




Google Stitch AI生成UI和APP的原理是

Google Stitch:从草图到代码,AI如何打通设计与开发的“最后一公里”
摘要:Google Stitch是Google研发的实验性AI界面开发工具,通过多模态大模型将手绘草图转化为高保真交互界面与前端代码。本文深入解析其多模态视觉解析、组件化语义映射等核心实现机制。
在界面开发的流程里,创意从草图到可交互的代码,往往隔着一道需要大量人力“翻译”的鸿沟。如今,一种新的可能正在浮现。Google Stitch,这款来自Google的实验性工具,正试图用多模态大模型彻底改变这一过程。它的目标很直接:让手绘的线框图或一段简单的文字描述,直接变成一个功能完整、代码清晰的高保真界面。听起来像魔法?其实背后是一套严谨的技术链路在高效协同。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
本文大纲
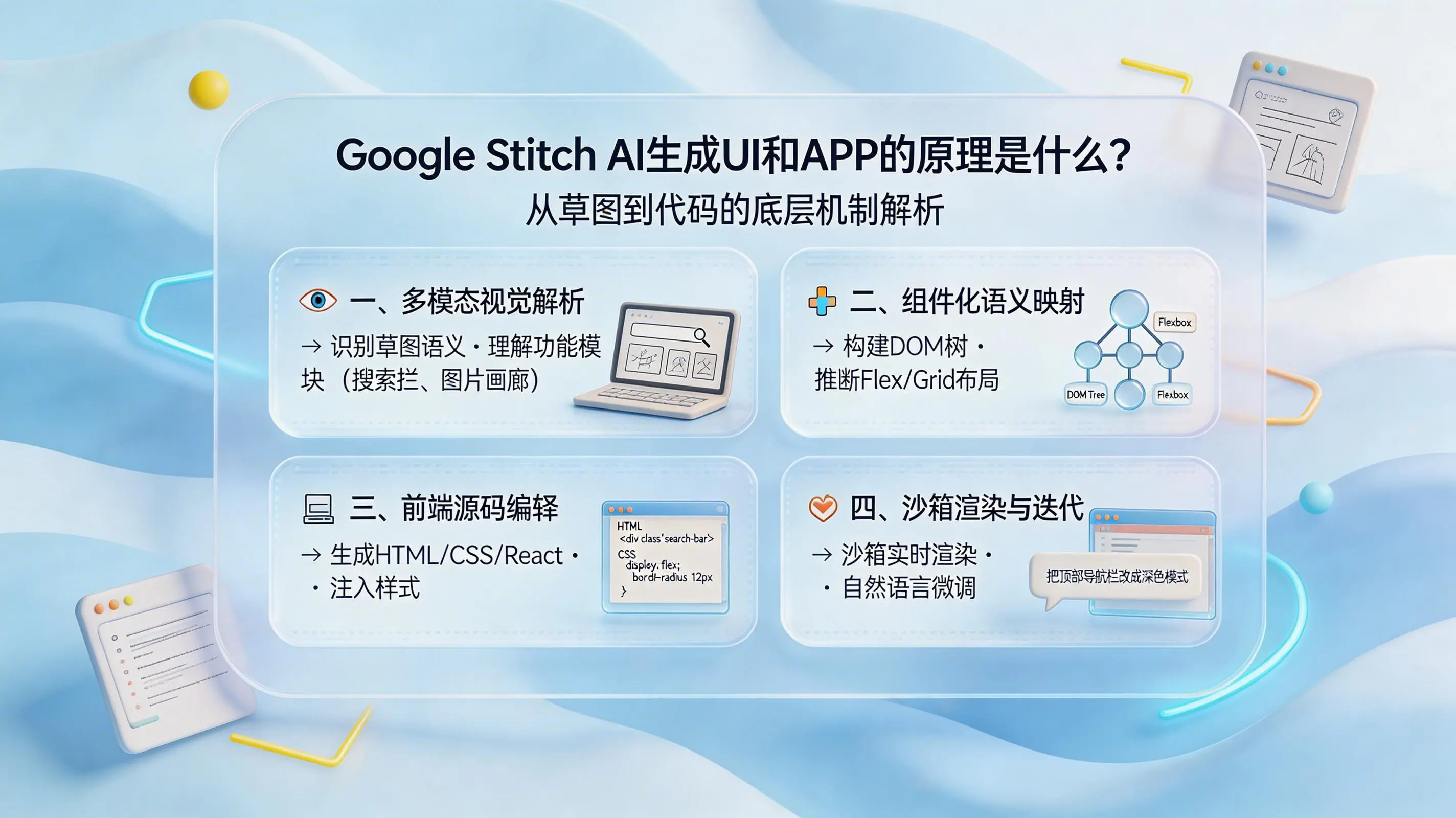
- 一、多模态视觉解析:看懂线框与草图的意图
- 二、组件化语义映射:将像素转化为结构化节点
- 三、前端源码的逆向编译:从抽象结构到可执行代码
- 四、沙箱渲染与迭代闭环:所见即所得的直觉微调
图源:AI生成示意图
一、多模态视觉解析
整个过程的第一步,也是最关键的一步,是让AI“看懂”你的草图。这可不是简单的图像识别。Google Stitch依托于类似Gemini这样的多模态大语言模型,做的事情是“语义理解”。
举个例子,当你上传一张画着几个方框和奇怪图标的草图时,AI的思考路径是这样的:那个带放大镜的矩形框,大概率代表“搜索栏”;旁边几个等距排列的方框,很可能是一个“图片画廊”。这一步的厉害之处在于,它跳过了单纯的像素分析,直接指向了功能意图的识别。简单说,它的任务就是把二维平面上看似随意的线条,翻译成机器能理解的“业务功能模块”清单,为后续的结构化构建打下基础。

