




一份专利,暴露OpenAI自研芯片

2026年4月初,OpenAI的一项名为《通过嵌入式逻辑桥实现高带宽显存芯粒、I/O芯粒与计算芯粒的非邻接互联》专利正式公开。
这份专利文件,详细描绘了一种全新的AI芯片封装方案。其核心在于,通过一种名为“嵌入式逻辑桥”的技术,将多个HBM存储芯片和计算芯片连接在一起,而且,这种连接可以突破传统上必须“紧挨着”的距离限制。换句话说,它能让更多的芯片在同一个封装内协同工作。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
这就引出了一个有趣的问题:众所周知,OpenAI是靠大模型软件起家的,它为何要涉足如此硬核的芯片封装领域?这张专利图纸,在其宏大的硬件版图里,究竟扮演着什么角色?
物理约束,卡住整个行业
要理解这项专利的价值,得先从它要解决的那个行业级难题说起。AI芯片,尤其是运行大模型的芯片,对内存的渴求远超传统计算。在推理时,海量的模型参数和中间计算结果都需要被快速存取,高带宽内存(HBM)正是为此而生——它通过将多层DRAM芯片垂直堆叠,实现了惊人的数据吞吐能力,已成为高端GPU和AI翻跟斗的标配。
然而,HBM的集成有一道近乎“物理法则”般的硬约束。根据行业标准,HBM芯片必须与计算芯片紧密相邻,两者信号引脚之间的互联距离不能超过6毫米。这条规定并非故意设限,而是为了保障高速信号的完整性。一旦超过这个距离,信号衰减就会导致数据出错,性能和可靠性都会大打折扣。
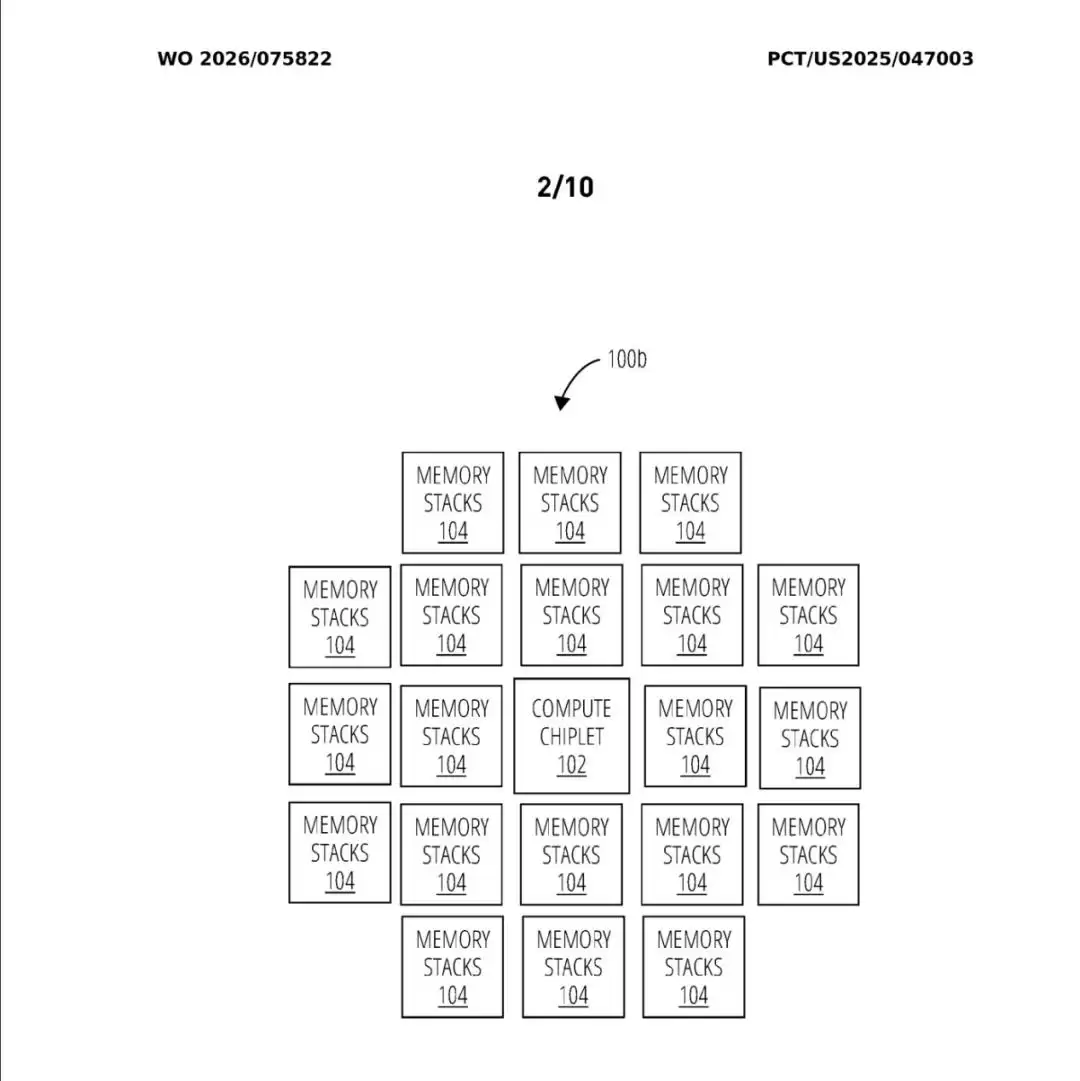
6毫米,听起来似乎不短,但在芯片封装的微观世界里,这条红线却显得格外局促。一颗HBM芯片本身的宽度就超过5毫米,而计算芯片的周长通常也就30毫米左右。在这种几何限制下,传统封装技术最多只能在一颗计算芯片周围“挤下”四组HBM。想放第五组?对不起,没地方了。
