




通用自进化Agent新突破:30k上下文就够了,token消耗也下降近9成

一、将上下文信息密度最大化
长程智能体(Long-horizon Agent)的性能,说到底,一直被上下文窗口所束缚。我们常看到两个典型困境:一是“上下文爆炸”,工具描述、记忆检索、原始环境反馈等信息在多步交互中不断堆叠,最终把真正关键的决策信息挤出了模型的注意力范围;二是“经验清零”,每次任务完成后,成功的路径就被遗忘,遇到相似任务时又得从头摸索。结果就是,Token消耗随着任务数量线性增长,但实际能力却停滞不前。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
面对这些挑战,A3实验室(Advantage AI Agent Lab)的团队提出了一个新思路——GenericAgent(GA)。这个系统的设计哲学非常聚焦,就是围绕“上下文信息密度最大化”这一个核心原则,来构建一个能够自我进化的通用LLM智能体。

(论文链接:https://arxiv.org/pdf/2604.17091)
效果如何?根据论文数据,在任务完成率、工具使用效率、记忆有效性、自进化能力和网页浏览等多个维度上,GA不仅性能超越了主流智能体系统,更关键的是,它消耗的Token数和交互轮数更少,并且能够随着时间持续进化。
举个例子,在Lifelong AgentBench测试中,GA仅用222k输入Token(这仅仅是Claude Code的27.7%,OpenClaw的15.5%)就实现了100%的任务完成率。在重复执行9轮的GitHub研究任务上,其Token消耗下降了惊人的89.6%,工具调用次数也从最初的32次收敛到了稳定的5次。
那么,这个“信息密度最大化”具体怎么实现?研究团队将其拆解为三个质量维度:完整性(Completeness)、简洁性(Conciseness),以及作为约束条件的自然性(Naturalness)。
完整性好理解,就是确保当前决策所需的所有信息都明确存在于上下文中,避免模型去依赖隐式假设或进行“幻觉”推断。简洁性则要求大刀阔斧地剔除所有无关和冗余内容,让模型的注意力牢牢聚焦在关键决策信号上。而自然性则是一种形式约束,防止为了压缩而使用过度人造的编码,导致模型反而难以理解。
这里面的核心矛盾,其实在于完整性和简洁性之间:包含更多潜在相关信息会提升完整性,但必然会损害简洁性。即便上下文窗口无限大,这个矛盾依然存在。GA的整个系统,就是围绕解决这一矛盾而构建的,其支柱可以概括为四点:极简原子工具集、分层按需记忆、自进化机制,以及上下文截断与压缩策略。
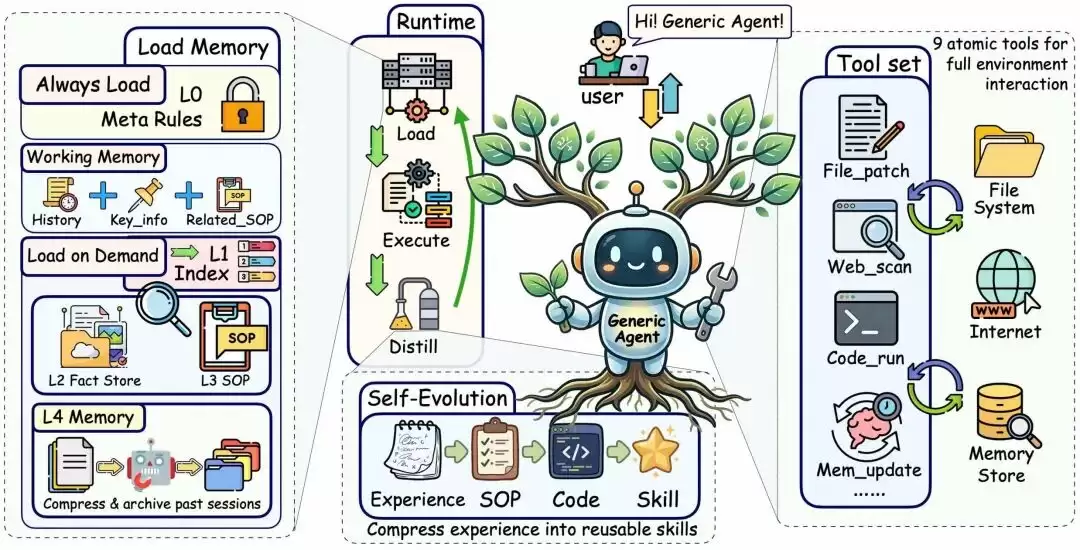
(图|GA整体架构。它遵循统一的智能体循环:基于当前任务和相关记忆构建执行上下文,生成输出或调用工具,并通过结构化反馈来更新系统。)
1.极简原子工具集:用组合代替穷举
GA的工具箱非常精简,只有9个“原子工具”,分布在5个能力域:文件读写与精确编辑(file_read, file_patch, file_write)、受控环境代码执行(code_run)、网页检视与浏览器操作(web_scan, web_execute_js)、上下文与记忆维护(update_working_checkpoint, start_long_term_update),以及人在回路决策(ask_user)。
