




UCSD发布AIBuildAI智能体MLE-Bench夺冠,龙虾也能养

新智元报道
编辑:LRST
【新智元导读】UCSD团队推出AIBuildAI智能体,无需编程,仅用自然语言描述任务,即可自动设计、编码、训练、调参并优化AI模型,分工协作,端到端完成AI开发。在OpenAI MLE-Bench测试中,AIBuildAI以63.1%的获奖率位居第一,性能媲美人类专家,推动AI开发迈向全自动化新时代。
近日,加州大学圣地亚哥分校的研究团队开发了AIBuildAI智能体,可以全自动构建AI模型(包括模型设计,代码实现,模型训练,调参,性能评估,迭代优化)。团队成员包括博士生Ruiyi Zhang,Peijia Qin,Qi Cao,Li Zhang,以及该校副教授Pengtao Xie。
开发一个高性能AI模型非常耗时费力,工程师需要反复设计模型、写代码实现模型、构建训练流水线、执行超参数搜索,并根据实验结果对模型进行迭代优化。
这一过程对专业知识的依赖程度极高,人力成本也居高不下,非常耗费时间。
为了解决这一问题,UCSD的研究团队开发了AIBuildAI智能体,充当虚拟的AI工程师或AI科学家,全自动构建AI模型。用户无需编程,只需要用自然语言对任务进行描述,AIBuildAI自动设计模型,写代码实现模型,训练模型,调节超参数,评估模型性能,并根据实验结果对模型进行迭代优化。

项目地址:https://github.com/aibuildai/AI-Build-AI
论文链接:https://github.com/aibuildai/AIBuildAI/blob/main/AIBuildAI_Tech_Report.pdf
OpenAI MLE-Bench测评结果:https://github.com/openai/mle-bench/pull/126
AIBuildAI在OpenAI MLE-Bench基准测试的75个任务上以63.1%的获奖率位居榜首,其表现可媲美经验丰富的AI工程师,实现了从任务描述到可部署模型的端到端自动化。
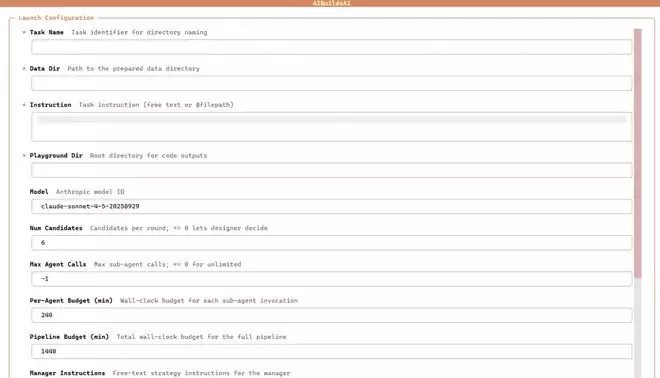