四组HBM的容量,对于早期的AI模型或许够用。但如今,面对参数规模动辄万亿级别的大模型,推理所需的内存容量早已今非昔比。这道6毫米的物理红线,就这样悄然变成了制约AI芯片算力提升的一个核心瓶颈。
嵌入式逻辑桥:突破限制的关键
OpenAI专利给出的方案,核心在于引入了一个主动的“信号中继站”——嵌入式逻辑桥。
这到底是什么?简单来说,它是一块嵌入在封装基板内部的小型硅片。但关键不在于硅片本身,而在于它内部集成了有源电路,比如信号放大器、重驱动器和物理层控制器。这与传统封装中只负责导电的被动中介层有本质区别。正因为有了这些主动元件,高速信号得以被接收、放大并重新驱动,从而将可靠传输的距离从6毫米延伸至16毫米甚至更远。
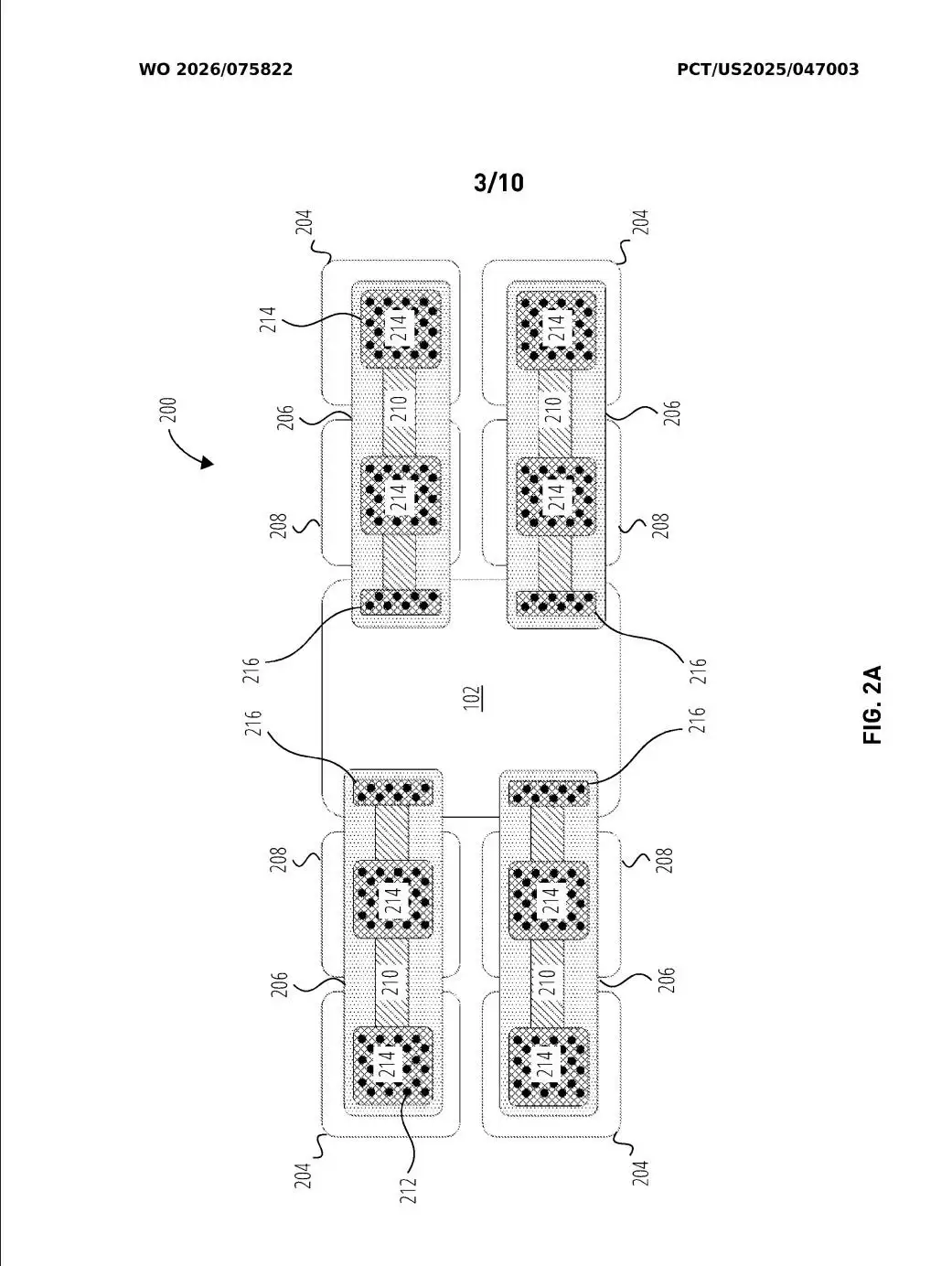
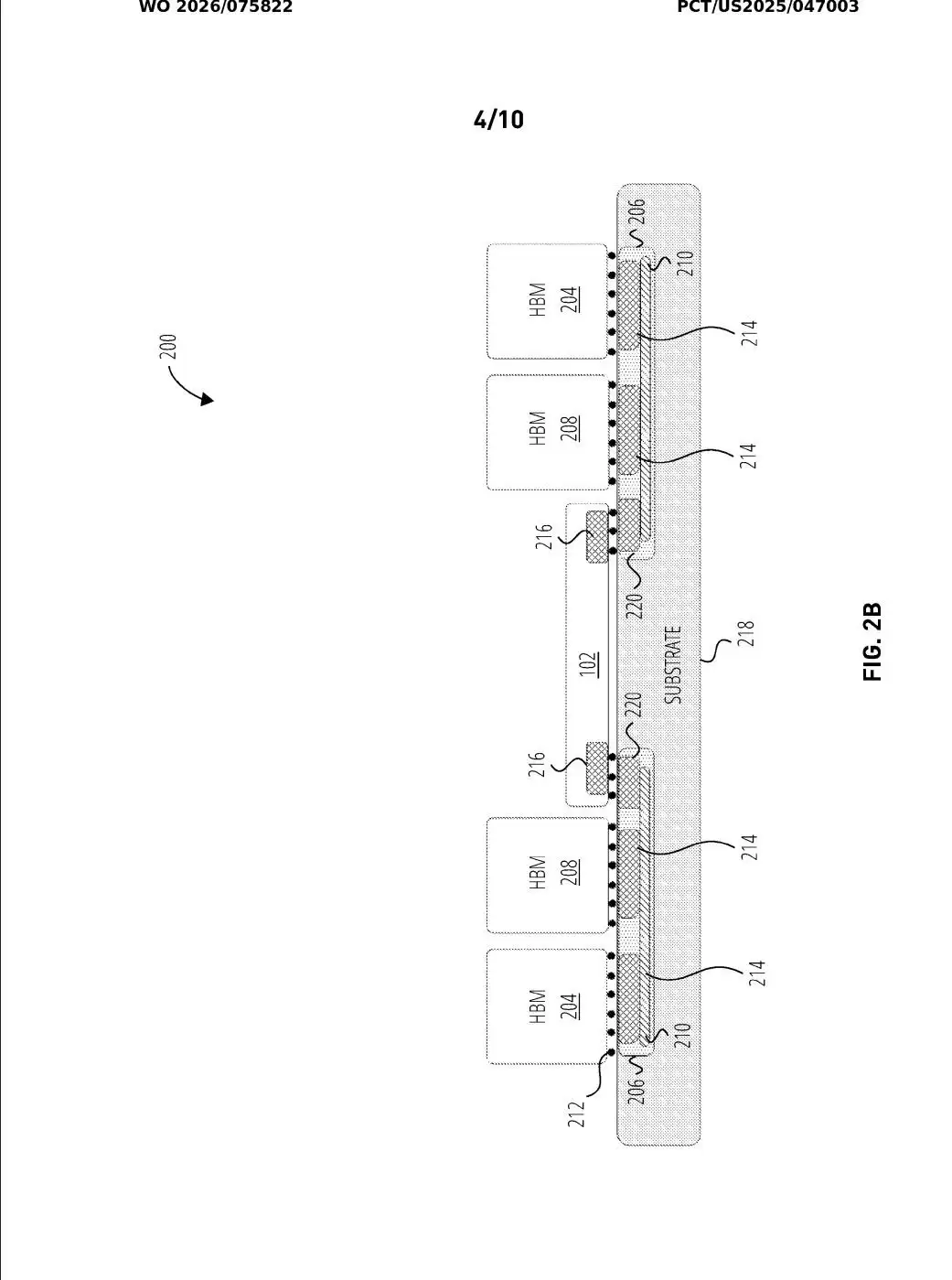
这个改变,堪称“四两拨千斤”。专利中的示意图展示了一种激进的设计:一颗计算芯片周围,竟然连接了多达20组HBM堆叠,这是传统上限的五倍。所有这些芯片之间的通信,都通过嵌入式逻辑桥完成,并且遵循通用的UCIe芯粒互联标准,保证了方案的开放性和兼容性。
嵌入式逻辑桥的作用还不仅于此。它甚至可以接管一部分原本由计算芯片负责的工作,比如直接充当HBM堆叠的控制器。这样一来,计算芯片就能从繁琐的内存管理任务中解放出来,更专注于执行核心的推理计算。专利中特别强调,其裸片接口符合UCIe标准,这无疑是为未来集成第三方芯片生态留下了空间。
