




商汤日日新SenseNova U1多模态模型详解与应用

近期人工智能领域迎来一项重要进展:商汤科技正式开源其SenseNova U1模型。这并非一次常规迭代,其背后所代表的技术路径,可能正在重塑业界对于“多模态人工智能”的认知边界。 简而言之,SenseNova U1是商汤基于其创新的NEO-Unify架构打造的原生统一多模态大模型。其核心价值在于,首次
近期人工智能领域迎来一项重要进展:商汤科技正式开源其SenseNova U1模型。这并非一次常规迭代,其背后所代表的技术路径,可能正在重塑业界对于“多模态人工智能”的认知边界。
简而言之,SenseNova U1是商汤基于其创新的NEO-Unify架构打造的原生统一多模态大模型。其核心价值在于,首次在单一模型架构内,无缝整合了视觉理解、逻辑推理与内容生成三大核心能力。这具体意味着什么?让我们深入剖析。
业界常见的多模态模型通常采用“拼接式”方案:一个独立的视觉编码器处理图像,一个大语言模型处理文本,中间通过适配器进行模态对齐。这种方式如同将多个独立模块粘合,信息在跨模块传递时易产生损耗与延迟。
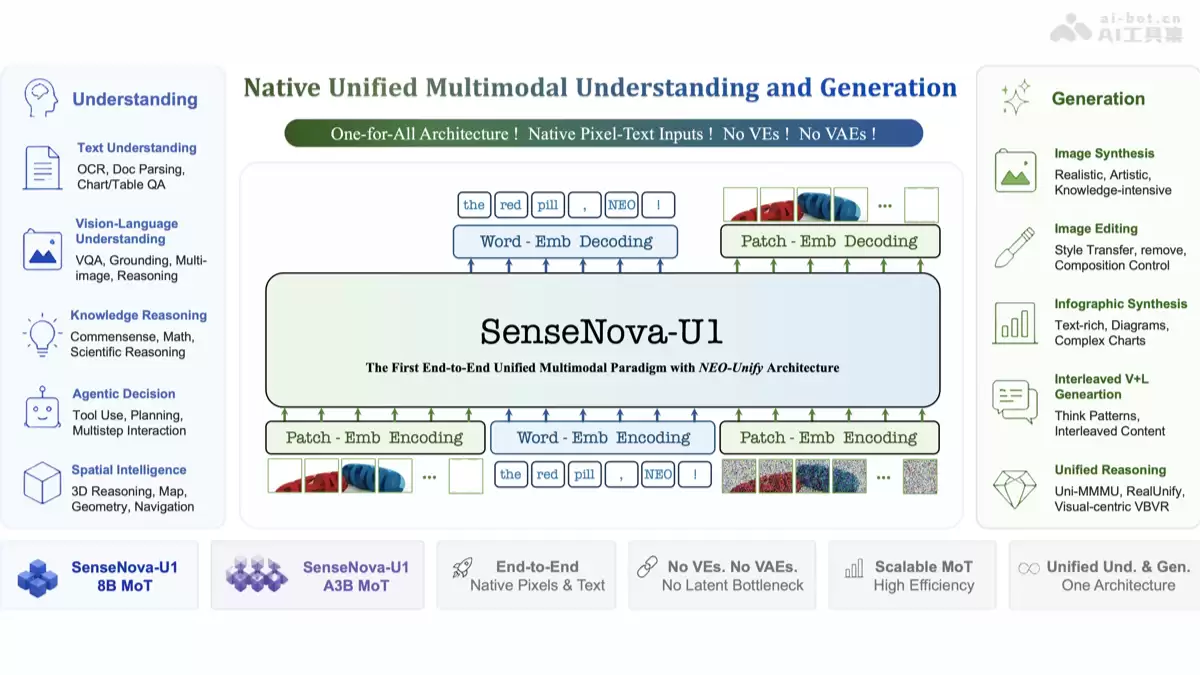
SenseNova U1则选择了截然不同的技术路线——从“第一性原理”出发进行架构重构。它摒弃了传统的视觉编码器与变分自编码器,直接将图像像素与文本Token置于同一表征空间进行端到端联合建模。这就好比模型天生掌握了一门“图文混合语言”,无需经过繁琐的中间翻译过程。
这种原生统一的架构设计带来了显著优势:信息处理路径极大缩短,推理速度得以提升;消除了模态间的“翻译”损失,使得理解与生成的协同更为精准。根据公开评测数据,其80亿参数版本在多项多模态基准测试中达到了同规模开源模型的最优水平,部分性能可比肩商用闭源模型,同时保持了更低的推理延迟。
SenseNova U1的核心功能与应用
那么,这个强调“统一”的模型具体能胜任哪些任务?其能力矩阵覆盖广泛:
- 多模态理解与分析: 涵盖基础的OCR文字识别、复杂文档解析,以及进阶的图表问答、视觉问答乃至多图关联推理任务。
- 图像生成与智能编辑: 不仅能生成写实或多种艺术风格的图像,更擅长处理知识密集型内容的视觉化,例如合成包含复杂数据的信息图表。在编辑方面,支持风格迁移、目标移除、构图控制等精细化操作。
- 交错生成与统一推理: 这是其“统一性”最直观的体现。模型能够像人类创作一样,自然地交替输出文字描述与配图。同时,在需要结合视觉与文本信息的数学推理、常识推理及科学推理任务上,也展现出强大性能。
SenseNova U1的关键技术原理
实现上述能力,依赖于底层技术的根本性创新。主要技术亮点包括:
- NEO-Unify原生统一架构: 这是基石。它从根本上将视觉与语言信号视为同质输入进行处理,而非事后拼接。
- 统一表征空间: 图像像素与文本Token在同一个高维空间内进行直接建模与优化,彻底消除了模态对齐的瓶颈。
- 原生MoT(Mixture of Tokens)机制: 借鉴并发展了混合专家模型的思想,通过Token级别的专家混合机制,更高效地动态调度计算资源,以应对不同模态和任务需求。
- 端到端训练范式: 图像和文本作为整体“复合体”直接输入模型,在单一的前向传播流程中完成从感知、理解到生成的全过程计算。
SenseNova U1的关键信息与获取
对于有意尝试的开发者与研究人员,以下信息至关重要:
- 开发团队: 商汤科技(SenseTime)。
