




谷歌AI论文涉学术造假,洗白内存占用了900亿刀?

编辑|泽南、杨文
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
没想到这次大面积市场震荡,还引出了学术大瓜。
本周五晚,谷歌的学术不端事件成为了 AI 圈的焦点。
来自苏黎世联邦理工学院(ETH Zurich)的博士后高健扬在知乎发布文章,表示 Google Research 论文「TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate」中,有关已有的 RaBitQ 向量量化算法的描述、理论结果对比、实验对比均存在严重问题,且相关问题早在论文投稿前便已被明确指出,却被作者方刻意忽视。

作为能够干翻一片「主线」逻辑公司的 AI 研究,TurboQuant 在业界的含金量似乎毋庸置疑。然而谁能想到,这篇被谷歌推上神坛、拥有千万级曝光量的 ICLR 顶会论文,其最核心的技术底座却深陷「抄袭」疑云。
引发内存股震荡的 TurboQuant
谷歌的 TurboQuant 论文最近火出了 AI 研究领域,这篇被全球 AI 研究顶会 ICLR 2026 接收的论文介绍了一种压缩算法,声称能够将大语言模型的 KV 缓存内存占用减少至少 6 倍,速度提升高达 8 倍,且精度零损失
TurboQuant 于 2025 年 4 月公开于预印版论文平台 arXiv 上,2026 年 1 月被 ICLR 2026 接收,3 月 24 日经谷歌研究博客介绍引发了巨量关注。
谷歌在 X 上的宣传贴浏览量达到了上千万。
在 AI 大模型的推理时,AI 每次生成一个新词都需要「回顾」对话历史(上下文),这部分内容被存储于 KV 缓存上。因此,KV 缓存占用的内存往往会成为限制大模型速度和成本的最大瓶颈。TurboQuant 提出的极限无损压缩方法效果惊人,由于能够大幅降低运行大模型所需的硬件资源,它直接冲击了市场对内存芯片爆发式增长的预期。
在谷歌博客发布的当天,美国内存股集体暴跌,闪迪一度跌 6.5%,希捷科技跌超 5%,西部数据跌超 4%,美光科技跌 4%。市场一天蒸发的市值超过了 900 亿美元
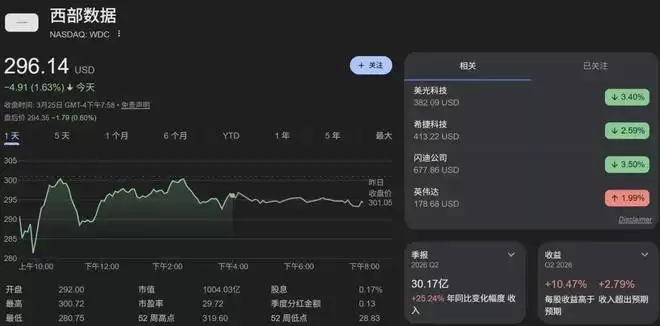
这项被谷歌大肆宣传的技术到底是怎么做到的?简单来说,它用一套精妙的方法解决了内存消耗的死结。
TurboQuant 通过两阶段压缩实现这一目标:第一阶段利用「随机旋转」和 PolarQuant 机制将高维向量映射到极坐标,实现极限压缩;第二阶段利用 Quantized Johnson-Lindenstrauss (QJL) 变换,使用仅 1 bit 的空间来修正内积计算的偏差。
然而,正是这部分技术,成为了引爆学术丑闻的导火索。
ETH Zurich 的高健扬博士列举证据表示,这项被谷歌宣传的「革命性」核心机制并非谷歌首创,其在两年前就已经被他的团队完整提出。
更令人气愤的是,谷歌在其论文中刻意「回避」和「淡化」了先行技术。
RaBitQ 作者公开质疑:
TurboQuant 的核心方法,两年前就有
RaBitQ 系列论文于 2024 年发表,提出了一种高维向量量化方法,并从理论上证明其达到了理论计算机顶级会议论文给出的渐近最优误差界。
RaBitQ 和扩展版分别发表于顶级会议 SIGMOD 2024 和 SIGMOD 2025。

