




Redis BGSAVE 之后内存暴涨?不是 bug,是 Linux 在保护你的数据

一、从一个问题开始:fork() 复制了什么? 想象这样一个场景:一个进程已经加载了10GB的数据到内存中,然后它调用了fork()。如果这个系统调用需要完整复制这10GB数据,那么整个服务恐怕会卡顿数秒,这在像Redis这样的高性能系统中是完全不可接受的。 但现实是,fork()几乎在瞬间就完成了
一、从一个问题开始:fork() 复制了什么?
想象这样一个场景:一个进程已经加载了10GB的数据到内存中,然后它调用了fork()。如果这个系统调用需要完整复制这10GB数据,那么整个服务恐怕会卡顿数秒,这在像Redis这样的高性能系统中是完全不可接受的。
但现实是,fork()几乎在瞬间就完成了。秘密何在?答案就是写时复制(Copy-On-Write,COW)。
二、COW 的核心思想:懒得复制就先共享
写时复制的核心理念可以用一句话概括:在真正需要修改数据之前,绝不浪费资源进行复制。
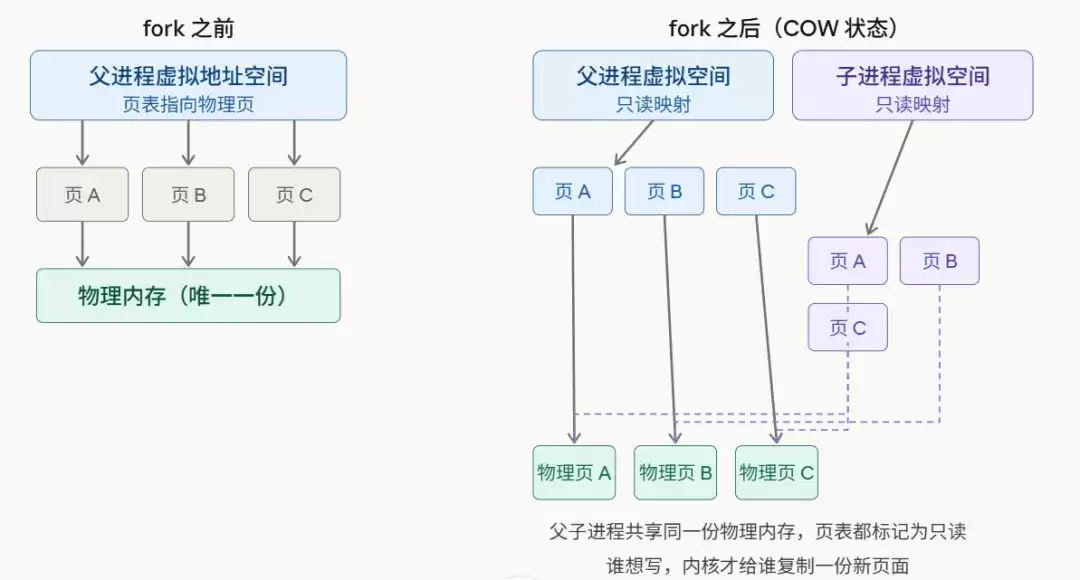
具体来说,当fork()调用发生时,内核并不会立即复制父进程的整个内存空间。相反,它只做几件非常轻量级的事情:复制父进程的页表(这只是一套指向物理内存地址的指针列表,体积很小),然后将父子进程所有内存页的权限都标记为“只读”。至此,调用便返回了。那10GB的数据,一个字节都还没被复制。
此时,父子进程共享着同一份物理内存。只有当其中一方(通常是继续处理写请求的父进程)试图修改某个内存页时,CPU才会检测到这次“非法”的写操作,并触发一个缺页中断。内核此时才介入,为试图写入的进程复制出那个特定的内存页(通常是4KB大小),并赋予其可写权限。此后,父子进程对这个页的修改就互不影响了。
整个过程可以概括为:先共享,写时才复制。
三、内核是怎么实现 COW 的?
这套机制的实现,离不开CPU硬件的支持,其核心在于内存页表项中的一个特殊标志位——写保护位。
在fork()之后,内核会将父子进程所有页表项中的写保护位置位。这意味着,任何试图写入这些内存页的操作都会被CPU拦截。
接下来会发生什么,取决于进程的行为:
情况一:子进程只读不写。 这正是Redis执行BGSA VE时子进程的状态。子进程只需读取fork()那一刻的内存快照,并将其序列化写入磁盘。由于全程没有写操作,自然不会触发COW,父子进程的内存完全共享,额外内存消耗几乎为零。
情况二:父进程处理写请求。 当父进程(如Redis主进程)需要修改某个Key对应的值时,它试图写入对应的内存页。CPU检测到写保护位被设置,立刻触发缺页中断,将控制权交还给内核。内核的处理流程如下图所示:
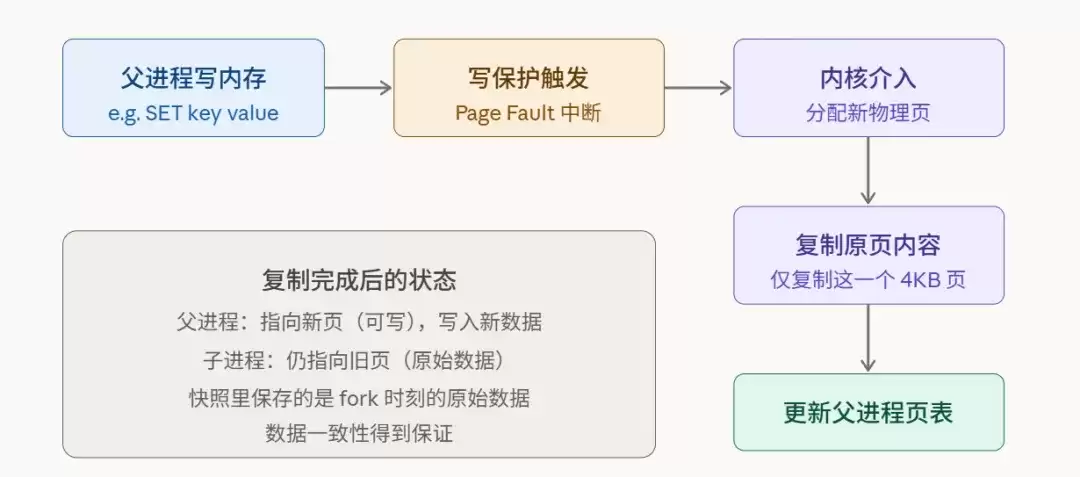
这里的关键在于,COW的粒度是内存页(通常4KB),而非整个进程地址空间。每次写操作,最多只复制一个被修改的页面。
四、Redis BGSA VE:COW 的教科书级应用
现在,让我们回到最初那个令人困惑的问题。Redis的BGSA VE命令背后,正是COW机制的完美演绎。
当你在客户端输入BGSA VE后,Redis主进程会调用fork(),瞬间创建一个子进程。由于COW,此时并没有发生大规模的内存拷贝。
此后,父子进程分道扬镳:
- 子进程:它的使命是生成RDB快照。它看到并遍历的,是
fork()发生那一瞬间的、凝固的内存数据视图。无论父进程之后如何修改,子进程眼中的“世界”保持不变。完成序列化写入.rdb文件后,子进程便退出。 - 父进程:继续正常服务,处理所有客户端的读写请求。每当它需要修改一个内存页(例如执行
SET命令)时,就会触发一次COW,内核会为该页创建一个副本供父进程修改。
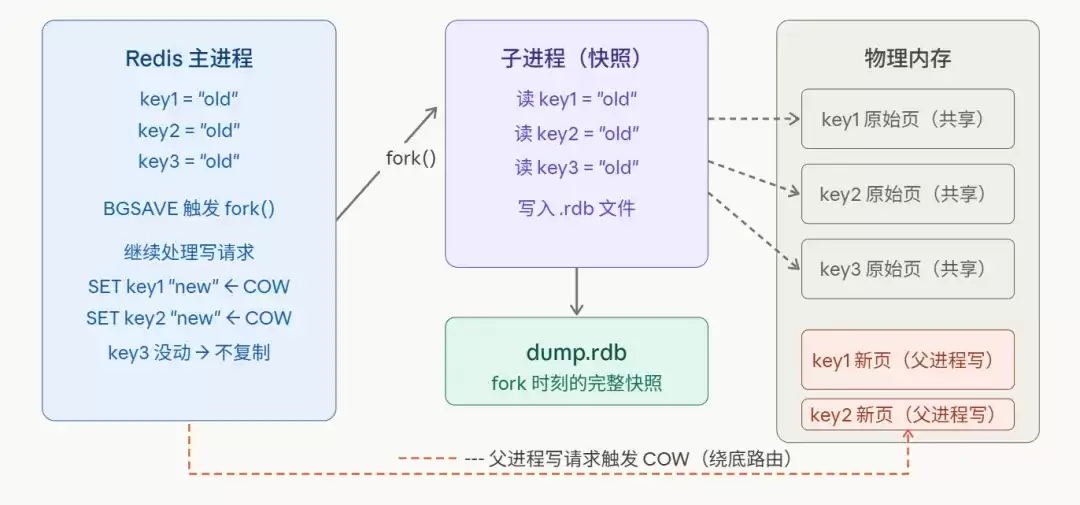
正是依靠COW,Redis才能在不停服的情况下,生成一个时间点一致的数据快照,这比通过加锁来实现要优雅和高效得多。
五、内存为什么会暴涨?算笔账就明白了
那么,BGSA VE期间内存暴涨的谜底就此揭晓:内存的增量,几乎等于快照期间被父进程修改过的数据总量。
假设你的Redis实例持有10GB数据。在BGSA VE子进程工作的几十秒或几分钟内,如果业务写请求非常频繁,尤其是涉及大量不同的Key更新,那么父进程可能会触发大量的COW操作。每个被修改的4KB页面都会被复制一份。
在极端情况下,如果快照期间所有数据页都被修改了一遍,那么内存使用量理论上确实可能接近翻倍。这并非程序漏洞,而是COW机制为了换取fork()的速度和快照一致性,所必须付出的、可预期的内存代价。
六、生产环境怎么处理这个问题?
理解了原理,应对策略就清晰了。核心思路是:控制写入,预留缓冲。
1. 预留充足的内存缓冲。 这是一个黄金法则:切勿让Redis实例的使用内存接近物理内存上限。通常建议,Redis最大内存设置为物理内存的45%-65%,为COW导致的内存膨胀留出足够空间。例如,在一台16GB的机器上,将maxmemory设置为7-10GB是相对安全的。
2. 调整持久化相关配置。 可以设置no-appendfsync-on-rewrite yes。这个配置项的作用是,当Redis正在进行RDB快照或AOF重写时,暂停AOF文件的同步操作(fsync)。这能降低磁盘I/O压力,从而间接减少主进程因等待I/O而产生的阻塞时间,使得写请求处理更平滑,有时能缓解短期内密集触发COW的情况。
3. 错峰执行持久化。 合理配置sa ve指令,避免在业务高峰期自动触发BGSA VE。例如,可以设置在访问量较低的夜间进行持久化操作。写操作越少,触发的COW就越少,内存波动自然越小。
# 示例:避免在短时间内因少量键改变就触发持久化
sa ve 900 1 # 15分钟内至少1个键改变
sa ve 300 10 # 5分钟内至少10个键改变
sa ve 60 10000 # 1分钟内至少10000个键改变
4. 考虑升级版本。 Redis 7.0及后续版本在多线程I/O、内存管理等方面进行了诸多优化,在某些场景下可以更高效地处理内存和持久化任务,升级也是值得考虑的选项。
七、COW 不只是 Redis 的事
COW是Linux内核中一项基础且重要的优化,其应用远不止于Redis。
1. Shell命令执行。 当你在终端输入ls -la时,Shell会先fork()出一个子进程,然后通过exec()将子进程的内存映像替换为ls程序的。COW保证了fork()过程极其快速,几乎无内存拷贝开销。
