




大模型“降智”真相,找到了

智谱披露GLM-5推理挑战:高压下的乱码与复读,根源竟是两个竞态Bug 智东西作者 陈骏达编辑 云鹏 大规模AI模型服务,一旦扛起每日数亿次调用的压力,会暴露出哪些意想不到的“暗伤”?今天,智谱AI发布的一篇技术报告《Scaling Pain:超大规模Coding Agent推理实践》,就为我们揭开
智谱披露GLM-5推理挑战:高压下的乱码与复读,根源竟是两个竞态Bug

智东西
作者 陈骏达
编辑 云鹏
大规模AI模型服务,一旦扛起每日数亿次调用的压力,会暴露出哪些意想不到的“暗伤”?今天,智谱AI发布的一篇技术报告《Scaling Pain:超大规模Coding Agent推理实践》,就为我们揭开了冰山一角。报告详细披露了其GLM-5系列模型在服务海量Coding Agent请求时,遭遇的推理基础设施深层挑战与系统性解法。
事情起因于一些棘手的线上异常:在高压环境下,部分用户遇到了模型输出乱码、无意义复读或生成生僻字等问题。表面上看,这很像长上下文场景下常见的模型“降智”现象,但智谱团队确认,他们并未进行任何会降低模型精度的优化。那么,问题究竟出在哪里?答案是高并发与长上下文这两个极端条件叠加,触发了底层的系统级“暗礁”。
经过数周深入排查,团队最终锁定了两个隐蔽的底层竞态问题。针对性修复后,相关异常的发生率从约万分之十几,显著降至万分之三以下。不仅如此,报告还公开了智谱自研的KV Cache分层存储方案LayerSplit,该方案在长上下文场景下,将系统吞吐最高提升了132%。
一、本地无法复现,高压才露头:投机采样指标成“照妖镜”
排查之路,始于今年3月出现的三类异常:乱码、复读、生僻字。第一步自然是尝试在本地复现,但奇怪的是,直接回放线上出错的案例,问题却消失了。这其实是个关键信号——大概率不是模型本身的缺陷,而是与环境强相关。
于是,团队开始模拟线上的高压环境。果不其然,当请求压力达到一定程度,每万次请求中就能稳定复现3到5次异常。这种“与具体内容无关,却与系统压力强相关”的特征,几乎将矛头直指高负载下的推理状态管理机制。
三类异常中,复读还算容易检测,乱码和生僻字则像幽灵,难以用简单的规则或模型高效捕捉。怎么办?团队将目光投向了推理日志中的一个“副产品”:投机采样(Speculative Sampling)指标。
投机采样本是一项提升解码效率的性能优化技术:让一个轻量级草稿模型先跑出一些候选token,再由主力模型校验决定是否采纳。这个过程会记录两个关键指标:接受长度和接受率。
分析发现,当出现乱码或生僻字时,接受长度极低,意味着草稿模型生成的token几乎全被主力模型否决。这强烈暗示,主力模型内部的KV Cache状态已经出现了显著偏差。而在复读案例中,接受率却异常偏高,表明损坏的KV Cache导致注意力机制退化,陷入了重复循环的怪圈。
你看,一个原本用于加速的指标,就这样成了洞察系统内部状态的“照妖镜”。基于此,智谱团队建立起一套在线监控策略,将投机采样从单纯性能工具,拓展为关键的质量监控信号。
