




彻底解决openclaw的tokens焦虑

彻底解决 OpenClaw 的 Token 限制与使用成本焦虑
背景与需求
尽管市场上不乏宣称永久免费、不限 Token 的 AI 服务,但这些方案通常通过严格限制请求频率或并发数来控制运营成本。客观地说,这类限制并未从根本上解决用户对长期使用成本与额度限制的深层焦虑。要真正实现无后顾之忧的模型调用,目前最可靠的路径是接入本地部署的大语言模型。
值得注意的是,在 OpenClaw 的各类技术社群中,仍有大量开发者对如何配置本地模型集成感到陌生或遇到障碍。本文将以当前最热门的本地模型管理工具——Ollama 为例,提供一份完整的实战配置指南。
环境与工具准备
为保证操作步骤的可复现性,以下列出本文演示所涉及的核心软件环境:
操作系统:Debian 12(Linux)
Ollama 版本:0.16.1
OpenClaw 版本:2026.2.14
测试用大模型:glm-4-7b-flash(智谱 GLM-4 轻量版)
详细版本信息可参考下图界面:
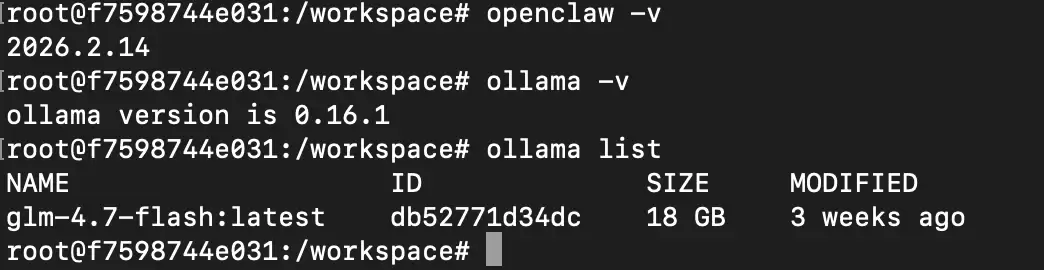
Ollama 本地模型服务部署
安装必要依赖与 Ollama
# 更新系统并安装基础工具
apt update -y
apt install zstd git curl jq -y
# 一键安装 Ollama(官方脚本)
curl -fsSL https://ollama.com/install.sh | sh
启动 Ollama 服务并进行基础测试
# 设置服务监听地址并启动后台服务
export OLLAMA_HOST=0.0.0.0
nohup ollama serve >/dev/null 2>&1 &
# 查看已拉取的模型列表,验证服务状态
ollama list
若服务启动正常,命令行将返回类似下方的模型列表,表示 Ollama 服务已就绪:

接下来,我们可以通过命令行与本地模型进行一次简单的对话测试:
ollama run glm-4.7-flash:latest
输入问候语,观察模型的回复响应:
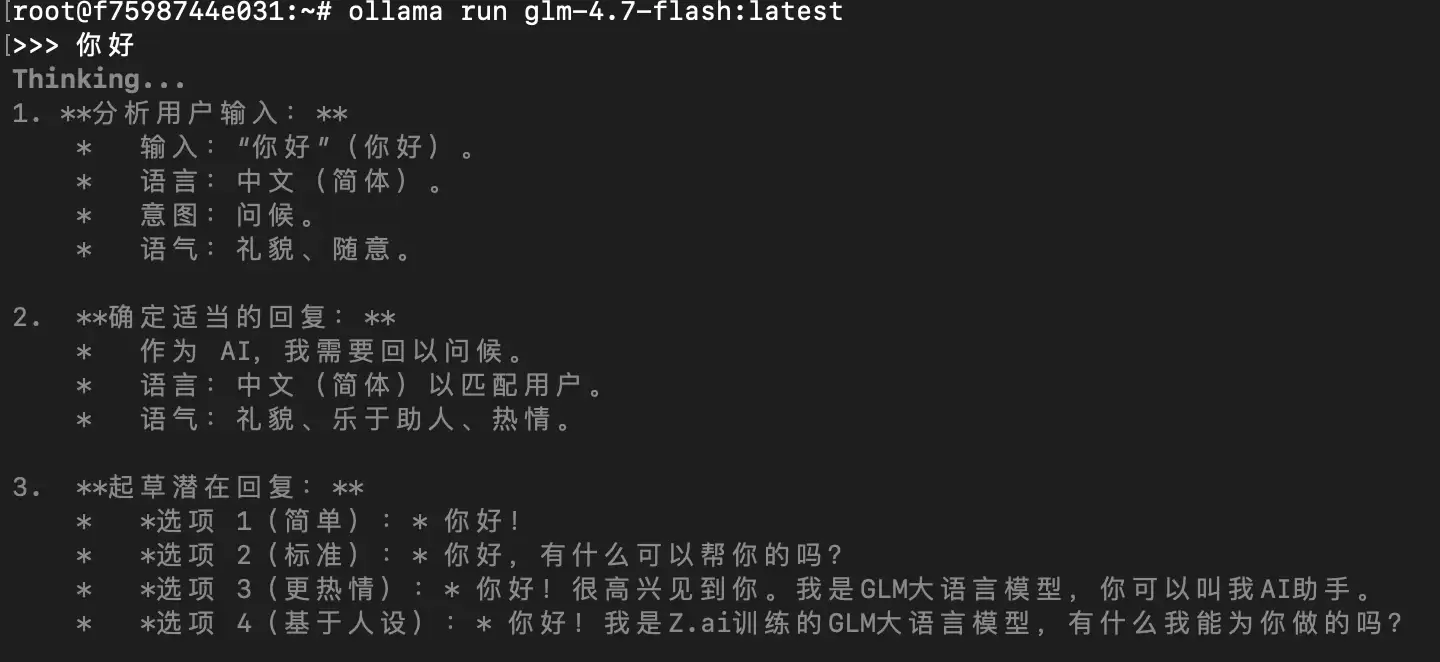
将 Ollama 本地模型接入 OpenClaw
将 Ollama 集成至 OpenClaw 框架,通常有三种主流配置方式:
最基础的方法是直接手动编辑 OpenClaw 的主配置文件 `openclaw.json`。
更便捷的方式是利用 OpenClaw 后续版本内置的交互式配置向导,只需在终端执行 `openclaw config` 命令即可逐步完成设置。
这里需要注意一个关键点:在配置向导的供应商选择步骤中,若未直接看到 Ollama 分类,建议先选择“所有”选项。随后在模型列表页面,便可定位到 Ollama 提供的本地模型。
不过,目前最简单高效的集成方案,是直接使用 Ollama 自身提供的 OpenClaw 专用配置命令。下面我们演示此方法。
执行引导配置命令:
ollama launch openclaw --config
命令执行后,系统会展示可用模型列表。请注意:为避免下载体积庞大的在线推荐模型,请直接从“本地模型”区域选择你已预先拉取的 `glm-4.7-flash` 模型,并按回车确认。
后续步骤中,可选择立即启动服务,或跳过并改用 OpenClaw Gateway 来管理服务启动。
配置完成后,即可在 OpenClaw 中测试与本地模型的完整对话流程:
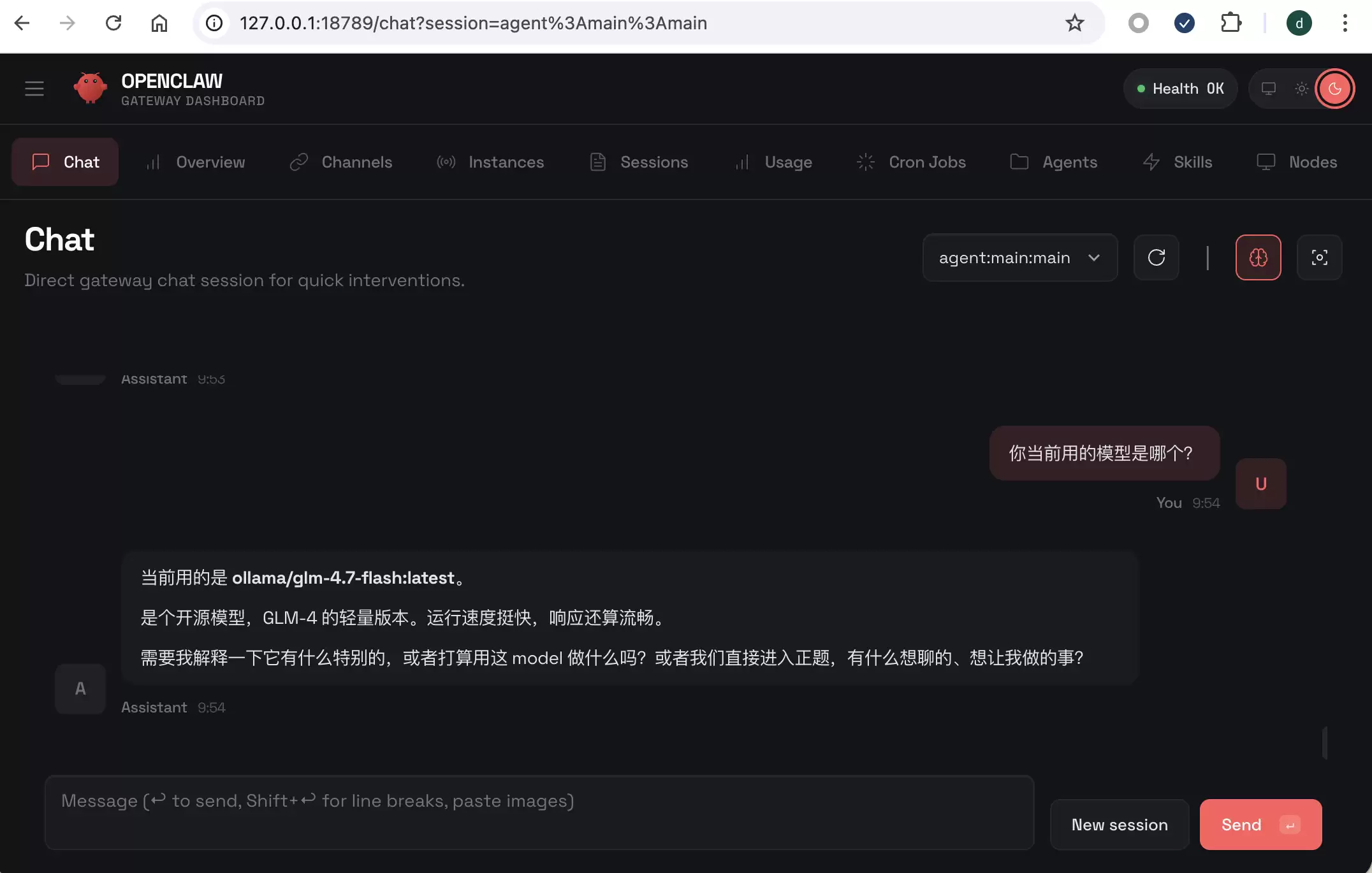
当成功收到来自本地模型的连贯回复时,即表明集成配置已全部完成。
对于习惯直接修改配置文件的开发者,这里也附上 `openclaw.json` 中与 Ollama 集成的关键配置片段,以供参考:
配置文件:openclaw.json
{
"agents": {
"defaults": {
"compaction": {
