




魔芯科技获亿元融资 浙大00后团队世界模型产业落地


免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
时间回到2021年,那时ChatGPT尚未问世,大语言模型远未破圈。“世界模型”这个概念也才刚露头角。Da vid Ha和Jürgen Schmidhuber那篇著名的《World Models》论文,还只是让AI在赛车游戏里“做梦”;李飞飞创办World Labs,则是三年后的事。整个领域距离商业化,看上去还很遥远。
就在这一年,还在浙江大学读本科的陈天润,做了一个在当时看来相当激进的决定:成立一家公司,专注做3D和AI。
他接触编程很早,高中就开始写代码。大学期间,他深度参与了大量3D建模与重建的研究,也产出了一些学术成果。创业的初衷很朴素:自己从事的是偏应用的学科,如果能通过商业化的方式,把那些等待落地的新技术推到更多人面前,值得一试。与此同时,他内心有一个关于市场的判断:更强的人工智能一定会出现,而那将带来巨大的机会。
后来的故事证明,这个判断不仅正确,而且验证的速度远超预期。
第三条路
要理解魔芯科技在做什么,得先搞清楚“世界模型”这个概念。
不妨用我们熟悉的大语言模型来类比。大模型的本质是预测下一个词:你输入一段上文,它帮你补出下文。给它小说的前半段,它能续写后半段,因为它“见过”类似的模式。世界模型干的是类似的事,只不过它预测的对象不是文字,而是三维空间中的物理状态。你给它一个当前的场景和某种变化条件,它能推演出下一刻这个世界会变成什么样。
从预测语言的下一个token,到预测世界的下一个状态——这被认为是2026年AI领域最重要的范式迁移之一。
放眼全球,这条赛道上最受关注的几股力量已然清晰。李飞飞的World Labs在2026年2月完成了10亿美元融资,其产品Marble已能从图片和文字生成高保真3D世界,走的是基于3D高斯的技术路线。杨立昆离开Meta后创办的AMI Labs,则探索更偏理论前沿的JEPA架构。此外,Google DeepMind也推出了实时交互世界模型Genie 3。
魔芯选择的,是一条与他们都不同的“第三条路”。
陈天润和团队采用了纯隐式的方法来实现世界模型的扩展。他们没有依赖3D高斯作为中间表示,也没有借助传统的显式几何重建,而是纯粹依靠数据驱动,通过规模来堆叠模型能力。这意味着,模型的表现更取决于数据的质量与数量,而非手工设计的先验规则。
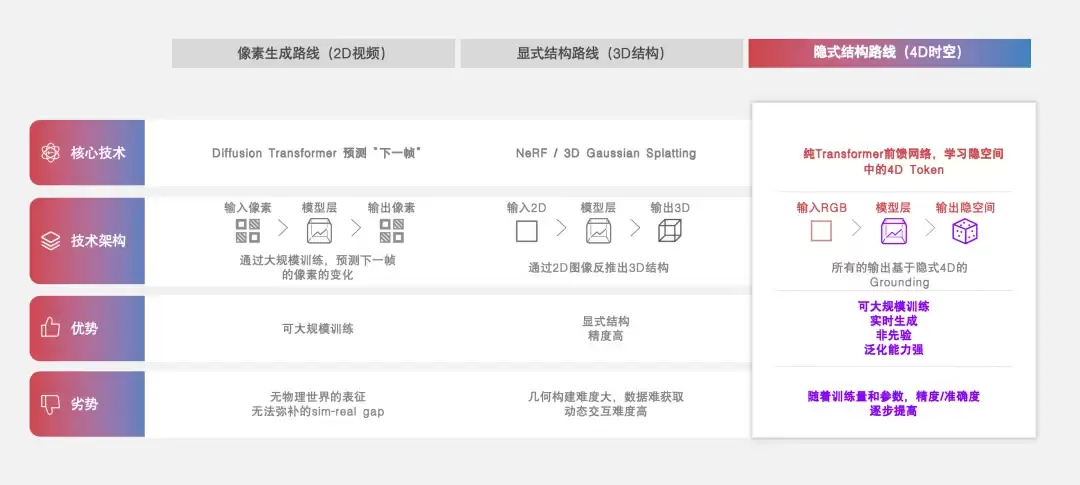
图丨隐式结构路线与其他方案对比(来源:魔芯科技)
这条路线对数据的要求极高,而数据,恰恰是魔芯自2021年成立起就开始布局的核心资产。他们很早就雇佣设计师和美术艺术家制作三维内容,逐步积累了覆盖复杂物理场景、动态自然环境的PB级3D模型与场景资产。在AI领域,高质量的3D数据始终是稀缺资源,无法像文本和图片那样从互联网海量抓取,只能靠时间慢慢沉淀。
“我们不光有数据,还打磨了一套让人能画得更快的工具,”陈天润解释道,“这套工具本身也是壁垒。如果你相信世界模型是一个依赖数据规模效应的范式,那么谁能更快、更高效地产生数据,谁就握有优势。”
在具体的模型设计上,他们的KOKONI-World采用了14B的参数规模,比部分同行公开使用的1.5B模型大了近十倍。更大的网络意味着更强的信息承载能力,但推理速度和成本随之成为挑战。为此,团队设计了一套级联式知识蒸馏方案:目标不是把大模型压缩成小模型,而是将多步推理过程蒸馏为少步推理,在保持模型尺寸不变的前提下,大幅减少推理迭代次数。
另一个关键设计是相机感知记忆结构。KOKONI-World生成的场景背后,存储着完整的3D空间信息。当用户在场景中移动视角、探索不同位置后再回头看,场景的几何结构和视觉细节不会崩塌或矛盾。它不是在逐帧渲染画面,而是在构建一个具有空间一致性的场景记忆。