相比之下,Claude Code在源码层暴露了53个工具,OpenClaw也有18个工具工厂,运行时还会动态注入更多插件。工具数量多,真的好吗?研究团队指出了两个层面的代价:在Prompt层面,每个新工具都会扩大模式描述和说明,挤占本就宝贵的上下文预算;在策略层面,行动空间的膨胀和工具选择歧义性的增加,会让规划过程变得更加脆弱。
GA选择工具最小化,基于两个关键条件:原子性(每个工具对应一个不可再分的基本能力)和组合泛化(复杂行为通过原子工具的顺序组合来实现)。理论上,仅凭一个万能的code_run工具就能模拟其他所有功能,其余8个工具的存在,并非为了扩展能力边界,而是作为“快捷方式”来显著降低决策成本。
不仅如此,每个工具内部也做了深度优化。例如,file_patch工具强制要求old_content必须唯一匹配,零匹配或多匹配都会快速失败,避免无效尝试。web_scan工具则内置了布局分析算法,它会克隆DOM、计算每个元素的可见性,并移除被覆盖或隐藏的元素,最终输出的Token消耗比原始DOM降低了一个数量级。
2.分层按需记忆:让L1索引保持有界
GA的记忆系统设计得非常精巧。它从功能上划分为工作记忆、常驻记忆和长期记忆,在实现层则具体定义为L1索引层、L2事实层、L3 SOP层和L4原始会话归档层。其中,L1是常驻部分,L2和L3共同构成长期记忆,L4则负责持久化存储与追溯。
这里的一个关键设计是:L1层只记录“某类知识存在”,而不记录其具体内容。新条目只有在出现真正全新的知识类别时才会被加入。这使得L1的描述长度,从理论上逼近了知识集合范畴结构所对应的Kolmogorov复杂度。大语言模型本身充当了解码器——一旦它推断出某项能力或事实是存在的,就会通过工具调用,将完整内容从更深层(L2/L3)取回。这样一来,L2和L3可以无限增长,而作为入口的L1却能始终保持紧凑。
此外,系统还引入了meta-memory(元记忆)层,用于定义整体记忆地图、核心规则与更新边界,防止任意写入、历史误读和跨任务信息泄漏。完整的元SOP内容按需通过文件读取加载,并非默认预置。长期记忆的沉淀采用“触发式提交”而非即时写入:信息先进入验证阶段,确认其有效且可复用后,才以小步增量的方式写入L2或L3,并相应更新L1索引。
3.自进化:从纯文本SOP到可执行代码
GA将工具层与知识层进行了分离。工具接口对所有任务保持稳定,而所有与任务相关的能力,都以SOP(标准操作程序)文件和可复用脚本的形式存储。智能体可以使用自身的工具去读取、创建和修改这些“资产”。这种分离确保了学习新任务不会干扰已有的技能。
在多轮会话中,真实的执行反馈会逐步精炼SOP。常见的子任务会自然演化为稳定的、可复用的脚本,这意味着知识从纯文本指令升级为了可执行的代码。GA在L4层保存原始的动作轨迹,但不会自动提升到L2或L3。可复用的SOP只在显式的“整合步骤”中产生,触发时机通常是里程碑事件、子目标达成或系统错误恢复后。整合阶段严格遵循“No Execution, No Memory”规则,只保留经过成功工具执行验证的内容,而猜测、临时的中间状态、失败的决策分支都会被系统性地丢弃。
为了避免陷入错误的重复循环,GA引入了三级失败升级机制:首先基于报错进行局部小修;如果持续失败,则放弃当前路径,切换策略或寻找缺失信息;当所有自动尝试都失败后,系统会暂停并请求人工介入。
4.上下文截断与压缩:把窗口稳在30k以内
许多智能体框架依赖于1M甚至更长的扩展上下文窗口,并假设上下文越长,推理效果就越好。GA持相反的观点:当前模型的“无幻觉上下文长度”大约比其标称值要小一个数量级。因此,GA将上下文预算坚定地设定在30k Token以内,把投入放在“压缩”而非“扩张”上。具体压缩过程分为四个阶段:
阶段一(工具输出截断):每个工具的返回值在进入消息历史前,会先按字符阈值进行裁剪。例如,code_run输出限10000字符,web_scan的文本模式也限10000字符,超过部分保留首尾各L/2,中间用省略号代替。
阶段二(标签级压缩):大约每5轮触发一次。重复的工作记忆块被替换为占位符;reasoning和tool标签的内容被截断为约800字符的首尾窗口;最近10条消息享受豁免,不被压缩。大约80%的轮次能命中prompt缓存。
阶段三(消息驱逐):当总历史长度超出字符预算时,先按更严格的规则重新执行“阶段二”的压缩,再按先进先出(FIFO)原则删除最旧的消息,直到历史规模降至总预算的60%以下。
阶段四(工作记忆锚点):每次工具调用后,系统会自动在下一条用户消息中附加最近20轮的单行摘要、当前轮次号以及智能体维护的key_info块。在阶段三的驱逐发生后,这段锚点信息就成为连接长期记忆的唯一桥梁。
这套极简设计的成果是显著的:GA的核心代码大约只有3300行,其中央智能体循环更是仅有92行。作为对比,OpenClaw的代码量约为53万行,是GA的160多倍。
GA以自托管CLI程序的形式对外暴露,命令行并非内部平台的封装层,而是系统的原生执行界面。这种极简架构自然催生了一些有趣的能力:
- Subagent派发:父智能体可以直接通过执行标准终端命令,在后台启动多个GA实例,每个子进程都在独立的内存空间中运行,自带上下文隔离。
- Reflect模式:通过轻量脚本周期性检查触发条件,一旦命中,便将返回字符串作为新任务派发给GA命令行界面。看门狗(Watchdog)与定时任务(Scheduled Task)共享相同机制,仅触发脚本不同。
更进一步,将上述两者结合,便催生出了“自主探索能力”——派发器从用户变成了智能体自身。GA维护一棵持久化的技能树,按照广度、深度、效用、创新性四个维度对候选任务进行打分,并基于实际使用情况,通过反思机制自动调整权重。
二、效果怎么样?
研究团队从五个维度对GA进行了系统性的评估。
1.任务完成与Token效率
在SOP-Bench、Lifelong AgentBench、RealFin-benchmark上,团队对比了GA、Claude Code、OpenClaw和Codex。
结果显示,当基于Claude Sonnet 4.6模型时,GA在前两个基准测试上实现了100%的完成率,达到甚至超过了当时的SOTA基线。
具体来看,GA在Lifelong AgentBench上的输入Token仅为222k,远低于Claude Code的800k和OpenClaw的1.43M。在RealFin-benchmark上,GA取得了65%的综合准确率,超过了Claude Code(Opus模型60%、Sonnet模型55%)、Codex(60%)和OpenClaw(35%)。
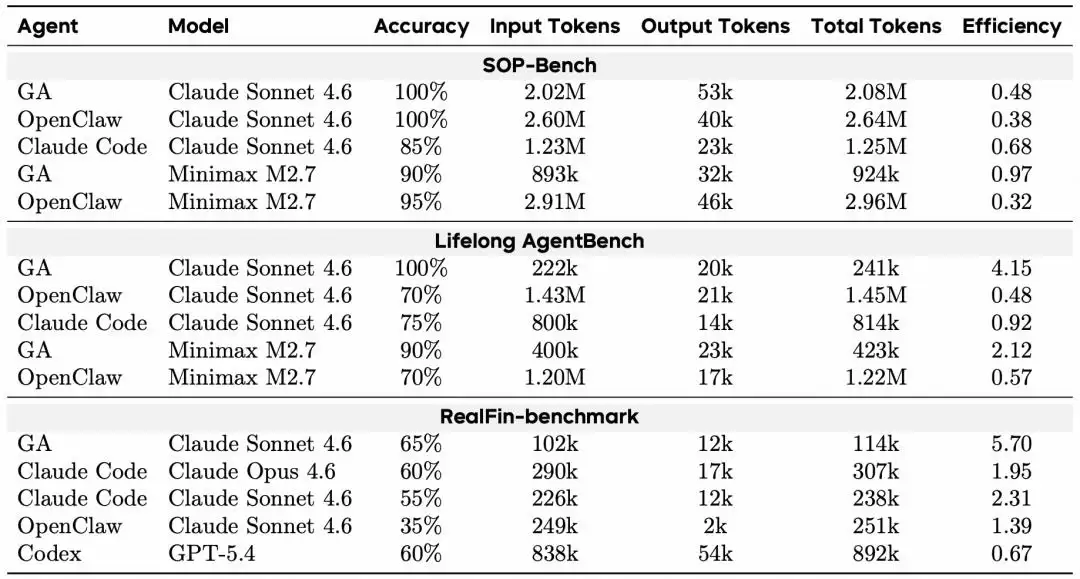
(表|主要Agent基准测试与RealFin基准测试中的任务完成率与Token效率)
2.工具使用效率
在5个长程复杂任务上,GA与Claude Code都实现了100%的成功率,但GA的总Token消耗仅为Claude Code的35.1%。同时,请求数从32.6次降到了11.0次,工具调用次数也从22.6次降到了12.8次。