从架构视角看,这是一种“让封装变聪明”的思路。封装层不再只是一个被动的连接器和固定支架,而是进化成为一个具备一定信号处理与路由能力的智能中间层,从而从根本上打破了纯物理距离的束缚。
先行者英特尔
细看OpenAI专利的描述,其技术思路与英特尔已耕耘多年的EMIB(嵌入式多芯片互联桥)技术可谓异曲同工。
英特尔的EMIB技术自2017年便已投入大规模量产。其核心思想同样是在有机基板中嵌入微型的硅桥,在需要高速互联的芯片局部区域提供高密度连接,而不是铺设一个覆盖整个封装底部的大型硅中介层。相比后者,EMIB更薄、成本更低,且不受光刻机版图尺寸的限制,设计灵活性显著提升。
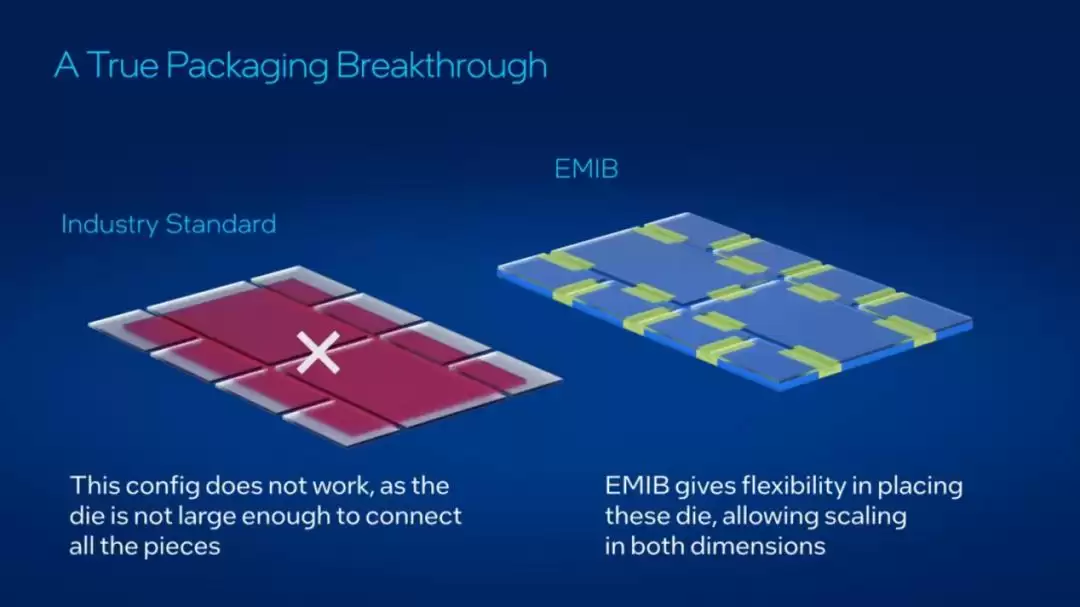
英特尔并未止步,后续又推出了增强版的EMIB-T(EMIB-TSV)。通过在桥接芯片中引入硅通孔,进一步优化了电源传输,以更好地支持下一代HBM4等高速存储芯片的集成。EMIB-T能够支持超过120×180毫米的大尺寸封装,以及超过12颗大尺寸芯片的复杂集成。
事实上,英特尔自家的数据中心GPU Max系列就是EMIB技术规模化应用的典范,它通过先进的3.5D封装,将47颗有源芯片和超过1000亿晶体管集成在一起。
市场动向也值得玩味。近期有行业报道指出,苹果和高通已经开始招募具备EMIB经验的工程师。同时,英特尔的封装业务部门据称也在积极接触AI ASIC客户,探索为台积电等代工厂制造的芯片提供后续封装服务的可能性。特别是在台积电CoWoS先进封装产能持续紧张的背景下,市场对EMIB这类替代方案的兴趣正在升温。
回过头看,OpenAI的专利将技术路线明确指向嵌入式逻辑桥,又强调了与UCIe、HBM标准的兼容。这些线索叠加在一起,很难不让人联想到英特尔的EMIB作为其潜在技术路径的可能性。至少,在封装架构的哲学上,双方站在了同一阵线。