图丨KOKONI-World 4D场景生成效果 图左:RGB视频生成;图右:3D点云生成 (来源:魔芯科技)
这两项技术叠加,让KOKONI-World跑出了一组亮眼的数据:支持长达2000帧(约两分钟)的场景记忆与连续动态预测;能输出1080P全高清的实时交互画面;并提供6自由度的精确相机控制。
魔芯参与的一项前馈式4D基座模型研究,为这个技术选择提供了实验支撑。研究显示,当训练数据扩展到百万量级、模型参数超过10B时,重建误差会出现显著且持续的下降,模型开始展现出长时一致的空间建模能力。这条性能随规模增长的曲线,与大语言模型早期观察到的规律高度相似,这无疑证实了3D和4D场景建模同样遵循Scaling Law(规模定律)。
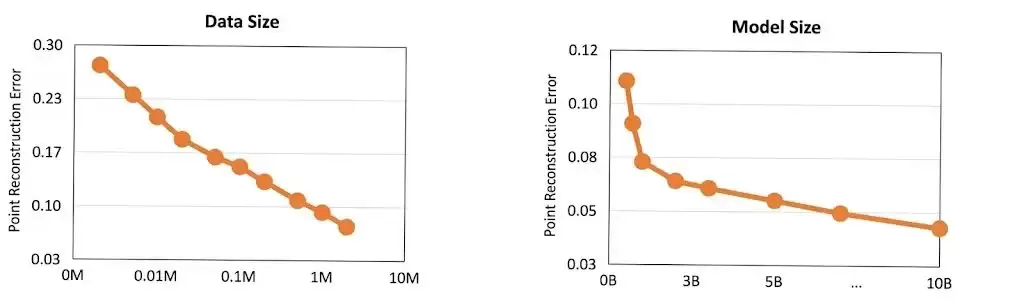
图|实验结果,随着数据量的增加(左图)和模型尺寸提升(右图),模型精度持续提高(误差降低)
年轻团队的牌面
打造出这套技术体系的,是一支平均年龄不到30岁的全博士团队。核心成员来自浙大、中科大、同济等高校,几位研发骨干从博士阶段就深耕多模态大模型驱动的3D重建与视频生成,在相关顶会上发表了数十篇论文。
陈天润将这种团队构成视为一种优势:“我们不是计算机视觉或自动驾驶领域的老兵转行来做这件事。我们是一群搞大模型的人,在直接做世界模型。”他认为,做基础模型就应该采用数据驱动的方式,而他们这批研究者对这种范式有着天然的信心和丰富的实操经验。
作为00后CEO,陈天润坦言在2021、2022年创业早期,确实遇到过因年龄而产生的质疑。但2023年之后,ChatGPT的成功让世界看到了一个事实:许多最前沿的AI创业公司,正是由一群非常年轻的从业者推动的。年轻、精干、没有历史包袱,在快速迭代的AI时代,反而成了一种独特的优势。“国际上很多创新就是这么发生的,”他补充道。
而这群年轻人,也确实拿出了不一样的东西。魔芯的模型具备一项区别于多数同行的能力:它既能输出人类可直观理解的显式结果,如视频、3D点云、3D高斯场景,也能输出纯隐式的token和向量。后者对于机器人、自动驾驶等下游应用更具价值,因为机器决策需要的往往不是一段渲染精美的视频,而是能直接用于路径规划或行为预测的空间表征。这种“两头都能交付”的灵活性,让魔芯在面对不同类型的产业客户时游刃有余。
基于这种能力,魔芯成为了世界模型赛道上少数已经实现收入的团队。他们在2025年就交付了第一版模型,其3D重建服务已对外售卖,支持API调用和定制化开发。在影视娱乐、数字孪生、自动驾驶、具身智能等多个方向,他们已与产业方展开实际的项目对接与交付。部分积累的PB级3D数据资产,也以开放合作的方式提供给其他AI研究团队使用。