2. 高级语言的多进程模型。 例如Python的multiprocessing模块,在Linux系统下默认使用fork()来创建工作者进程。这些子进程可以共享主进程初始化好的大量只读数据(如代码、配置),得益于COW,内存利用率得以提升。
from multiprocessing import Pool
# Pool中的worker进程通过fork创建,共享主进程的只读数据
3. Docker 的镜像层
Docker容器技术的镜像分层存储,其思想精髓与COW同源。多个容器可以共享同一个只读的基础镜像层,每个容器只在最上层的可写层记录自己的修改。这极大地节省了存储空间,并加速了容器的创建与部署。
八、一道值得思考的题目
基于以上理解,这里有一个进阶思考题:如果Redis同时开启了AOF持久化,并且在执行BGSA VE(RDB快照)的同时,也触发了AOF重写(BGREWRITEAOF),内存使用会如何变化?
答案是:COW的代价会叠加。 此时将存在两个子进程(RDB子进程和AOF重写子进程),它们都与父进程共享内存。如果父进程在此期间有大量写操作,那么每修改一个内存页,理论上可能需要为该页创建两个副本(分别供两个子进程读取原始数据),这可能导致内存消耗增长到原来的两倍甚至更多。因此,Redis默认策略会阻止两者同时进行,通常是在BGSA VE期间推迟BGREWRITEAOF,待RDB完成后再开始AOF重写。
九、面试高频题精析
Q:为什么 fork() 之后子进程的内存修改不影响父进程?
A:因为COW机制。修改发生时,内核会为修改者复制出一个独立的物理页副本。此后父子进程各自修改自己的副本,互不干扰。
Q:Redis BGSA VE 为什么不会阻塞主进程?
A:BGSA VE通过fork()创建子进程来执行耗时的磁盘I/O操作。fork()本身借助COW可以瞬间完成。此后,持久化任务在子进程中独立运行,父进程(主进程)继续无阻塞地处理客户端请求。
Q:fork() 之后父子进程哪个先执行?
A:从Linux 3.4内核开始,为了优化COW性能,默认倾向于让子进程先执行。因为子进程通常很快会调用exec()来加载新程序,或者像Redis BGSA VE子进程那样只读数据,让其先运行可以减少它修改内存页的可能性,从而降低COW触发次数。
Q:COW 会有什么性能开销?
A:开销主要来自两方面:一是触发缺页中断(Page Fault)本身的开销,属于CPU上下文切换;二是复制内存页所需的内存分配和数据拷贝开销。在写操作极其密集的场景下,这些开销会累积,可能对性能产生可见影响。这也正是高负载Redis实例需要预留更多内存的原因之一。
十、写在最后
让我们再梳理一下整个链条:fork()的瞬间完成,得益于父子进程初始时对物理内存的共享;父进程后续的写操作,会按需触发内存页的复制;而内存的额外消耗,则与快照期间的写操作量线性相关。
所以,下次再看到Redis在BGSA VE期间内存上涨,不必惊慌。这并非异常,而是Linux内核历经数十年沉淀下来的、一种精妙的空间换时间工程智慧。从Shell的快速命令执行,到Redis的无阻塞持久化,再到Docker的高效容器,COW机制都在其中扮演着至关重要的角色。
透彻理解COW,无疑是打通操作系统内存管理、进程模型与现代应用软件设计之间任督二脉的关键一步。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