专利之外:Titan计划与更大的棋局
当然,这份专利绝非孤立事件。它是OpenAI庞大硬件战略中,一块已经浮出水面的关键拼图。
时间拉回到2025年10月,OpenAI与芯片设计巨头博通正式宣布达成战略合作。双方的目标是共同研发并部署规模高达10吉瓦的定制AI翻跟斗,计划从2026年下半年开始交付,并在2029年底前完成全面部署。这场合作酝酿已久,其核心逻辑在于,将OpenAI在大模型研发中获得的底层架构认知,直接转化为硬件设计,而非继续适配通用的GPU。
这款内部代号为“Titan”的芯片,据称将采用台积电3纳米工艺制造,目标是在2026年底前量产。与此同时,基于更先进工艺的第二代芯片也已进入规划阶段。在供应链上游,三星据传已签署协议,将为Titan供应12层堆叠的HBM4内存。

Titan的首要定位是推理侧。随着ChatGPT等服务的用户规模滚雪球般增长至每周超8亿,推理所产生的算力成本正成为OpenAI不可忽视的重负。与通用GPU相比,为推理负载深度定制的ASIC芯片,在能效和单位成本上拥有结构性优势。这其实是谷歌当年自研TPU的核心逻辑,如今OpenAI正在走一条相似的路。
OpenAI硬件副总裁Richard Ho在公开演讲中清晰地阐述了这一全栈逻辑。他指出,优化不能只盯着芯片本身的峰值算力,而必须贯穿模型架构、编译器、芯片、硬件系统乃至计算内核的整个链条。“许多厂商宣传的峰值性能,在真实场景中根本无法实现,”他强调,“只有打通全栈,才能精准控制和优化真实的吞吐与延迟。”这番话,点明了OpenAI进军硬件的深层动机:唯有掌握全栈,才能实现端到端的极致优化。
