




英伟达变革:7天进化为智能体,重塑工程师与GPU专家格局


免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
机器之心编辑部
这应该是今天刚刚出炉的、最炸裂的文章。
在很多算子开发的微信群组,已经掀起了轩然大波。
「这或许是超人类智能在软件领域的真正首次展露。」英伟达许冰刚刚在 X 上发出了如此断言。他所评论的,正是他与 Terry Chen 和 Zhifan Ye 为共同一作的一项英伟达新研究AVO

在本周四刚刚提交到 arXiv 上的这项研究中,英伟达构建了Agentic Variation Operator(AVO),这是一类新型进化变异算子,它用自主编码智能体取代了经典进化搜索中固定的变异、交叉和人工设计的启发式方法,并取得了相当震撼的实际表现。
许冰表示:「在一些经过高度优化的注意力机制工作负载中,智能体在没有人工干预的情况下,即可在优化循环中连续搜索 7 天,从而超越几乎所有人类 GPU 专家。」——AVO 的如此表现可能会让许多内核/DSL 瑟瑟发抖。

黄之鹏的 X 推文
有意思的是,在 X 推文中,许冰还分享说一年半之前他与 Terry Chen 刚开始在英伟达研究智能体编程时,他们还不懂 GPU 编程,「所以从一开始我们就致力于开发完全自动化、无需人工干预的系统。」他们称之为「盲编程(blind coding)」。
「在过去一年半的时间里,我们两人在两个智能体系统中开发了四代智能体。从第二代开始,这些智能体栈就开始自我演化。现在每个智能体的代码行数都约为 10 万行(非空代码)。」
他还重点强调了 AVO 背后的重大意义:「我敢打赌:盲编程是软件工程的未来。人类认知能力是瓶颈。
下面我们就来详细看看这篇或将开启「盲编程」新时代的论文究竟做出了什么贡献。