(表|长程复杂任务结果)
3.记忆系统有效性
团队在SOP-Bench的dangerous_goods子集上进行了记忆消融实验。结果显示,GA在无记忆(No-Memory)模式下的任务成功率为13.87%,在全记忆(Full-Memory,规模575 Token)模式下为52.44%。而仅使用165 Token的浓缩记忆(Condensed Memory)模式,成功率就达到了66.48%,与使用288 Token的冗余记忆(Redundant-Memory)模式分数相同。
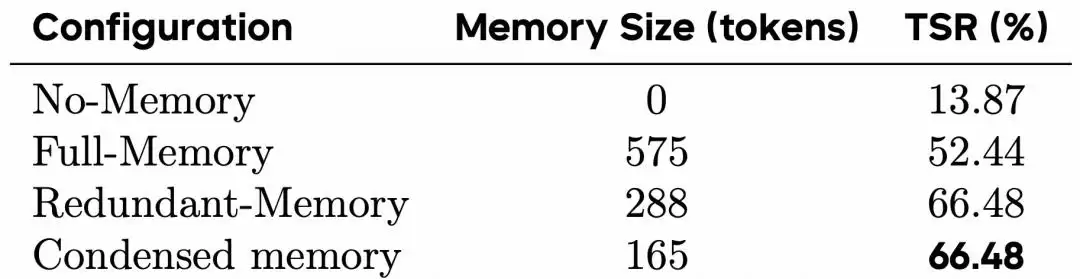
(表|SOP-Bench dangerous_goods记忆消融实验)
在LoCoMo长期事实记忆评测中,GA在Multi-Hop、Temporal、Open-Domain、Single-Hop四个类别上全部取得了SOTA的F1与BLEU-1分数。其中在多跳问答上,F1分数达到43.33,超过了Mem0(39.32)和A-MEM(29.03),且不依赖任何嵌入模型或向量数据库。
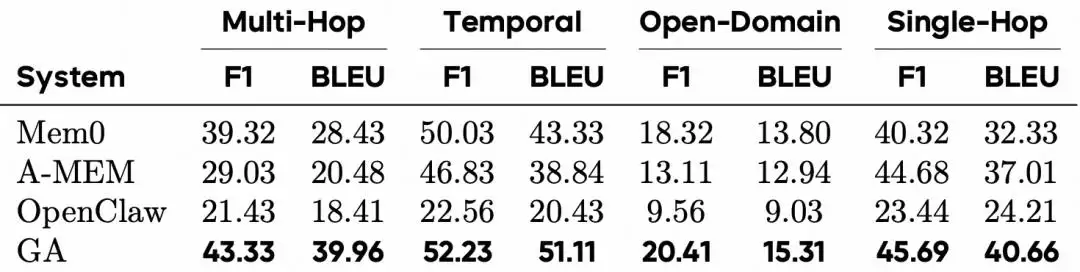
(表|LoCoMo长期事实记忆评测)
一个更直观的例子是:在装入相同的20个技能并大量使用后,仅发送一句“Hello”,GA的完整Prompt长度仅为2298 Token,而Claude Code、Codex、OpenClaw则分别高达22821、23932、43321 Token。
4.自进化能力
以LangChain的GitHub研究任务作为纵向追踪目标,GA在9轮执行内,从最初耗时7分30秒、进行32次LLM调用、消耗222203 Token,收敛到了仅需1分38秒、5次调用、消耗23010 Token。时间下降了78.2%,调用次数下降了84.4%,Token消耗下降了89.6%。从第6轮到第9轮,Token消耗稳定在23k±1k的区间内。其中,输入Token从15581降到了1323,缓存读取(cache-read)从183375降到了19034,主要节省来自于调用次数的“坍缩”,而非单次响应的缩短。
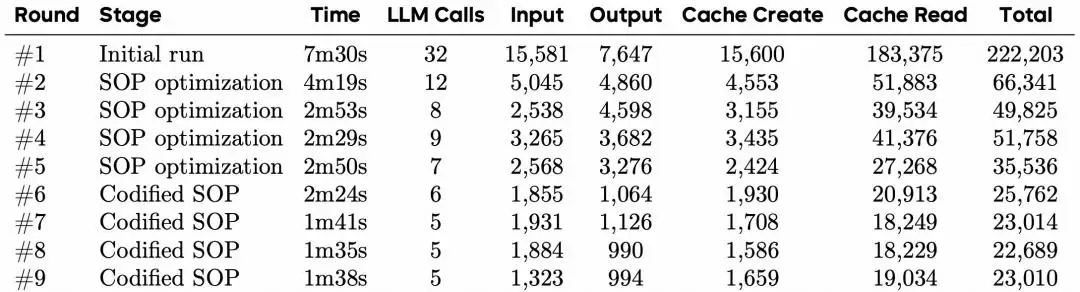
(表|在LangChain GitHub研究任务上的9轮演化轨迹)
此外,在8个基准任务上,后续GA执行所消耗的Token数均少于首次执行,平均下降79.3%。每个任务都呈现出“冷启动-快速收敛”的模式:首轮承担SOP适配成本,第二、三轮便直接复用,性能稳定下降。其中,长程状态转移任务(Category D)节省最多,达到92.0%。作为对比,OpenClaw在三次重复执行中未显示出收敛趋势,其B2任务的Token消耗在1370k、2330k、2130k之间反复波动,表明其仍在重复探索。
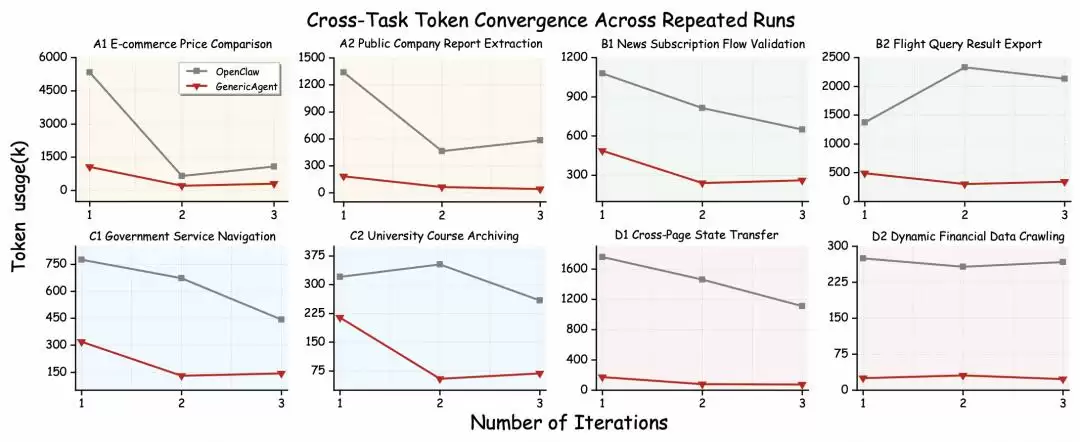
(表|GA与OpenClaw在多次重复运行中的跨任务Token收敛情况)
5.Web浏览能力
在WebCanvas(12项任务)、BrowseComp-ZH(10项任务)和Custom Tasks(22项任务)的对比评测中,GA的得分(分别为0.834、0.60、0.577)均超过了OpenClaw(0.722、0.20、0.50),但其Token消耗仅为OpenClaw的1/4到1/3。

