




Token计算:下一个十年的成本战争

Token经济,正在成为AI行业近期最热的关键词之一
当OpenClaw(俗称“龙虾”)引发全民关注,各大厂商纷纷涌入“龙虾潮”之际,一个显著的趋势浮出水面:Token的消耗量正呈现指数级增长。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
在开发者社区和社交媒体上,各类对比表格频繁出现,人们热衷于计算不同模型的Token消耗、输出质量差异,以及最终折算出的“每千Token成本”究竟谁更具优势。
然而,若试图用Token来核算一笔清晰的经济账,便会迅速发现,事情已远非那么简单。
近日,一位从事财务工作的朋友提出了一个典型问题:他们公司的AI智能体每日调用量达数十万次,一个月下来究竟需要多少成本?
这听起来像是一个基础问题,似乎用“Token单价×调用次数”即可轻松得出答案。
但在实际操作中,翻开Anthropic的定价页面进行粗略估算时,却立即遇到了难题。
Claude Managed Agents的会话运行时长按“每会话·小时”独立计费,缓存写入和缓存命中又各自适用不同的计价系数,这些费用项目与Token根本不在同一个计量维度上。
于是,在逐一查阅了几家主流平台的定价页面后,我们发现这件事远非一道“清晰的算术题”。
例如,OpenAI的定价页面更像一张资源总览表。除了Token费用,联网搜索按千次调用收费,容器按会话时长收费,文件检索存储按GB/天收费,跨区域处理还需额外叠加10%的费用。
Google Gemini的收费项目相对收敛一些,但搜索增强和上下文缓存也被单独列为独立的计价项。
Anthropic则采用三档缓存系数,再叠加会话运行时长的计费,构成了另一套体系。三家巨头的计费方式已无法用同一套公式进行核算。
如果再向上一层观察,商品边界本身甚至已脱离了“模型”范畴。Salesforce通过Flex Credits将动作配额纳入价格体系,Intercom则干脆绕过Token,直接按结果收费——每个“有效解决”收费0.99美元,并对此有明确的书面定义。
一番探究后,唯一可以确定的是:各家厂商所售卖的,早已不是同一种商品。
2026年1月,OpenAI首席财务官Sarah Friar在官网发表的《A business that scales with the value of intelligence》一文中,明确指出了其三条商业化路径:订阅制、广告支撑的免费层、按用量计费的API。她还补充道,未来将扩展到授权许可、IP协议和按结果定价。即便是平台方自身,也不再使用单一的“按用量计费”来描述其商业模式。
过去,在比较各大模型时,行业常讨论“谁的Token更便宜”,这默认了一个前提:行业已存在一个被广泛接受的统一计量单位,大家比拼的只是价格。
但到了2026年4月,现实情况是——Token早已不是AI账单中唯一的计费单位。AI商品正从单一计量项走向多单位并存,企业的预算语言也随之被彻底改写。
因此,本文旨在探讨的不仅是Token本身,更是梳理一条完整的变化路径:从收费方式的演变,到成本结构的分化,再到预算体系的调整,审视Token经济如何被重新定义。
AI收费,告别“单一Token时代”
如果今天仍有人只讨论“哪个模型每百万Token成本更高”,那么他所看到的仅仅是底层供给的一部分。
真实情况是,企业当前购买的是一段被组织过的智能劳动,原始模型只是其中的一小部分。
它可能同时包含模型推理、联网搜索、信息检索、缓存服务、上下文驻留、运行时、容器资源、团队席位、动作配额,乃至一个被明确定义的“交付成果”。AI经济正在经历的,并非一场简单的价格战,而是计费对象的多元化扩散。
这里最容易出现的误解,是将“计费单位变多”等同于“底层模型已不重要”。
但事实恰恰相反:模型仍是底层最核心的供给要素,只是它不再是企业成本解释框架中的唯一变量。
一旦系统进入真实工作流,采购者与运营者就必须同时处理搜索增强、批量调用、区域路由、运行时长与席位切换,这些项目在同一张对账单上争夺预算。于是,账单不再是一列Token的简单累加,而是一组相互叠加的价格对象。
AI底层大概率会像电力一样,最终演变为公用事业:廉价、可计量、不可或缺,但也不再是价值最终停留的层面。
经济史上反复出现的模式是:电力带来的生产率跃升,远比“有电就更快”复杂。让美国制造业真正起飞的,是工厂围绕电力重写了生产组织方式,而非电力本身变得廉价。