论文标题:AVO: Agentic Variation Operators for Autonomous Evolutionary Search论文地址:https://arxiv.org/abs/2603.24517v1
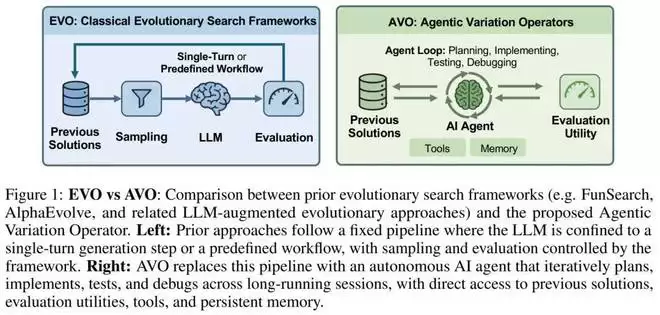
大语言模型已成为进化搜索(Evolutionary Search)中的强大组件,它以学习代码生成取代了手工设计的变异算子。在这些系统中,LLM 根据选定的父代生成候选解,而通常基于启发式的框架则负责父代采样、评估和种群管理。这种组合在数学优化和算法发现领域取得了显著成果,包括 FunSearch 和 AlphaEvolve 等旗舰系统。
然而,将 LLM 限制在预设流程中的候选解生成功能从根本上限制了其发现能力:每次调用仅产生一个输出,无法主动查阅参考资料、测试其更改、解读反馈或在提交候选方案前修正方案。对于那些已经过极致人工调优、需要深度迭代工程才能进一步改进的实现,这种限制尤为突出。
研究者针对注意力机制背景下的这一问题进行了研究。注意力机制是 Transformer 架构的核心算子,也是优化最密集的 GPU 算子之一。FlashAttention 系列 和英伟达的 cuDNN 库已将历代 GPU 的注意力吞吐量推向硬件极限;在最新的 Blackwell 架构上,FlashAttention-4 (FA4) 和 cuDNN 均需要数月的人工优化。若要超越这些实现,需要与开发环境进行持续、迭代的交互:研究硬件文档、分析分析器(Profiler)输出以识别瓶颈、实现并测试候选优化方案、诊断正确性故障,并根据积累的经验修正策略。
深度智能体(Deep Agents)的最新进展表明,结合了规划、持久内存和工具使用能力的 LLM 可以自主处理此类多步工程工作流,应用范围涵盖从解决复杂的 GitHub 问题到生成关键深度学习软件。这促使 LLM 在演化搜索中扮演一种截然不同的角色:与其将其限制在固定流水线内,不如将深度智能体提升为变异算子本身。
为此,英伟达提出了智能体式变异算子(Agentic Variation Operators, AVO)。在这种模式下,一个自导向的代码代理取代了以往基于单轮 LLM 或固定工作流系统中的变异和交叉过程。AVO 智能体拥有访问所有先前方案、特定领域知识库和评估工具的权限。它能自主决定查阅内容、修改对象以及评估时机,从而实现在长周期内的持续改进。
为了验证其有效性,英伟达将 AVO 应用于NVIDIA Blackwell B200 GPU上的多头注意力(MHA)内核,并直接与专家优化的 cuDNN 和 FlashAttention-4 内核进行对比。在无需人工干预、长达 7 天的连续自主演化中,智能体探索了超过 500 个优化方向,演化出 40 个内核版本。最终生成的 MHA 内核在 BF16 精度下达到了最高1668 TFLOPS的吞吐量,在测试配置中分别超越 cuDNN 高达3.5%,超越 FlashAttention-4 高达10.5%
英伟达对智能体发现的优化方案进行分析后发现,这些优化涵盖了内核设计的多个层面,包括寄存器分配、指令流水线调度和负载分布,反映了真正的硬件级推理。实验表明,在 MHA 上发现的优化技术能有效迁移至分组查询注意力(GQA):智能体仅需 30 分钟的额外自主适配,即可完成演化版 MHA 内核对 GQA 的支持,其性能相比 cuDNN 提升高达 7.0%,相比 FlashAttention-4 提升 9.3%。
该研究的主要贡献如下:
提出代理式变异算子(AVO):这是一类新型的演化变异算子,将智能体从单纯的候选生成器提升为变异算子。智能体通过与环境的迭代交互,自主探索领域知识、实施修改并验证结果。实现 SOTA 性能:在 NVIDIA B200 GPU 上,研究者在基准测试配置中实现了最顶尖的 MHA 吞吐量,达到 1668 TFLOPS,性能超越 cuDNN 高达 3.5%,超越 FlashAttention-4 高达 10.5%。此外,他们证明了这些优化可以轻松迁移至 GQA,仅需 30 分钟的自主演化即可获得显著性能增益。微架构优化分析:研究者对智能体在基准测试设置下发现的微架构优化进行了详细分析,表明代理进行的是真正的硬件级推理,而非表层的代码变换。