AIBuildAI的设计灵感来源于真实的AI研究团队的工作流程。在典型的AI项目中,技术负责人统筹多条并行探索路线,研究员提出建模策略,工程师实现训练流水线,负责人定期评审结果、分配资源。AIBuildAI将这一工作流抽象为一个多智能体搜索过程:将整个开发周期分解为多个专职智能体协作执行,并通过集中化的管理器进行统一调度。
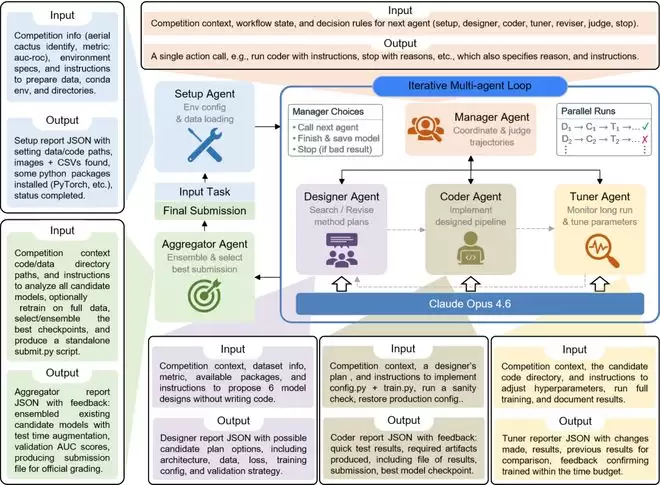
技术核心
管理智能体(Manager Agent)
扮演项目运行负责人的角色,全程不直接写代码或执行训练任务,而是通过读取磁盘上的实验记录来做出下一步决策。他在两种模式之间切换:协调模式下决定下一步应该调用哪一个子智能体;筛选模式下依据训练信号保留有潜力的候选方案并终止无效方案来节约时间以及计算成本,并在进展停滞时触发修订或者终止。
研究员智能体(Designer Agent)
负责想方案和改方案两项核心任务。在设计模式下,他直接探索数据集特征,提出多个差异化、可行性强的建模计划;在修订模式下,他仔细诊断失败原因(过拟合、欠拟合、收敛问题或者数据异常),并提出具体的改进方案供编码智能体重新实现。
编码智能体(Coder Agent)
将设计方案转化为可运行的训练与推理流水线。编码智能体的目标是确保代码正确完整,而非追求最终性能。他会在写完代码后执行一次短时验证运行以确保流水线可以端到端运行,随后将完整训练交由调优器处理。
调优器智能体(Tuner Agent)
接管训练过程,在已有代码基础上专注于性能提升。它采用先快速校准、再决定是否投入的策略:先跑一段简短的热身训练观察学习曲线,再决定是延长当前方案还是进行超参数调整。整个过程在固定计算预算内完成。
系统设计
AIBuildAI在系统层面还具备三项关键特征:
并行效率:多条解决方案轨迹在独立工作空间中并发运行,避免互相干扰,允许系统同时探索多个方法并将资源集中于表现好的候选方案。
可复现性:所有智能体通过存储于磁盘中产出物(方案文档、配置文件、日志、检查点)进行协调,而非依赖内存中的临时信息,确保每一步操作均可事后审查与复现。
安全性:智能体仅被允许写入自身轨迹目录,数据集以只读方式挂载,每次调用均生成可审计的操作日志。
实验结果
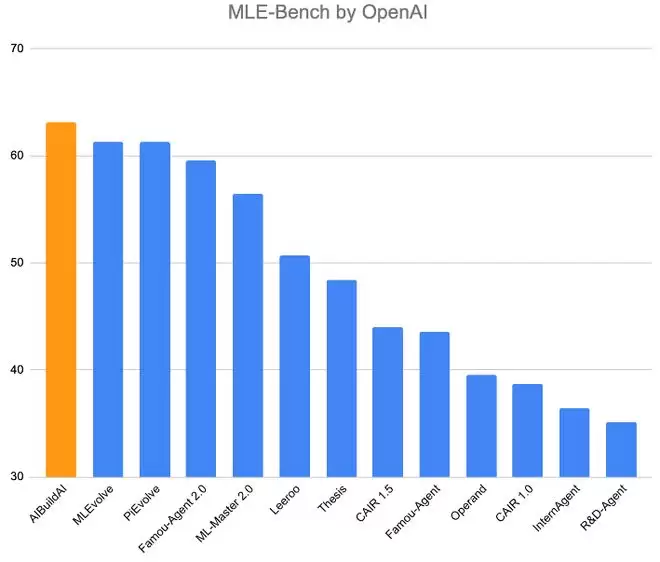
AIBuildAI在OpenAI MLE-Bench基准测试上进行了评估 (https://github.com/openai/mle-bench/pull/126)。MLE-Bench包含了来自Kaggle竞赛的真实任务,涵盖图像分类,目标检测/分割、自然语言理解与生成、时序信号建模以及结构化表格预测等多个类别,共75个任务,要求系统完成从原始数据到可提交模型的全流程开发。目前,AIBuildAI以63.1%的综合获奖率位居MLE-Bench总榜第一。上图展示了AIBuildAI(橙条)的综合性能在所有的对比方法中实现了性能最佳。
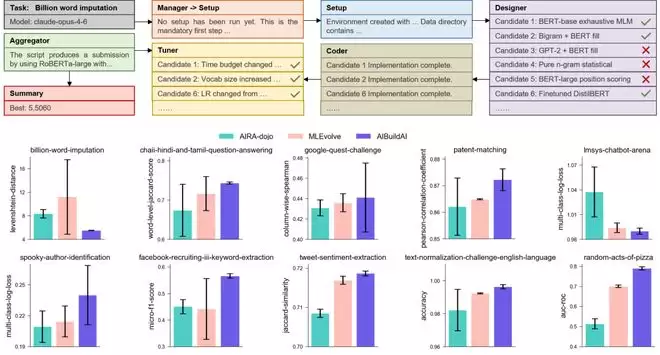
上图展示了AIBuildAI 在语言理解与生成任务上的详细结果。上半部分以Billion Word Imputation为例,完整呈现了 AIBuildAI 各智能体的运行轨迹:Manager依次调度Setup、Designer(提出6个候选方案)、Coder(实现流水线)和 Tuner(迭代调参),最终Aggregator以RoBERTa-large为基础生成提交文件,取得5.5060的最优分数。下半部分对比了AIBuildAI与AIRA-dojo、MLEvolve在10个具体语言任务上的性能表现。
AIBuildAI(紫色)在 chaii-hindi-and-tamil-question-answering、patent-matching、tweet-sentiment-extraction、text-normalization-challenge-english-language、random-acts-of-pizza 等多个任务上均取得最优成绩,充分验证了 AIBuildAI 在多样化语言任务上的泛化能力。
总结
AIBuildAI通过将AI开发流程分配到包括设计、编码、调优与协调等任务的专职智能体,并以基于产出物的状态管理将各个智能体紧密协同,实现了端到端自动化AI工程。
不同于以往将代码生成作为核心范式的单体系统,AIBuildAI显示建模了训练动态监控、早停机制与超参数调整等关键环节,更贴近真实工程师团队的工作方式。
AIBuildAI在MLE-Bench的75个任务上,以63.1%的获奖率位居第一,证明了结构化多智能体协作在复杂工程工作自动化上的可行性,也为迈向媲美人类专业工程师的自动AI系统提供了清晰的技术路线。
参考资料:
https://github.com/aibuildai/AI-Build-AI