AI成本,从统一定价走向按任务分化
过去习惯用“每百万Token多少钱”来理解AI成本,但今天这个锚点已然失效——账单的主角是谁,完全取决于你在运行何种类型的任务。
先看一个轻量、高频、以检索为主的企业问答任务。
以Google Gemini 2.5 Flash-Lite标准档估算,5000输入Token加1000输出Token,成本约0.0009美元;若同一次调用附带一次搜索增强,超出每日免费额度后,单次增强价格约为0.035美元,这几乎是Token成本的四十倍。
在这类工作负载里,主导账单的是搜索或增强这类外层能力,模型推理本身反而退居次要位置。
然而,如果换成更强的前沿模型,图景就完全不同。
以OpenAI GPT-5.4标准档为例,同样的5000输入加1000输出Token约0.0275美元;一次联网搜索的工具调用费为0.01美元(搜索内容Token另按模型费率计);一次1GB容器会话为0.03美元。此时,模型成本仍与工具调用处于同一数量级,在许多推理密集任务中甚至占据大头。
再看Anthropic官方给出的Claude Managed Agents示例:一个一小时的Opus 4.6编码会话,5万输入加1.5万输出的Token成本是0.625美元,而会话运行时长费用仅0.08美元。运行时虽然进入了商品列表,但远未“压倒”模型成本。
三个例子合起来指向同一件事:成本的大头在哪里,取决于你让AI执行何种性质的工作。
通俗地理解,你让AI查询资料,钱主要花在搜索上;让它进行深度思考,钱主要花在模型上;让它持续在后台运行,“开机时长”本身就成为一笔成本。因此,根本不存在一张能通用的“AI单位成本”表。AI经济的演变,不能被简化为“工具吃掉模型”或“模型吞噬一切”这种非黑即白的叙事。
更准确的说法是:买方必须开始依据不同任务形态去理解总成本,不再假定存在一个统一的成本锚点。
这件事的后果,比“算术变复杂”要深远得多。一旦计费单位发生裂变,原本仅用“每百万Token多少钱”就能对账的人员,现在必须同时理解搜索成本、缓存命中率、运行时长度与区域溢价。
预算口径从一维变成多维,采购的比较基准也随之改写——从“谁的Token更便宜”,变成“在我的特定工作负载下,谁的综合成本更低”。计费单位的裂变,正在倒逼企业重写自身理解AI支出的方式。
中国市场提供了一个“反向参照”。例如,2024年国内大模型价格战异常激烈,部分厂商降价幅度超过97%,推理毛利一度跌至负数,但整场竞争的叙事始终只围绕一件事:谁的百万Token更便宜。
运行时、搜索增强、按结果付费这些在美国定价页面上已经独立成行的维度,目前在中国仍处于早期阶段。当所有玩家都挤在同一个计量单位上竞争,负毛利就不是意外,而是结构性的必然终点。
价格页先变,企业的预算体系也需跟上
计费单位的变化,最先体现在价格页上,最后才会反映到平台的营收报表中。而夹在中间、最先被迫进行调整的,是企业自身的预算表。
到目前为止,尚无可靠的公开数据能证明OpenAI、Google或Anthropic的工具、存储、运行时营收已经超过模型或Token营收。
因此,一家公司在价格页上增加了多少新收费项,并不代表他们的收入真的主要来自这些新项目,这两者不能划等号,仍需等待进一步的数据验证。
当前真正可以确认的是:卖方的定价语言已经率先改变,买方的预算口径无法继续停留在Token这一单一列上。
这其中的道理不言而喻:当官方价格页已将工具调用、会话运行时长、交付结果各自独立定价,企业的对账单就不可能再维持为一列Token,否则卖方出具的账单将与买方的内部核算无法对应。
Token不再是唯一的主角,它更像是底层的一种计量单位。真正影响账单总额的,是推理、搜索、缓存、运行时、席位、动作、结果这些叠加在一起的成本。
文章开头Sarah Friar那句顺口提到的“未来还会扩展到授权、IP协议、按结果定价”,其实就是这件事在OpenAI自身视角下的翻译——他们比任何人都更清楚,自己正在售卖的不只是Token。
一旦买方的预算框架随之调整,一些原本被忽视的要素会重新浮出水面。例如:
模型路由不再只是“帮你挑选哪个模型最合适”,而是在悄然决定整张账单的结构——选错一层,预算的重心就会整体偏移;
Salesforce的Flex Credits售卖的并非某一次具体调用,而是一份可以在不同动作、场景、团队之间自由调拨的“使用权”;