告别流水线
AI 智能体成为真正的「进化操盘手」
在传统的基于 LLM 的进化搜索框架中,模型往往被困在固定的流水线里,仅仅充当候选代码的生成器。它们每次调用只能输出一次结果,无法主动查阅参考资料、测试代码、理解反馈或在最终提交前修正策略。对于需要深度、反复迭代的顶级硬件优化任务来说,这种限制尤为致命。
AVO 打破了这一局限,将「变异算子」实例化为一个自我驱动的智能体循环。这个 AI 智能体可以自由查阅之前的代码版本记录、调用领域专属的知识库(如 CUDA 编程指南和 PTX 架构文档),并根据执行反馈来主动提出、修复、批判和验证代码修改。
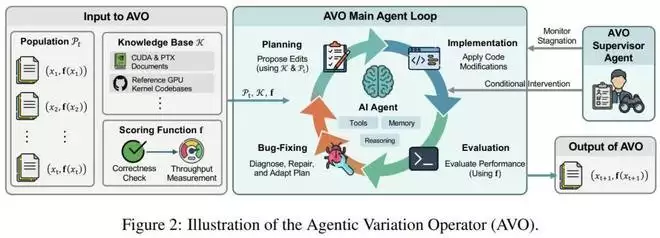
简而言之,AVO 将 AI 从被动的「代码生成器」提升为了掌握全局的「进化操盘手」。
7 天自主运转
在 Blackwell 架构上击败顶尖基准
研究团队将 AVO 部署在一项极具挑战性的任务上:在 NVIDIA Blackwell (B200) GPU 上优化多头注意力(Multi-head Attention,简称 MHA)核心代码。注意力机制是目前 Transformer 架构的核心,也是 AI 芯片上被优化得最极致的计算目标之一。
在完全没有人类干预的情况下,AVO 智能体连续自主运行了 7 天
在这 7 天里,智能体在后台探索了超过 500 个优化方向,并最终提交了 40 个有效迭代版本。最终,它生成的 MHA 核心在 BF16 精度下实现了高达 1668 TFLOPS 的吞吐量。
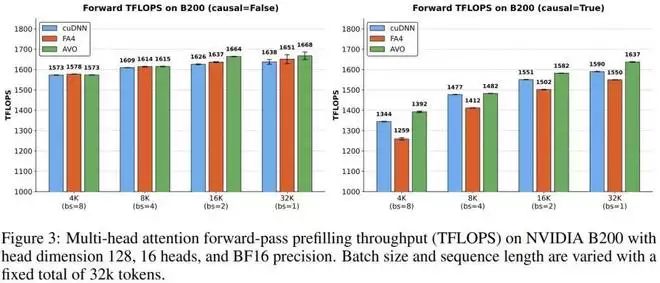
在基准测试中,AVO 交出的答卷令人惊叹:
相比英伟达最新为 Blackwell 定制的闭源 cuDNN 库,吞吐量提升了最高3.5%相比目前最前沿的开源基准 FlashAttention-4,吞吐量提升了最高10.5%
强大的泛化能力
30 分钟迁移至分组查询注意力
更令人印象深刻的是,这些由智能体发现的底层微架构优化,并非只针对特定场景的过度拟合。当研究人员要求 AVO 将优化好的 MHA 核心适配到如今大模型常用的分组查询注意力(Grouped-query Attention,简称 GQA)时,智能体仅用了约 30 分钟的自主调整就完成了任务。
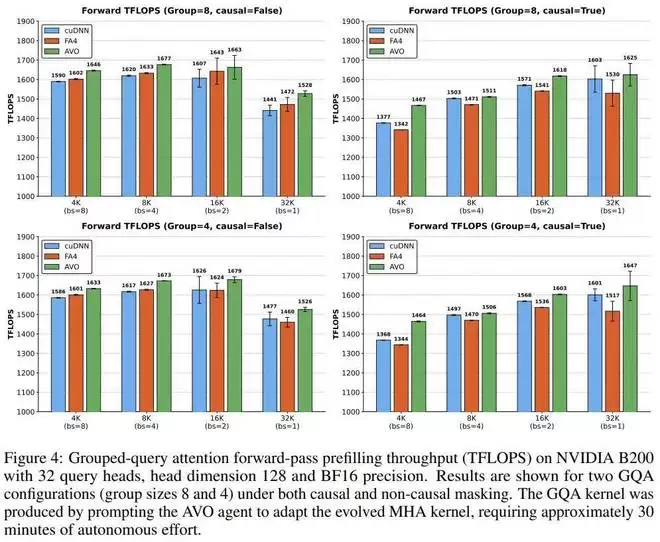
在 GQA 的测试中,AVO 依然保持了绝对的领先优势,性能比 cuDNN 高出最高 7.0%,比 FlashAttention-4 高出最高 9.3%。这表明,智能体在 MHA 进化过程中发现的计算和内存访问优化模式,能够有效泛化到具有不同计算特征的 GQA 任务中。
深入底层的微架构推理
分析 AVO 提交的代码变更可以看出,AI 智能体并非在做表面功夫,而是进行了真正深入硬件底层的逻辑推理 :
无分支累加器重缩放:通过消除条件分支,智能体排除了 warp 同步的开销,并替换了更轻量级的内存屏障,使得非因果注意力的吞吐量一次性提升了 8.1%。纠错与张量核心(MMA)流水线重叠:智能体重新组织了执行流水线,将原本顺序执行的依赖关系转化为交叠的流水线执行,大幅减少了硬件的空闲等待时间。跨 warp 组的寄存器重新平衡:智能体通过分析性能分析器的数据,发现某些运算组因为寄存器不足而导致数据溢出至慢速本地内存。它果断对 Blackwell 的 2048 个寄存器预算进行了重新分配,进一步压榨出 2.1% 的性能提升。
英伟达的这项研究证明,AI 智能体已经具备了处理多硬件子系统(如同步、内存排序、流水线调度和寄存器分配)联合推理的能力。AVO 作为一种不局限于特定领域的进化变异算子,为未来的自动化软件系统优化指出了一条明路。它不仅能用于 AI 芯片和深度学习底层生态的开发,未来更有望在所有对算力有着极致苛求的科学和工程领域中大展拳脚。
AI 智能体的自我进化能够达到这种水平,你怕了吗?
https://x.com/bingxu_/status/2036983004200149460?s=46
https://x.com/nopainkiller/status/2036986666410532972