- 开源协议: 模型已开源,相关代码与权重可在GitHub及HuggingFace等平台获取。
- 模型规格: 主要提供两个版本:80亿参数的稠密模型(SenseNova-U1-8B-MoT)以及激活参数量约30亿的MoE稀疏模型(SenseNova-U1-A3B-MoT)。
- 部署要求: 需要GPU计算环境,具体显存需求请参照官方文档。使用者需具备基础的深度学习模型部署与环境配置能力。
SenseNova U1的核心竞争优势
综合评估,SenseNova U1的竞争力主要体现在以下维度:
- 架构统一,效率领先: “一个模型应对多任务”的设计理念,避免了多模块拼接带来的系统复杂性与性能开销,在推理延迟上具备明显优势。
- 轻量化与高性能并存: 80亿参数的“轻量级”模型即可在多项任务上达到开源最优水平,并挑战更大规模的闭源模型,展现出极高的性价比。
- 空间理解与排版智能卓越: 在3D推理、几何理解等空间认知任务上表现突出。尤其值得关注的是,其对复杂信息图表的自动排版与文字渲染能力,已接近商用设计工具水平。
SenseNova U1与同类多模态模型对比
置于当前多模态开源模型的竞争格局中,SenseNova U1的定位十分鲜明。以下是与另外两款热门模型的简要对比:
| 对比维度 | SenseNova U1 | Qwen3VL | Janus |
|---|---|---|---|
| 开发团队 | 商汤科技 | 阿里云 | DeepSeek |
| 架构特点 | NEO-Unify原生统一,无VE/VAE | 视觉编码器+LLM拼接 | 解耦视觉编码统一架构 |
| 模型规模 | 8B / A3B MoE | 8B / 30B-A3B MoE等 | 1.3B / 7B |
| 理解能力 | OCR/VQA/空间推理/文档解析 | 强视觉理解,OCR/VQA领先 | 多模态理解与推理 |
| 生成能力 | 图像生成+编辑+信息图+交错生成 | 主要聚焦理解,生成需独立模型 | 图像生成与编辑 |
| 开源状态 | 开源(Lite版) | 开源 | 开源 |
可以看出,SenseNova U1最显著的差异点在于其“原生统一”的架构,使其在保有强大多模态理解能力的同时,具备了原生、高质量的图像生成与编辑能力,这是许多侧重“理解”的模型所欠缺的。
SenseNova U1的潜在应用场景
这样的技术特性,能够赋能哪些实际应用?其想象空间广阔:
- 智能文档处理: 自动化解析扫描件、PDF等文档,精准提取其中的文字、表格、图表数据,并支持基于内容的直接问答。
- 营销内容自动化生成: 输入产品特性与风格指令,直接生成高质量的宣传海报、信息图,且排版与字体渲染高度可控。
- 精准图像编辑与处理: 实现“指令级”的智能修图,例如移除照片中特定物体、整体风格转换等。
- 多模态内容创作辅助: 辅助创作图文并茂的文章、技术教程或社交媒体内容,自动生成高关联度的配图。
- 机器人具身智能: 作为机器人的统一感知-决策中枢,从通过视觉传感器理解环境,到进行任务规划与推理,再到生成控制指令,可在单一模型闭环内完成。
总结而言,SenseNova U1的出现,不仅标志着一款新模型的发布,更代表了一种技术范式的积极探索。它试图论证,通向更强大、更通用人工智能的路径,或许不在于持续堆叠模块,而在于回归本质,寻求底层架构的深度统一。对于广大开发者、研究者乃至产业界而言,这无疑提供了一个极具参考价值与启发意义的新范本。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