按结果定价的真正吸引力,在于它将预算直接绑定在“交付成果”上。企业首次可以用结果,而非过程,来与供应商进行对账。
新的计费单位或许尚未改写卖方的收入结构,但它们已经在改写企业内部看待AI支出的方式。而一旦组织开始用新的语言理解自身的AI成本,预算最终流向哪一层、沉淀在哪一层,就不再是一张简单的模型性能排行榜所能决定的事了。
当计费单位裂变,价值开始分层
将视野再拉远一些,如果计费单位已不只是Token,那么“钱到底会沉淀在哪一层”这件事,就需要分层审视。
一个有效的梳理方式,是将整个AI经济视为一套五层结算栈。将其看作一张正在成型的产业结构图,本系列接下来的文章会沿着这个框架逐层展开:
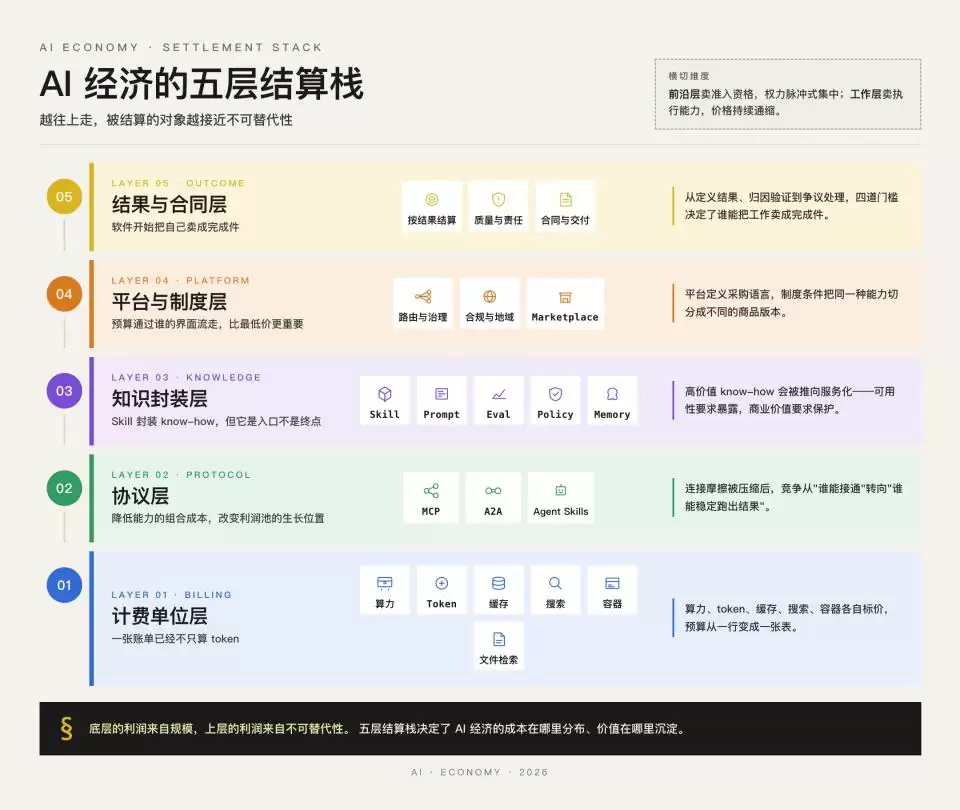
• 第一层 · 公用事业层:算力、Token、缓存、搜索、容器、文件检索,可计量、可路由的“认知吞吐量”
• 第二层 · 协议与能力层:MCP、A2A、Agent Skills 这类让模型、工具、数据源和智能体互操作的共同接口
• 第三层 · 知识封装层:技能、提示词、评估、策略、记忆,把行业知识序列化下来
• 第四层 · 执行交付层:被托管、可观测、受监控的“数字劳动力”,市场正将智能体从“下载”模式转变为“调用”服务
• 第五层 · 结果与责任层:Intercom的“每次有效解决0.99美元”是最明确的公开信号之一,“被完成的工作”开始成为合同化的结算对象
如果把这五层放在一起观察,会出现一个很清晰的分布规律:越靠下层,越容易被单位化和路由化;越靠上层,则越深地嵌入具体上下文、验收标准和责任划分。
对应的商业模式也随之分化——底层依赖规模和效率,买方按成本比价;上层依赖不可替代性,买方按结果付费。这两种模式都可以成立,但它们的“价格锚点”完全不同。前者锚定投入成本,后者锚定创造的价值。
Token经济,不再只关于Token
总之,今天再谈Token经济学,已不再是简单的“Token单价走势”,更值得研究的是:Token作为底层计量颗粒,正在如何与搜索、缓存、运行时、席位、结果这些更高层的单位一起,重写企业对AI的预算语言。换言之:Token依然存在,但它已不能单独解释这门生意的全貌。
当然,这并不意味着Token不再重要。
底层资源层依然可能是未来最大的利润池,甚至可能出现高度集中的赢家。但到了2026年,如果想理解AI商业化的整体变化,只盯着Token,已经无法看清全局。核心问题从“Token多便宜”,变成了:整张账单是如何被构成的。
那接下来应该关注什么?比预测具体时间表更有意义的,是观察一些正在出现的信号:
第一,企业合同中,是否开始出现服务等级协议、数据驻留要求、缓存策略、责任边界等条款,而不再只谈Token单价。这意味着,买卖双方开始围绕“系统”和“责任”进行对齐,而非单一资源。
第二,市场上,是否开始出现附带评估卡的智能体服务。亦即,“结果是否可被评估”,开始成为商品定义的一部分。
第三,是否出现第三方的审计、认证和争议处理服务。这是“按结果结算”走向正式合同化之前,必须补上的最后一块基础设施。
到2027年底,如果这三条信号中有两条以上成为普遍现实,那么可以基本确认一件事:结算对象正在从Token向更高层级迁移。
Anthropic在4月7日以“邀请制”的方式发布了Mythos(预览版),而与此同时,工作层模型的价格仍在持续下降。
一边是前沿能力不断集中,一边是工作层持续商品化。
成本在下沉,价值在上移。
这两条看似相反的变化趋势,其实指向同一个方向:AI的价格体系正在走向分层,而价值也在随之重新分配。
当Token不再是唯一的计量单位,当账单被拆分成多种成本结构,企业最终为哪一层买单,就将决定价值最终沉淀在哪一层。
至于这种“成本下沉、价值上移”的结构,是如何在同一个体系中同时成立并演进的,我们将在后续的解读中再逐一展开分析。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Devin Review - AI代码审查工具,自动检查和标记代码问题
Devin Review是什么 提起代码审查,你是否也遇到过这样的困扰:面对一个包含海量文件变更的GitHub拉取请求(PR),想快速理清头绪却不知从何下手?传统的代码差异视图,有时反倒让人更费解。 Devin Review正是为了解决这个痛点而生的。它不是另一个单纯的代码查看器,而是一个智能审查伙