"mode": "safeguard"
},
"maxConcurrent": 4,
"model": {
"primary": "ollama/glm-4.7-flash:latest"
},
"subagents": {
"maxConcurrent": 8
}
}
},
...
"models": {
"providers": {
"ollama": {
"api": "openai-completions",
"apiKey": "ollama-local",
"baseUrl": "http://127.0.0.1:11434/v1",
"models": [
{
"contextWindow": 131072,
"cost": {
"cacheRead": 0,
"cacheWrite": 0,
"input": 0,
"output": 0
},
"id": "glm-4.7-flash:latest",
"input": ["text"],
"maxTokens": 16384,
"name": "glm-4.7-flash:latest",
"reasoning": false
}
]
}
}
},
...
}
总结与展望
采用本地大模型部署方案,正逐渐成为众多企业与开发者优化 AI 应用架构的优先选择。
其核心优势在于:在当今数据资产价值凸显的时代,数据安全与隐私保护已成为关键考量。本地化部署不仅能确保敏感业务数据完全留存于私有环境,杜绝泄露风险,更能彻底免除对云端 Token 消耗成本与调用限额的持续担忧,实现真正意义上的自主可控。
希望本篇教程能帮助你一劳永逸地解决 OpenClaw 使用中的 Token 焦虑问题,顺利迈向本地化 AI 应用开发。
如果你是 OpenClaw 的新用户,以下入门资料或许能帮助你快速上手:
使用 Docker 容器部署 OpenClaw 环境
开发你的第一个 OpenClaw 自定义 Skill
快讯:NVIDIA 为 ClawdBot 项目提供免费算力支持