ZCode被外媒盯上,中国模型公司开始抢AI编程入口
编辑 | 王凤枝ZCode最近突然被海外媒体 "发现 "了。7月2日,VentureBeat把ZCode写成Z ai进入AI编程工具市场的一步;Business Insider则抓住了更容易传播的一点:这是一款价格更低的AI编程工具。这个框架容易带出两个误会:ZCode像是刚出现的新产品,也像是又一个 "

理想i6上半年交付破12万辆 成中大型纯电SUV销量冠军
理想i6上半年交付超12万辆,夺得中大型纯电SUV销量冠军。该车起售价24 98万元,车长近5米轴距3米,标配全铝悬架、双腔空气悬架及ADMax智驾系统,CLTC最高续航720公里,支持5C超快充。

年Arm架构将占头部云服务商半数算力
2025年头部超大规模云服务商算力中近50%基于Arm架构。全球十大云商积极开发Arm芯片,能效提升高达60%。NVIDIA等定制AI芯片采用ArmNeoverse平台,软件生态加速迁移。

vivo Arm联合实验室成立 赋能芯片技术创新
vivo与Arm联合实验室正式揭牌,双方基于真实应用场景分析性能与功耗瓶颈,共同优化调校方案。部分关键成果将应用于十月发布的vivoX200系列旗舰手机,旨在回归用户需求,提升芯片技术体验。

新飞猫U9随身WiFi限时低价抢先体验
飞猫U9随身WiFi采用WiFi6技术,网络速度提升25%,支持低延迟与高稳定。一键可控WiFi开关提升安全性并降低功耗。三网融合自动切换最优网络,36V防浪涌保障车载稳定。设备仅32克,支持10台设备连接,散热设计持久耐用。








- 热门数据榜



 相关攻略
相关攻略
 2026-07-14 17:28
2026-07-14 13:55
2026-07-14 13:55
2026-07-14 13:54
2026-07-14 13:54
2026-07-14 13:54
2026-07-14 13:54
2026-07-14 13:54
热门教程
2026-07-14 17:28
2026-07-14 13:55
2026-07-14 13:55
2026-07-14 13:54
2026-07-14 13:54
2026-07-14 13:54
2026-07-14 13:54
2026-07-14 13:54
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
















