




Sand.ai开源MagiCompiler:突破编译瓶颈,定义训推性能新高度


机器之心发布
大模型开发者常面临一个两难选择:要速度,还是省显存?
通常情况下,想要跑得快,显存会爆;想省点显存,计算效率又会被频繁的同步和流水线气泡大幅拖垮。原生的 torch.compile 虽然好用,但在面对复杂的跨层优化和 FSDP 显存管理时,依然力不从心。
为了彻底解决这一痛点,Sand.ai 今天正式开源MagiCompiler—— 一款基于 torch.compile 深度优化的即插即用、训推一体编译框架。
MagiCompiler 彻底突破了传统局部编译的界限,实现了推理期整图捕获与训练期 FSDP-Aware 整层编译。
更重要的是,研发团队创新提出Compiler as Manager理念 —— 将编译器从单纯的 “算子优化器” 进阶为全局管理器。它全面接管了计算调度与显存的生命周期,以系统级的底层解法,破解算力与显存墙难题。
代码仓库:https://github.com/SandAI-org/MagiCompiler
核心技术
打破边界的全局调度
1. 打破编译边界:整图与整层编译
传统编译常因复杂的 Python 逻辑频繁触发 Graph Break。研发团队彻底改变了这一点:
推理期:捕获完整的计算图,最大化 Transformer Block 内的算子融合空间。训练期:利用 FSDP 在前向 / 反向传播中 “单层权重全驻留” 的特性,将 Transformer Layer 作为编译单元。这使得编译器可以执行激进的跨算子融合,大幅减少 Kernel Launch 开销和 Global Memory 读写。
2. 内存魔术:启发式重计算(Heuristic Recompute)
在训练大模型时,开发者通常需要手动插入 torch.utils.checkpoint 来控制显存,既繁琐又难以最优。MagiCompiler 引入了智能感知图分割器:
彻底告别手动打点:框架自动分析计算图,识别并优先保留 MatMul、Attention 等计算密集型算子的输出。极致抠显存:对于显存密集型算子,自动在反向传播时进行重计算,从根本上压缩显存峰值而不损失吞吐量。
3. 榨干带宽:JIT 极致 Offload 调度
针对显存瓶颈,研发团队实现了一套极其优雅的权衡调度引擎:
性价比常驻:基于 Profiling 数据,将最划算的权重贪心地常驻在有限的 GPU 显存中。JIT 最晚预取:调度器逆向推导精确的预取时间表,卡在计算前的 “最后一刻” 完成权重拉取,确保 GPU 不囤积多余权重,彻底消除流水线气泡。
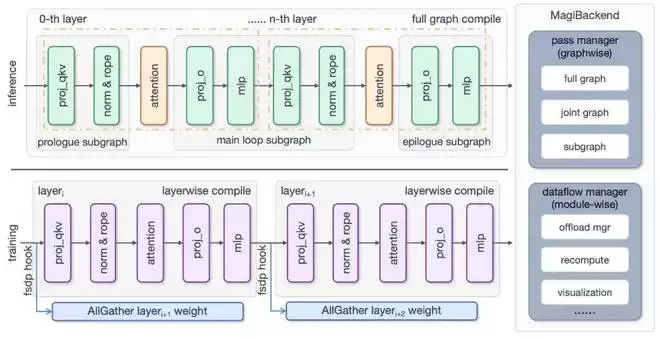
MagiCompiler Overview
性能实测
真正免费的性能午餐
凭借底层的全局调度,MagiCompiler 交出了亮眼的答卷:
训练端表现:在极短时间内,提供高吞吐的保底方案。无需耗时数周死磕 Kernel 或手工魔改底层逻辑,开箱即可解决 Baseline 的 CPU 调度与算子碎片化难题,直接带来 44.7% 提速与 6.2% 显存下降,且精度完全对齐。
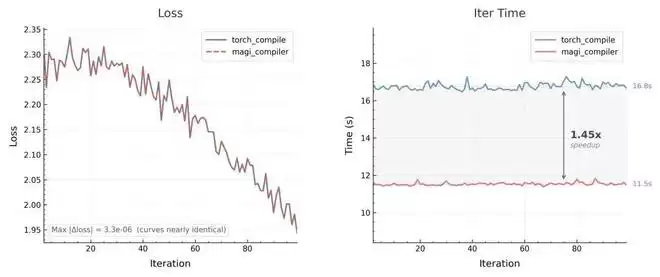
MagiCompiler v.s. baseline
推理端表现:在多模态视频生成场景下,MagiCompiler 展现了极其扎实的硬件泛化能力H100:比最好更好在单机 NVIDIA H100 上,面对主流视频生成模型,MagiCompiler 比目前的领跑方案(如 LightX2V)还要快9%~26%
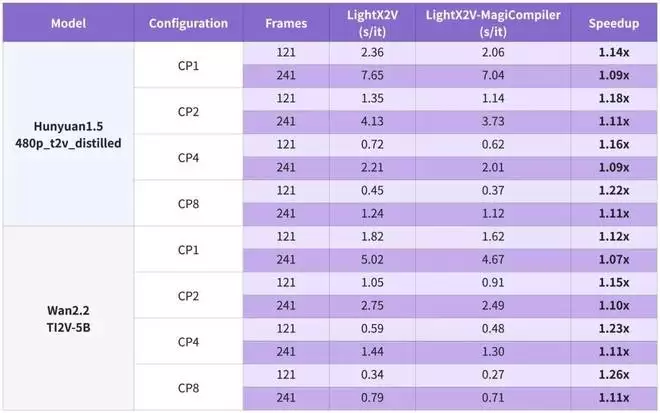
H100 性能测评
RTX 5090:显存受限,近乎实时即便在显存有限的 5090 上,通过 JIT Offload 调度,MagiCompiler 也让 daVinci-MagiHuman 这种超大模型跑出了近乎实时的速度。
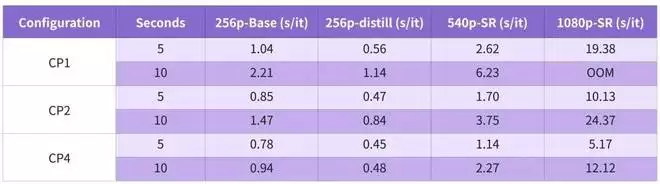
5090 daVinci-MagiHuman 性能指标
极简体验
一行代码,即插即用
强悍的底层性能并不意味着复杂的接入成本。秉持对开发者友好的设计理念,MagiCompiler 只需两个装饰器即可完成接入。
基础编译增强无需修改模型源码,magi_compile 一键装饰 TransformerBlock:

自定义算子注册对于 FlashAttention 或 MoE 等定制化算子,轻松注册并无缝融入重计算策略:

此外,我们内置了强大的自省工具链:开启环境变量,所有隐式的编译产物(反编译字节码、Kernel 代码、Guard 条件等)均会被持久化为人类可读的 Python 文件与图表,让编译器 Debug 变得简单直观。
结语与未来展望
MagiCompiler 正在打破传统编译器的边界。它不仅让我们看到了 torch.compile 迈向全局调度的巨大潜力,更为大模型与多模态架构的规模化落地提供了基础设施。
目前,MagiCompiler 已全面开源。Sand.ai 将持续降低大模型底层的开发门槛,为 AI 社区持续做出贡献。
了解更多信息,欢迎访问 Sand.ai 正式:https://sand.ai

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

OpenClaw自动化内容创作系统使用指南与优势解析
当您搭建端到端自动化内容创作流程时,如果遇到OpenClaw框架无法正常生成内容、格式化文档或执行发布任务的情况,问题根源通常集中在几个核心环节。模型连接异常、关键技能模块失效、浏览器自动化环境故障或记忆索引损坏,都可能导致整个工作流中断。无需担忧,这类系统性问题大多可以通过结构化排查来解决。遵循以

豆包AI专属模型训练步骤详解
训练豆包AI专属模型需遵循五个步骤。首先准备与业务相关的高质量数据,并进行清洗、标注与划分。随后在平台配置环境,选择基础模型并上传数据。接着启动微调训练,关注指标变化。完成后将模型部署为API服务,配置访问权限与限流。对于问答场景,可采用知识库增强的轻量训练方式,快速生效。

YC开源GBrain八层架构打造个人AI第二大脑解决记忆难题
YC总裁开源GBrain项目,旨在解决大模型长期记忆缺失问题。该项目采用八层架构,不仅强化检索能力,更通过认识论层、实体知识图谱和梦境循环等设计,实现信息的溯源、关联与自主整合进化。相比传统RAG,GBrain在测试中展现出显著性能提升,被视为构建“AI第二大脑”的重要探索,有望提升个人生产力。

腾讯AI平台吐司上线 一键生成App原型预览
腾讯推出AI应用生成平台“吐司”,用户通过自然语言描述创意,AI即可自动生成应用原型并打包为APK文件。平台提供创作、分享、灵感交流与搜索四大功能,旨在降低门槛,鼓励用户实现灵感并进行二次创作,构建从创意到原型的闭环社区生态。

arXiv新规严禁AI代写论文 署名作者将连带受罚
arXiv平台出台新规,严惩利用生成式AI制造低质量论文的行为。若发现论文中存在AI生成的未核查内容或虚假引用,所有署名作者将被封禁一年,解封后投稿需先通过期刊评审。新规强调签名即担责,旨在遏制学术不端。陶哲轩对此表示支持,认为加强学术消化环节至关重要。此举回应了AI生成论文泛滥。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