图源:AI生成示意图
二、组件化语义映射
看懂之后,下一步就是“搭骨架”。AI需要在内存中,根据识别出的元素,构建一个虚拟的、结构化的界面模型。
这里主要涉及两个核心推断:一是DOM树构建。AI会分析视觉元素之间的空间位置关系——谁包含谁,谁在谁的左边,谁和谁并列——并由此自动推导出HTML的文档对象模型树形结构。二是布局推断。元素之间的间距、对齐方式都不会被忽略,系统会自动将其转化为前端工程中标准的布局逻辑,比如判断该用Flexbox弹性布局还是Grid网格布局来精准还原设计。至此,一个抽象的、但逻辑清晰的应用骨架就在AI的脑海中成型了。
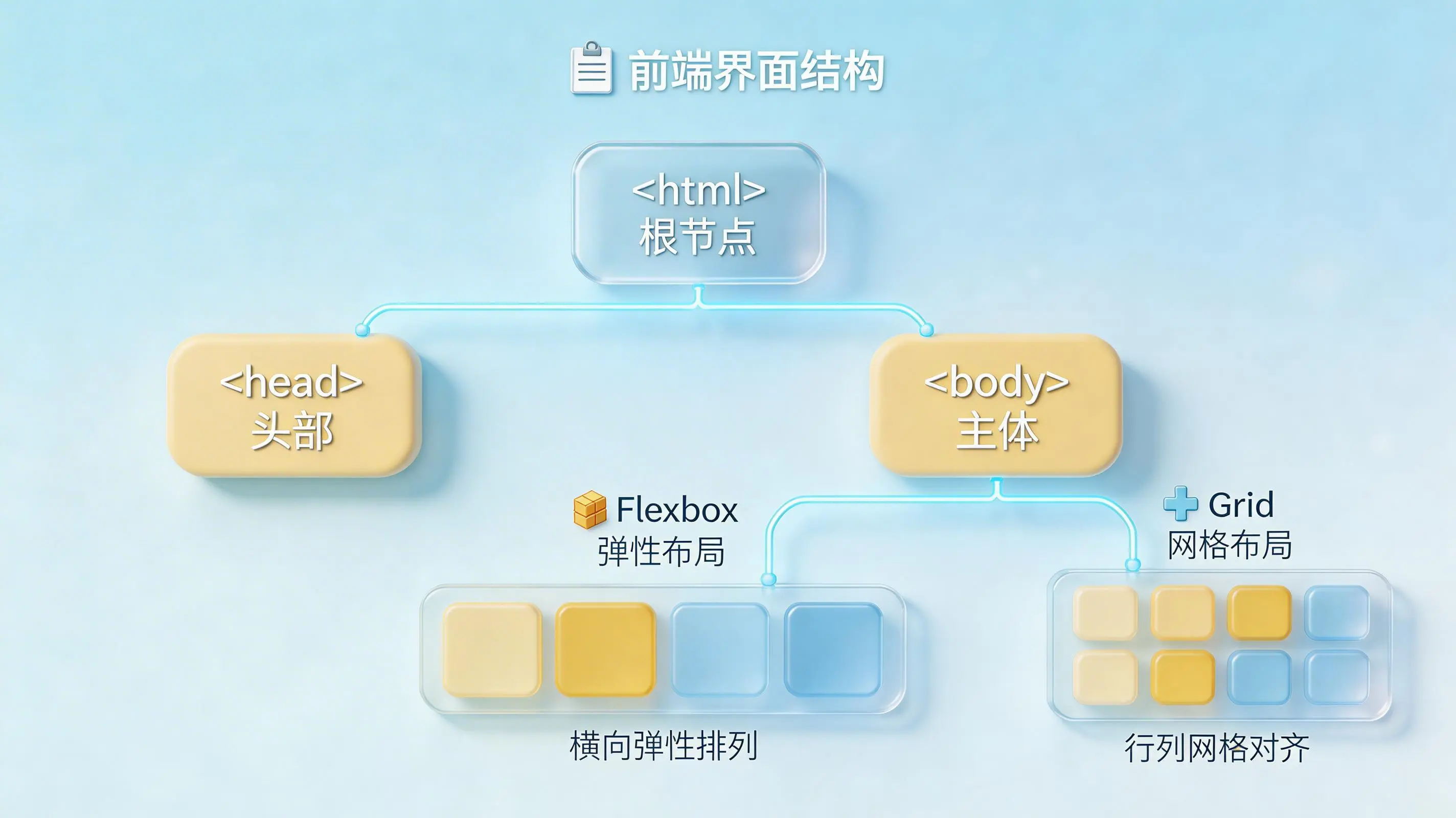
图源:AI生成示意图
三、前端源码的逆向编译
有了精心构建的逻辑骨架,生成实实在在的代码就成了水到渠成的事。这一阶段,AI扮演的是精通多种技术栈的“资深工程师”。
根据预设或指定的技术栈(比如基础的HTML/CSS,或者更复杂的React、Flutter),底层模型会将上一步得到的结构准确地“编译”成标准、整洁的前端源码。更妙的是,它还能处理样式需求。如果你的提示词里包含了“现代极简风”这样的指令,AI会为生成的代码节点智能附加对应的样式属性,比如圆角半径、阴影效果、字体颜色,甚至自动填充合适的占位图片。这一步彻底打通了从“设计意图”到“物理代码”的壁垒。

