
奔驰纯电GLC起售34 9万元,提供5 6座,轴距3027mm。搭载MB OS智驾系统,AES功能辅助避让,智能泊车支持后轮转向。经过230次实车碰撞测试,配备11个安全气囊,电池毫秒级高压切断。CLTC续航703km,800V架构充电22分钟至80%,百公里耗电13 9kWh。

通勤平价降噪耳机推荐 哪些值得选
200元以内通勤降噪耳机推荐三款:品存W9(179元)以物理隔音和CVC6 0通话降噪见长,续航15小时;KZZ1Pro(168元)专注人声频段,CVC7 0降噪压减背景音;绿联T6(189元)搭载主动降噪与Hi-Res音质,续航30小时。各有所长,按需选择。

手环开机后如何重置操作步骤
小米手环8可通过长按侧边按钮12秒强制重启、设置菜单软重启、ZeppLifeApp远程重启或连接充电底座应急唤醒。这些官方方法可应对死机、无响应等不同故障场景,有效恢复设备正常运行。








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2026-07-07 07:23
2026-07-07 07:22
2026-07-07 07:22
2026-07-07 07:22
2026-07-07 07:22
2026-07-07 07:22
2026-07-07 07:22
2026-07-07 07:21
热门教程
2026-07-07 07:23
2026-07-07 07:22
2026-07-07 07:22
2026-07-07 07:22
2026-07-07 07:22
2026-07-07 07:22
2026-07-07 07:22
2026-07-07 07:21
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程











 热门话题
热门话题