二、锁定时序漏洞,两个竞态Bug如何导致输出异常
定位到现象背后的线索,接下来就是深挖根因。通过对请求完整生命周期以及推理引擎中预填充与解码分离架构执行时序的细致分析,问题根源浮出水面:问题源于请求生命周期与KV Cache回收、复用时序之间的不一致,从而引发了显存写入冲突。
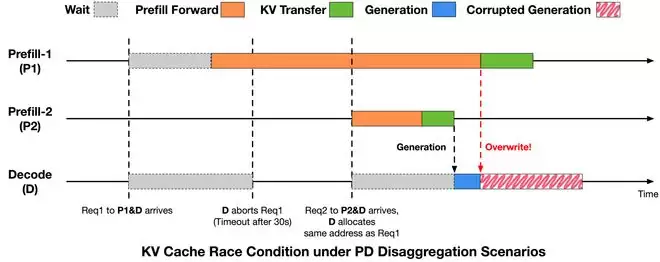
简单来说,就是一个请求的KV Cache数据还没写完,它占用的显存空间就被回收并分配给了新请求,导致新旧数据“打架”。为了根治这个问题,必须在推理引擎中引入更严格的时序约束,在请求终止与KV Cache写入完成之间建立明确的同步关系。
具体的修复方案是,在解码侧触发中止后,必须明确通知预填充侧,确保只有在远程内存访问未开始或已完成的情况下,才允许回收和复用显存。这样一来,就杜绝了KV写入操作跨越显存复用边界。修复后,此类异常的发生率立刻从万分之十几降到了万分之三以下。
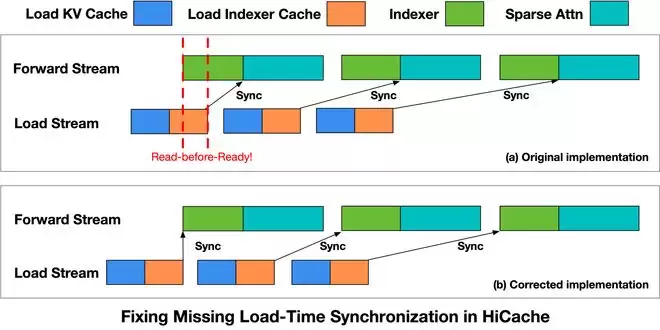
第二个Bug则与Coding Agent场景的特性紧密相关。这类任务输入长、前缀复用率高,因此高效缓存技术至关重要。然而,在KV Cache换入与计算过程重叠执行时,系统缺少一道“安检”,未能保证数据百分百加载完成后再被使用。
这就好比后厨还没备好菜,前厅已经催着上菜了,结果可想而知。修复方法直截了当:在关键的计算算子启动前,插入一个同步点,确保数据就绪后才放行。此修复后,相关问题完全消失,相关代码也已贡献给SGLang开源社区。
三、Prefill吞吐成瓶颈,LayerSplit让吞吐最高涨132%
解决了两个棘手的竞态Bug,团队回过头发现,一个更本质的系统瓶颈依然横亘在面前:在长上下文的Coding Agent服务场景中,预填充阶段主导了整体性能。说得更直白些,系统快不快,主要看“准备数据”这个环节。
核心挑战很明确:如何提升预填充阶段的吞吐量,同时降低KV Cache对显存的巨大占用?为此,智谱团队设计并实现了名为LayerSplit的KV Cache分层存储方案。
由于Coding Agent负载具有上下文长、缓存命中率高的特点,上下文并行成为预填充节点的主要并行策略。但在开源实现中,每张GPU都需要保存所有层的KV Cache,这种冗余存储使得宝贵的显存容量,反而成了限制计算资源利用率的瓶颈。
LayerSplit的思路很巧妙:打破“每卡存全份”的模式,让每张GPU只保存部分层的KV Cache,从而大幅降低单卡的显存压力。在需要计算时,持有某一层Cache的GPU会将其广播给参与计算的其他GPU。
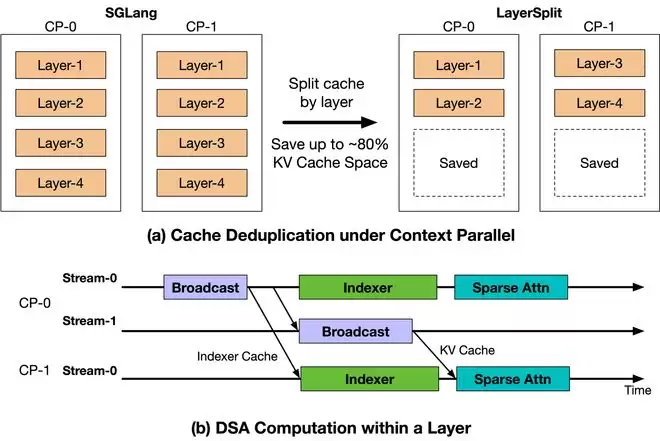
当然,广播会带来额外的通信开销。为了尽可能减少这部分影响,团队进一步设计了KV Cache广播与索引计算的重叠机制,让两者在时间上相互掩盖。整个流程仅引入了约为KV Cache体量1/8的额外通信,对最终性能的影响微乎其微。