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

工信部发布防范 OpenClaw(“龙虾”)开源智能体安全风险“六要六不要”建议
工信部发布“六要六不要”,为OpenClaw(“龙虾”)开源智能体安全风险划出红线 近日,工业和信息化部网络安全威胁和漏洞信息共享平台发布了一份重磅文件,针对当前热门的OpenClaw(因其图标酷似龙虾,业内常昵称为“龙虾”)开源智能体,提出了清晰的安全使用指引——“六要六不要”。这份建议可不是空穴

荣耀 CEO 李健:荣耀机器人全栈自研,将聚焦消费市场
荣耀CEO李健详解机器人战略:全栈自研,聚焦三大核心消费场景 荣耀春季旗舰新品发布会圆满结束后,关于公司未来发展的蓝图更加清晰。在随后的媒体沟通会上,荣耀CEO李健不仅公布了年度销售目标,更首次系统性地阐述了荣耀在机器人领域的完整战略规划与市场布局。 在探讨机器人业务发展方向时,李健明确了荣耀的坚定

别只盯着“上门装龙虾赚26万”!看懂OpenClaw背后的“意图入口”大战
别再只关注“上门装龙虾赚26万”!深度解读OpenClaw背后的“意图入口”新战争 最近科技行业的热潮,充满了戏剧性的现实色彩。一只“红色龙虾”AI智能体搅动了整个市场:有人通过提供安装服务,收取每次五百元,短短几天就赚取二十六万元收入;腾讯大厦前甚至排起长队,大家竞相领取免费的安装体验权限。这场全

openclaw安装配置
一、系统要求 在开始安装 OpenClaw 之前,请务必确认您的计算机满足以下最低配置要求。这如同搭建房屋前检查地基,是确保后续安装流程顺利、软件稳定运行的前提。更高的硬件配置将为复杂任务处理和流畅体验提供有力保障。 操作系统:支持 Windows 10 及以上版本、macOS 最新稳定版,以及主流

自研第一个SKILL-openclaw入门
自研第一个SKILL:手把手教你开发openclaw自定义技能 当你成功构建好openclaw之后,如何让它真正“智能”起来?关键在于为其开发SKILL——这些技能是openclaw的“内功心法”,决定了它能帮你做什么、做多好。 本文将带你亲自动手,从零开始开发你的第一个openclaw自定义技能,








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程

