从这个宏大视角回看,专利中那种能集成20组HBM的封装方案,与Richard Ho所描述的、需要海量分布式内存来支持长效运行的AI智能体,形成了完美呼应。当AI任务需要持续数天并维护庞大的状态数据时,单个GPU的显存容量早已捉襟见肘。而这种高密度内存封装方案,正是为应对此类未来负载而准备的硬件答案。
算力成本与新的护城河
对于OpenAI而言,AI算力成本已然是一个关乎生存的战略问题。
公开数据估算,建设1吉瓦规模的数据中心,总投资约500亿美元,其中超过300亿将用于采购高端加速芯片。目前,这部分支出主要流向了英伟达的GPU,但其成本结构和供货节奏完全不受OpenAI控制。
自研芯片的核心商业价值在此凸显。有知情人士透露,通过与博通合作定制,OpenAI的芯片采购成本有望比直接采购英伟达GPU降低20%至30%。在10吉瓦的庞大部署规模下,这个百分比所对应的绝对金额,足以构成决定性的竞争优势。
然而,更深层次的护城河来自于技术闭环带来的自我强化。为自身推理负载定制的芯片,能天然完美契合OpenAI模型的计算特征,在注意力机制、矩阵乘法等关键操作上实现深度优化。而这些硬件优化经验,又会反过来加深对模型架构的理解,从而指导下一代芯片的设计,形成一个不断强化的迭代飞轮。谷歌TPU历经十余年发展,已与Transformer架构深度耦合,OpenAI正在复刻这条路径,只是起步更晚,时间窗口更为紧迫。
此外,自研芯片也是应对供应链风险的一招妙棋。英伟达GPU交货周期长、产能紧张已是行业常态,而台积电的先进封装产能也已被主要客户大量锁定。在算力竞争白热化的背景下,掌握一个独立的芯片来源,意味着对自身业务扩张节奏拥有了更强的掌控力。
当然,风险与机遇并存。专用芯片最大的挑战在于AI算法的快速迭代——今天为之优化的计算模式,可能在一两年后就被全新的架构所取代。芯片研发周期长达18-24个月,而AI技术的演进则以季度计。如何让硬件设计与快速变化的软件需求保持同步,是贯穿始终的难题。这也正是Richard Ho强调必须大幅压缩芯片研发周期的原因所在。