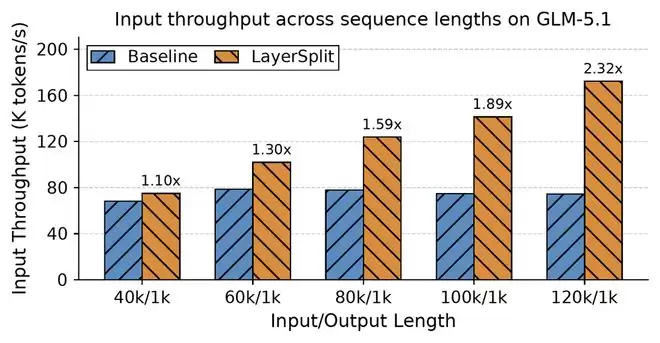
实测数据最有说服力。在缓存命中率90%的条件下,随着请求长度从4万增长到12万,LayerSplit带来的系统吞吐提升幅度在10%到132%之间,而且上下文越长,收益越显著。这从架构层面有效缓解了预填充侧的显存瓶颈。
至此,从两个底层Bug的定位修复,到LayerSplit的架构优化,一套针对高并发、长上下文推理场景的完整基础设施优化方案已然清晰。
结语:输出质量成高并发长上下文场景新痛点
这次技术披露揭示了一个重要趋势:当AI推理服务进入高并发、长上下文的深水区,挑战已不止于传统的吞吐量和延迟指标,输出质量的稳定性同样成为不可忽视的核心痛点。
智谱此次分享的技术细节,从异常现象的监控识别、竞态Bug的深度定位与修复,到架构层面的显存优化,构成了一套相对完整的工程问题排查与性能优化链路。对于所有正在大规模部署AI推理服务的团队而言,这份报告在故障复现思路、监控指标选型、以及保障系统时序一致性等方面,提供了极具参考价值的实践经验。这些经验的公开,无疑为整个社区填补了长上下文推理场景下工程实践的资料空白。

你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:大模型“降智”真相,找到了要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点高盛最新报告分析了人工智能推动下的美股市场状况。报告指出,标普500指数近期创下数十年来最强劲涨幅,市场出现一定过热迹象,例如市场广度收窄、高估值股票交易活跃度接近高位。然而,通过综合评估股价、交易活动、投资者情绪及企业情绪等九项关键指标,其中位数排名处于历史第86个百分位,仍远低于互联网泡沫时期和
西藏芒康一名司机在山路行驶时,主动停车礼让一群横穿马路的散养小鸡。就在他重新启动车辆后不久,发现前方道路因山体塌方而被巨石完全封堵。司机事后表示,从停车礼让到发现险情,前后仅间隔一两分钟,正是那短暂的等待让他恰好避开了塌方发生的时刻。这一事件引发网友对文明驾驶与行车安全之间微妙联系的讨论,相关安全提
针对近期网络上流传的凯越机车资金链断裂、向前创始人张雪求助等传闻,张雪本人已发布视频明确回应,称凯越方面从未联系过自己,并了解到凯越经营状况平稳。此前,凯越机车已于6月6日发布正式声明,驳斥了“破产”、“销量大跌”等一系列不实言论,并表示已固定证据并向公安机关报案,将追究造谣者责任。张雪作为品牌初创
光刻机巨头ASML市值近日攀升至约4 5万亿元人民币,超越其他欧洲企业成为市值第一。这一变化源于投资机构对其EUV光刻机产能的乐观预期,预计年产量将远超市场此前预估。与此同时,其高端光刻机售价高昂,最新机型单价约达25 8亿元人民币。尽管市值登顶欧洲,但与部分下游芯片客户相比,其规模仍存差距,反映了
- 日榜
- 周榜
- 月榜
热点快看