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

吉利发布首款原生Robotaxi Eva Cab 千里科技AI全栈赋能
4月24日,在备受瞩目的第十九届北京国际汽车展览会上,吉利汽车集团正式揭晓了其重磅新品——中国首款原生正向开发的Robotaxi(自动驾驶出租车)原型车Eva Cab。这款车型不仅是前沿概念的展示,更是一款具备完整落地潜力的产品,其核心驱动力源自千里科技提供的全栈式Robotaxi解决方案。该方案深

Akamai与NVIDIA合作推动分布式AI推理从内容分发迈向智能分发
自2010年在中国设立团队以来,Akamai已深耕本地市场十六年。在服务中国企业出海的漫长征程中,其团队展现出卓越的稳定性与战略专注度。 回顾NVIDIA GTC 2026,其CEO黄仁勋曾预言,AI推理的规模将迅速达到训练负载的数十亿倍。进入2026年,行业共识已然明确:AI大模型竞争的焦点,正从

跑车品牌宣布暂停全面电动化转型计划
莲花集团发布“Focus2030”战略,宣布调整全面电动化路线,将同步发展燃油、混动及纯电车型,直至市场成熟。未来将推出燃油跑车Emira420,并于2028年上市搭载V8混动系统的超跑Type135,战略重心转向追求更高利润率。

大语言模型如何实现类人对话与思考的智能原理
我们每天都在与大语言模型(LLM)对话,一个直观的感受是,它们似乎真的“懂”我们在说什么,尽管偶尔也会“胡言乱语”。观察它们输出的思维链,那种逐步推理的语言痕迹,更让人觉得它们仿佛具备了某种思考能力。 这引出了一个核心问题:LLM的语言和思考能力,究竟是一种怎样的能力?这些能力又是如何通过其底层的实

ICML 2026论文解读:TGO标量反馈对齐视觉生成模型
生成模型的偏好对齐,可能正在进入一个新的阶段。 过去几年,大模型在训练后优化(post-training)最主流的方法,是让模型从“成对偏好”中学习。无论是经典的RLHF,还是后来更简洁的DPO,都绕不开同一个前提:反馈必须成对出现。 但在真实世界里,反馈往往不是这样。用户给一个结果打分、系统记录一








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