从一张专利图,到一套系统
纵观全局,OpenAI这项专利的意义,或许远超一项具体的封装技术本身。它更清晰地揭示了一种系统性的技术思维。
嵌入式逻辑桥方案,解决的是一个具体的封装瓶颈,但其终极指向,是重构整个计算基础设施。更多的HBM意味着更大的模型可以常驻片上内存,更低的内存访问延迟意味着更高的推理效率,更灵活的芯粒组合则意味着更快的产品迭代能力。这些优势环环相扣,共同构成了支撑下一代AI应用(如长效智能体)所必需的硬件基座。
从技术渊源上看,嵌入式逻辑桥的理念并非OpenAI首创,英特尔EMIB已拥有近十年的实践积累。OpenAI最终是借助英特尔的封装能力将专利落地,还是与台积电、三星等伙伴开发类似方案,将是其硬件战略能否顺利实施的关键观察点。
但可以确定的是,这份专利、Titan芯片计划、与博通的深度合作,以及其硬件团队不断向外传递的技术理念,共同描绘出了一张清晰的战略图谱:OpenAI正试图将算力的主导权,从外部供应商手中逐步收回,并将其深度融入自身AI服务的血液之中。这场软硬一体的深度融合,才刚刚开始。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

童颜女神阿Sa蔡卓妍结婚!男方是小10岁的健身教练
童颜女神阿Sa蔡卓妍结婚!男方是小10岁的健身教练 喜讯传来!就在刚刚,阿Sa蔡卓妍在社交媒体上公布了结婚的消息,配文写道:“恭喜我嫁你,恭喜你娶我,以后请多多指教,多谢大家的祝福。” 言语间满是甜蜜与笃定。 照片中,二人对着镜头大秀婚戒,那份溢于言表的幸福,几乎要穿透屏幕。消息一出,网友们也火速集