图源:AI生成示意图
四、沙箱渲染与迭代闭环
代码写出来不是终点,能跑、能改、能调才是生产力工具的核心。Google Stitch提供了一个实时无缝的验证与迭代环境。
生成的代码会立即在一个内置的浏览器沙箱中渲染出来,让你直接看到一个可交互的界面原型,点击按钮、测试流程都如真实应用一般。如果觉得某个细节不对怎么办?传统方式是回头改代码,但在这里,你只需要用最自然的方式说话。比如,在对话框里输入“把顶部导航栏改成深色模式”,AI就会理解这个指令,重新触发从语义映射到代码编译的局部更新流程,并即时刷新沙箱中的界面。这种“所见即所得”加上“语言微调”的闭环,极大地提升了原型迭代的直觉性和效率。
总结
纵观Google Stitch的工作流程,它本质上构建了一套从视觉创意到数字产品的自动化编译流水线。其核心技术链路可以归纳为四个环环相扣的步骤:多模态视觉解析、组件化DOM树映射、前端代码精准编译以及沙箱实时渲染与迭代。这远非简单的图像转代码工具,而是一个深刻理解设计语义与工程逻辑的智能体。
当AI在前端界面生成上展现出如此潜力时,一个更宏大的图景也随之展开:企业级复杂的后端业务流转与自动化,同样需要一个强大的智能中枢来调度协调。市场上,像实在Agent这样的平台,通过原生融合多款顶尖大语言模型,不仅为企业提供私有化部署的安全解决方案,高效连接内网应用;其轻量的社区版,也让个人开发者能够通过自然语言,免代码构建桌面数字助手,轻松实现从触发到执行的全流程自动化闭环。这或许意味着,从创意到产品,从流程到自动化,人机协作的“最后一公里”正在被全面打通。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Lovable 上线移动端 AI 编码应用,支持语音提示生成 Web 应用
4月28日,Lovable上线无代码AI应用构建器 4月28日,初创公司Lovable正式在iOS和Android平台上线了其无代码AI应用构建器。这款产品的核心,主打一个听起来很酷的概念——“氛围编码”。简单来说,它允许那些有想法但可能不懂代码的潜在开发者,随时随地通过语音或文本向AI描述灵感,就

苹果iOS27 细节曝光:三大AI修图神器助攻,支持画幅“脑补”
备受瞩目的WWDC26:苹果将如何用AI重塑你的照片? 全球开发者们的年度盛会——WWDC26,已经定档6月8日。这次大会的重头戏之一,无疑是全新的iOS27系统。根据多方消息,这次更新的核心火力,将集中倾泻在照片应用上。苹果准备了三项突破性的AI编辑工具,目标很明确:在短短数秒内,彻底重构你图像的

Claude深度集成Adobe、Blender等八大神器,AI代画代练时代开启?
创意领域的工作流正迎来一场效率革命 最近,创意工具圈有个大新闻:Anthropic正式宣布,其AI模型Claude已经和Adobe、Blender等八大主流创意软件实现了深度互联。这意味着什么?简单说,Claude的能力不再被关在独立的聊天窗口里,而是通过新增的专属连接器,直接嵌入了平面设计、3D建

国产AI视觉大模型集体“反超”,豆包力压谷歌拿下全球第一
中文视觉大模型洗牌:豆包斩获总榜第一 国内模型全面反超海外 最近一份来自SuperCLUE-VLM的评测报告,在圈内引起了不小关注。这份2026年4月的最新报告揭示了一个关键趋势:中文多模态视觉语言模型的竞争格局,正在发生结构性变动。在对全球17款主流大模型进行深度横评后,结果相当明确——国产AI阵

闹大!漫步者辟谣涉嫌污损伟人形象图片:被人恶意篡改 已报案
漫步者发布严正声明:就网络伪造图片事件进行澄清与维权 近期,围绕音频品牌漫步者的一系列网络争议持续发酵。从所谓的“橘子洲头单人照”事件,到被指对伟人雕像进行打码,再到其长期产品品控问题被重新提及,一时间,品牌价值观、内部运营审核机制乃至产品质量,都成为了舆论集中审视的焦点。 面对这场突如其来的舆论风








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