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

龙虾盒子数据不出盒AI能力不打折云端端侧安全新选择
▲图片由AI生成 当AI Agent框架OpenClaw(昵称“龙虾”)的热潮席卷而来,一个起初被忽视的问题也在同步放大:安全风险。 想象这样一个场景:你刚输入的一段公司财务数据,可能在毫无感知的情况下被上传到云端,导致商业机密泄露。在云端“养龙虾”固然便利,但背后却是隐私数据近乎“裸奔”的现实。

Claude用户因不当使用遭Anthropic官方警告
这张在程序员社群中广泛流传的梗图,相信许多开发者都曾会心一笑。 近期,一个名为「badclaude」的趣味开源项目,将图中抽象的“数字鞭子”变成了可交互的现实。根据项目介绍,其创作初衷是“当Claude Code运行速度过慢时,通过虚拟鞭策将其拉回正轨”。 用户安装后,仅需点击系统托盘图标即可唤出一

Anthropic封禁OpenClaw创始人 24天内三次违规遭处理
一封来自Anthropic安全团队的邮件,让整个AI开发者社区炸开了锅。邮件抬头写着“你好”,内容却冰冷直接:因“可疑信号”,您的账户已被暂停使用。收件人是Peter Steinberger,那个在GitHub上拥有24 7万颗星的开源项目OpenClaw的创始人。 事件在社交平台X上迅速发酵,几小

中国AI独角兽推出龙虾养殖智能方案,助力养殖户高效增产
在OpenClaw应用热潮席卷的当下,一个核心的安全隐患正日益凸显:云端隐私数据保护的缺位。想象一下,你刚向模型输入了一段公司的财务数据,下一秒这条敏感信息可能就已经在云端“裸奔”。这种担忧,正驱使着越来越多的用户将目光投向本地终端,期待能“安全养虾”。然而,端侧设备的有限算力,往往难以高效支撑复杂

开源代码副脑仅需400美元硅谷天价模型面临挑战
在AI编程领域,一个有趣的现象正在发生:真正改写行业价格体系的,往往不是更尖端的技术,而是更经济的复制路径。 长期以来,最强大的编程智能体被少数科技巨头以封闭、昂贵且难以定制的方式“圈养”着,构成了坚实的竞争壁垒。然而,这道“护城河”最近被开源力量用成本这把锋利的刀,切开了一道口子。艾伦人工智能研究








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