(表|3项基准测试的网页浏览评估结果)
三、不足与未来方向
当然,GA目前依然存在一些局限性。
例如,30轮的执行上限使得高度复杂的研究任务可能横跨多个会话,而会话间的连续性目前只能通过书面报告和任务列表注释来维持。基于反思的权重调整仍是初步设计,尚未在多样化的真实工作流上积累足够验证其有效性的长期数据。记录错误与偏好的自我改进日志,目前仍依赖人工策展。技能树的高级管理功能,如合并冗余类别、淘汰过时工具、重组拓扑结构等,目前也完全依赖于手工操作。
研究团队指出,极简架构是智能体实现自主进化的必要前提。只有当核心代码从数十万行降到几千行时,智能体才有能力去读懂并修改自身。从技能整合,到自主探索,再到架构自更新,这是智能体进化的三个递进维度,但完整路径的验证仍有待未来研究。
总而言之,GenericAgent采取了一条与主流思路相反的路径。它没有追求“让智能体在更长上下文中思考”,而是反其道而行,将上下文窗口压缩到30k Token,将工具收敛到9个,并将经验沉淀为可执行代码。
在当前Token成本与响应延迟已成为大规模部署核心约束的背景下,这种以提升信息密度而非单纯扩大容量为目标的系统设计思路,或许比一味堆叠更长的上下文窗口,更值得我们关注。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