雷克沙JumpDrive A50V 行车记录存储新标杆
雷克沙推出JumpDriveA50V行车记录U盘,采用USB3 2Gen1高速接口,读取速度200MB s,写入最高70MB s,支持哨兵模式与多路同时录像,耐温范围-40℃至85℃,适配特斯拉、理想等新能源车型,已被理想选为原厂标配存储设备。

创邻科技灵机一体机:单CPU驱动千亿模型,开启普惠AI新时代
创邻科技推出「灵机」一体机,单颗主流CPU即可驱动百亿至千亿参数大模型,无需GPU、超频与水冷。搭载RAG和GraphoraX智能体平台,支持150万tokens上下文,性能超越人类阅读速度。以极低成本实现本地化部署,面向中小企业、政府、教育及金融等行业,开启普惠AI算力时代。

苹果液态玻璃设计遭抵制:用户批干扰视线,呼吁立即整改
苹果液态玻璃设计引发用户强烈抵制,被批干扰视线、影响阅读。测试版存在通知文字不清、控制中心视觉混乱等问题。苹果可能调整,该设计面向未来AR眼镜等产品,部分用户也有积极反馈。

时空壶W4Pro凭何成为AI同传行业标杆与引领者
时空壶W4Pro基于BabelOS系统实现矢量降噪与双向同传,将响应和翻译延迟标准提升。2024年营收破两亿元,出口量年增长超100%,获亚马逊翻译机最佳销量,在商务、教育、文旅场景中落地,推动AI同传从概念变为现实。

时空壶T1离线翻译机 解锁无网生活沟通自由
时空壶T1离线翻译机依靠端侧AI模型实现无网翻译,支持31组语言对,响应速度0 2秒。具备拍照翻译、三麦克风降噪、eSIM全球流量、12小时续航等功能,覆盖出行、购物、文化探索等场景,实现无网环境沟通自由。








- 热门数据榜



 相关攻略
相关攻略
 2026-07-15 22:01
2026-07-15 22:01
2026-07-15 22:01
2026-07-15 22:01
2026-07-15 22:00
2026-07-15 22:00
2026-07-15 22:00
2026-07-15 22:00
热门教程
2026-07-15 22:01
2026-07-15 22:01
2026-07-15 22:01
2026-07-15 22:01
2026-07-15 22:00
2026-07-15 22:00
2026-07-15 22:00
2026-07-15 22:00
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
