被中国禁止!Meta准备撤销收购Manus
被中国禁止!Meta准备撤销收购Manus 一则重磅消息在科技与投资圈传开。根据国家发展改革委4月28日发布的公告,外商投资安全审查工作机制办公室已经依法依规,对外资收购Manus项目作出了禁止投资的决定,并要求相关方撤销这笔交易。 市场反应很快。有媒体报道指出,在监管决定下达后,Meta方面已经开

SRE实战指南:从监控到容灾,构建企业级稳定性防线
很多人认为SRE就是一个“全栈岗位”——招一个人,就能解决所有稳定性问题。这种理解既片面,又过于理想化。 今天,我们就从一线实践出发,聊聊应该如何真正理解SRE。 很多人认为SRE就是一个“全栈岗位”——招一个人,就能解决所有稳定性问题。这种理解既片面,又过于理想化。今天,我们就从一线实践出发,聊聊

亚马逊ipi计算公式详解
在亚马逊上做生意,库存管理要是没做好,那可真够头疼的 你的库存绩效指标(IPI)分数,如同店铺的“健康体检报告”。分数一旦亮起红灯,仓储空间受限还是小事,长期仓储费悄无声息地侵蚀利润,那才叫真正的心痛。不少卖家正是由于没彻底吃透IPI的计算逻辑和提升门道,才频频踩坑。今天,我们就来把IPI的评分机制

如何批量保存1688商品图片?实在Agent智能驱动
在全球供应链越来越数字化、灵活化的今天,企业采购和电商运营的效率比拼,已经深入到数据获取和处理这些具体环节里。一个很典型的场景就是:面对1688上成千上万的供应商和海量商品,采购或者运营的同事,怎么能快速批量保存、整理那些商品主图和详情图? 过去,大家惯用的办法是手动右键另存为,或者求助于各种层出不








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