RaBitQ 的核心思路之一,是在量化前对输入向量施加随机旋转(random rotation / Johnson-Lindenstrauss 变换),利用旋转后坐标分布的性质做向量量化,在理论上实现最优误差界。
而 TurboQuant 的方法核心同样是在量化前对输入向量施加随机旋转(Johnson-Lindenstrauss 变换),这一点,甚至是 TurboQuant 作者自己在 ICLR 审稿回复中亲口描述的。

然而,TurboQuant 论文全程刻意回避了与 RaBitQ 在方法上的直接关联,反而在正文中将 RaBitQ 描述为 grid-based PQ,并且在描述中忽略了 RaBitQ 中核心的 random rotation 步骤,有意模糊两者之间的传承关系。
TurboQuant 的第二作者 Majid Daliri 早在 2025 年 1 月便曾主动联系高健扬,请求协助调试其自行用 Python 复现的 RaBitQ 代码,这说明 TurboQuant 团队对 RaBitQ 的技术细节知之甚详。
既然早已知晓并请教过原作者,为何在最终的论文中不进行合理的引用和客观对比?
高健扬团队在发现这些问题后本着学术严谨的态度,从 2025 年 5 月起就通过邮件与 TurboQuant 团队进行了多次私下沟通,并明确指出了其中的事实性错误。
然而 TurboQuant 团队以「随机旋转已成为领域标准技术,无法引用每一个使用它的方法」为由拒绝修正。随后,这篇论文不仅被推上了 ICLR 2026,还成为了全球关注的焦点。
这样的学术叙事如果不被纠正,就会逐渐成为共识。高健扬团队最终下场列出了几项指控。
三项具体指控
高健扬在文章中列出了三项具体问题。
第一,系统性回避技术相似性。
TurboQuant 不仅未能正面讨论两者方法的结构联系,反而还将原本正文中对 RaBitQ 不完整描述移到了附录中,这一举动甚至发生在审稿人已明确指出「RaBitQ and variants are similar to TurboQuant in that they all use random projection」并要求充分讨论之后。
TurboQuant 作者回复称「随机旋转和 Johnson-Lindenstrauss 变换的使用已经是该领域的标准技术,我们不可能引用每一篇使用了这些方法的论文」。
高健扬团队认为这一回应是在转移矛盾:作为在相同问题设定下率先将随机旋转(Johnson-Lindenstrauss 变换)与向量量化结合、并建立最优理论保证的具体先行工作,RaBitQ 应当在文中被准确描述,其与 TurboQuant 方法的联系应当充分讨论。
第二,错误描述 RaBitQ 的理论结果。
TurboQuant 论文将 RaBitQ 的理论保证定性为「次优(suboptimal)」,并归因于「较粗糙的分析(loose analysis)」,却未给出任何推导、对比或证据。
事实是在拓展版 RaBitQ 论文(arXiv:2409.09913)的 Theorem 3.2 中,已经严格证明 RaBitQ 的误差界达到了理论计算机顶级会议论文(Alon-Klartag, FOCS 2017)给出的渐近最优误差界。因为这一结果,高健扬团队被邀请至理论计算机科学顶级会议 FOCS 的 Workshop 进行报告。
2025 年 5 月,高健扬团队与 TurboQuant 的第二作者 Majid Daliri 进行了多轮详细的邮件技术讨论,逐条澄清了这一错误解读,Majid Daliri 也明确表示已告知全体共同作者。然而这一错误定性在论文经历完整审稿、被接收乃至大规模宣发的全过程中,始终未被更正。
第三,刻意制造不公平的实验条件。
TurboQuant 论文测试 RaBitQ 速度时,既未使用最新开源的 C++ 实现,转而用了 Majid Daliri 自己翻译的 Python 版本,又将 RaBitQ 限制在单核 CPU、关闭多线程的条件下运行,而 TurboQuant 自身则使用 NVIDIA A100 GPU 进行测试。这两层系统性的不公平条件均未在论文中明确披露。
Majid Daliri 本人在 2025 年 5 月的邮件中曾承认了单核限制这一情况,但论文仍将由此得出的「RaBitQ 比 TurboQuant 慢数个数量级」的结论呈现给读者,却未附任何说明。
选择公开发声
高健扬表示,他们在 2025 年 11 月便发现 TurboQuant 提交了 ICLR 2026,随即联系 ICLR Program Committee Chairs,但未获任何回应。
2026 年 1 月论文正式被接收后,谷歌开始通过最新渠道大规模推广,相关内容在社交媒体上的浏览量迅速达到数千万次。
2026 年 3 月,高健扬团队再次正式致函 TurboQuant 全体作者,要求说明与更正。目前收到的回复来自第一作者 Amir Zandieh,承诺会在 ICLR 会议正式结束后修正问题二和问题三,但拒绝就技术相似性问题作出任何讨论。
高健扬已在 ICLR OpenReview 平台发布公开评论,并向 ICLR General Chairs、PC Chairs 及 Code and Ethics Chairs 提交了包含完整证据的正式投诉,同时表示将在 arXiv 发布关于 TurboQuant 和 RaBitQ 的详细技术报告,并保留进一步向相关机构反映的选项。