财务系统更换的风险?企业转型的隐形陷阱与应对策略
一、财务系统更换:一场不容有失的“心脏手术” 如果把企业比作一个生命体,那么财务系统就是它的“心脏”。这颗“心脏”一旦老化,更换就成了必须面对的课题。但这绝非一次简单的软件升级,而是一场精密、复杂、牵一发而动全身的“外科手术”。数据显示,超过70%的ERP(企业资源计划)项目实施未能完全达到预期,问

模拟人工点击软件有哪些?类型盘点与应用指南
在企业数字化转型的浪潮中,模拟人工点击软件:从效率工具到智能伙伴 企业数字化转型的路上,绕不开一个话题:如何把那些重复、枯燥的电脑操作交给机器?模拟人工点击软件,正是因此而成为了提升效率、降低成本的得力助手。那么,市面上的这类软件到底有哪些?答案其实很清晰。它们大致可以归为三类:基础按键脚本、传统R

ai智能体发展前景:2026年AI Agent如何重塑全
一、核心结论:AI智能体是通往AGI的必经之路 时间来到2026年,AI智能体这个词儿,早就跳出了PPT和实验室的范畴。它不再是飘在天上的技术概念,而是实实在在地成了驱动全球数字化转型的引擎。和那些只能一问一答的传统对话式AI不同,如今的AI智能体(Agent)本事可大多了:它们能自己规划任务步骤、

ai智能体主要通过哪一层与外部系统交互:深度解析Agen
一、核心结论:AI智能体交互的“桥梁”是行动层 在AI智能体的标准架构里,它与外部系统打交道,关键靠的是“行动层”。可以这么理解:感知层是Agent的五官,决策层是它的大脑,而行动层,就是那双真正去执行和操作的手。这一层专门负责把大脑产出的抽象指令,“翻译”成外部系统能懂的语言,无论是调用一个API

ai智能体人设描述怎么写?构建高转化AI角色的深度方法论
一、核心结论:AI人设是智能体的“灵魂” 在构建AI应用时,一个核心问题摆在我们面前:如何写好AI智能体的人设描述?这个问题的答案,直接决定了智能体输出的专业度与用户端的信任感。业界实践表明,一个优秀的人设描述,离不开一个叫做RBGT的模型框架,它涵盖了角色、背景、目标和语气四个黄金维度。有研究数据








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