Being-H0.5 - 卢宗青团队开源的通用机器人模型
Being-H0 5是什么 通用机器人如何跨越不同硬件的鸿沟,实现策略的自由迁移?卢宗青团队的Being-H0 5模型,正试图给出一个扎实的答案。这个模型的核心思路,是通过人类先验知识和对齐统一的动作,来解决机器人在不同形态硬件间的策略迁移难题。背后的关键,是一个大规模跨形态操控数据集UniHand

VibeVoice-ASR - 微软开源的长音频语音识别模型
VibeVoice-ASR是什么 当你面对一段长达一小时的会议录音或讲座视频,想要把它转化为文字时,传统的语音识别工具常常会让人头疼——分段处理导致上下文断裂,说话人切换弄得一团糟。这时候,你就需要了解一下微软开源的VibeVoice-ASR了。 简单来说,这是一款为“长音频”而生的先进语音识别模型

AgentCPM-Report - 清华联合面壁智能等开源的写作智能体
AgentCPM-Report是什么 如果在深度调研和报告生成这事儿上,你既想要媲美顶级闭源系统的能力,又对数据安全和隐私有着近乎苛刻的要求,那么有个新工具值得你关注——AgentCPM-Report。这是由清华大学自然语言处理实验室、中国人民大学、面壁智能与 OpenBMB 开源社区联手打造的一款

Chroma 1.0 - FlashLabs开源的实时端到端语音对话模型
Chroma 1 0是什么 说来有意思,最近语音AI领域的热闹,很大程度上是“延迟”和“音质”这两个老问题给逼出来的。用户要的不只是能对话,还得是即时、自然、带有“人味儿”的互动。这不,FlashLabs带来的开源模型Chroma 1 0,就是冲着这个目标来的。 简单说,它是一个实时端到端的语音对话








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