他在文末写道:「一篇论文被 Google 以数千万曝光量推向公众,在这种体量下,论文中错误的叙事不需要主动传播,只需要不被纠正,就会自动成为共识。
目前,高健扬等人的主张得到了很多人的支持。

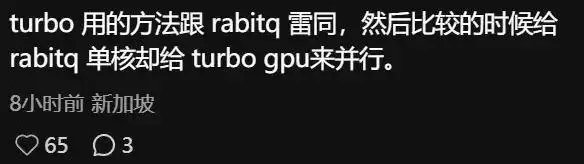
很多人表示,谷歌在 AI 研究上这样的做法已经不是第一次了。
或许谷歌与 ICLR 最新需要给出解释。
参考内容:
https://zhuanlan.zhihu.com/p/2020969476166808284
https://x.com/gaoj0017/status/2037532673812443214
https://openreview.net/forum?id=tO3ASKZlok
https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

高通AI研究:用更少文字解决复杂问题的智能思考方法
这项由高通AI研究院主导的突破性研究,于2026年3月以预印本论文形式发布。它直指一个长期困扰AI发展的核心痛点:当我们试图让AI模仿人类“逐步思考”时,它们往往会陷入一种低效的“话痨”模式,产生大量冗余、重复的文本,既拖慢了响应速度,也浪费了宝贵的计算资源。 不妨做个类比:你向一位聪明的学生请教数

华中科大团队突破AI空间感技术解决方向感缺失难题
你是否曾向AI助手发出过“描述桌子右边有什么”或“找找沙发后面的东西”这样的指令,却得到了令人困惑的回应?这背后的核心原因在于,当前主流的多模态大模型虽然具备出色的物体识别能力,却普遍缺乏对三维空间的真实“感知”。它们如同仅通过二维照片认识世界,难以准确判断物体的相对方位、深度距离以及复杂的遮挡关系

摩尔线程携手光轮智能战略合作 共研高置信度仿真数据合成方案
近日,国内领先的GPU企业摩尔线程与前沿AI公司光轮智能正式宣布达成深度战略合作。双方的核心目标,是共同构建一套高置信度、可规模化的仿真数据合成解决方案。此举被业界广泛解读为,旨在为具身智能(Embodied AI)的长期演进与发展,筑牢一项自主可控的关键性数字基础设施。 具身智能,简而言之,是赋予

IBM推出VAREX基准测试评估AI解读政府表格能力
这项由IBM Research主导的研究,于2026年3月正式发布于arXiv预印本平台(论文编号:arXiv:2603 15118v1)。研究团队构建了一个名为VAREX的全新评估基准,其核心目标在于系统性地评测各类AI模型在理解与提取政府表格信息上的真实性能。 我们可以将AI模型想象成一位新入职

德克萨斯农工大学揭示AI视频生成时空错乱原因
德克萨斯农工大学的研究团队近期取得了一项突破性进展,揭示了当前AI视频生成技术中一个普遍存在却长期被忽略的核心缺陷。你是否也曾感到AI生成的视频“总有些别扭”?比如蜂鸟振翅显得过于缓慢,或者人物动作的节奏如同水下镜头般迟滞——你的直觉没错,问题的根源恰恰在于AI对“时间”的感知完全失准。 研究人员将








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