从 BERT 到 ChatGPT
进入2026年,魔芯科技的节奏明显加快了。
公司近期完成了由浙创投等国资机构及多家产业资本投资的Pre-A++轮融资,新一轮A轮融资也即将落地。陈天润在有意识地引入产业资本而非纯财务投资人。“行业还处于非常早期的阶段,需要生态伙伴一起共建,这不是一家公司能独立搞定所有事情的时候。”
另一个关键节点是下一代模型的发布。魔芯即将推出参数规模约为现有版本两倍的新模型,核心改进在于支持更高的输入分辨率。此前,用户只能输入分辨率较低的图片,模型能重建的信息细节有限。新版本将能处理更大尺寸的图像输入,从而捕捉和重建更丰富的场景细节。陈天润表示,这个版本在3D建模的准确度和泛化能力上,预计将超越目前市面上的同类模型,并会同步对外开放服务和发表学术论文。
当然,陈天润对当前阶段有着清醒的认识。世界模型作为一个新兴范式,整个行业都还处于能力爬坡期,模型的泛化性和场景覆盖度仍在持续迭代中。他将现阶段比作大语言模型在ChatGPT诞生前的“BERT时代”:基础能力已经涌现,但距离真正引爆市场的产品化爆发,可能还需要一到两年的深耕与打磨。从BERT到ChatGPT,中间经历了GPT-2、GPT-3、GPT-3.5的数代演进,世界模型的演化大概率也需要一个类似的过程。
被问及五年后希望外界如何评价魔芯科技时,陈天润给出了一个明确的答案:“3D的ChatGPT时刻。”
这个目标不可谓不大。ChatGPT之所以成为里程碑,不仅仅因为其模型能力强大,更在于它让普通人第一次直观地感受到了AI的潜力与魅力。所谓的“3D的ChatGPT时刻”,意味着世界模型将不再是实验室论文里的抽象概念,而是真正部署到数以亿计的设备中,让AI能够理解并可靠交互于物理世界的基础能力。陈天润估算,这个方向最终面向的是一个万亿级别的广阔市场。
不过,眼下最紧迫的事情,还是把新一代模型扎实地交付出去。“我们希望做真正能work、能落地的东西,”陈天润强调,“而不仅仅是发布在公众号上的新闻。”

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

国立阳明交通大学解析AI绘画技术如何将线条转化为动态视觉艺术
这项由国立阳明交通大学研究团队主导的创新性研究,于2026年2月正式发表,论文预印本编号为arXiv:2602 12280v1。该研究首次将视觉错觉的创作范式,从静态的空间层面拓展至动态的时间序列,开创了一个名为“渐进式语义错觉”的全新研究方向。 想象这样一个场景:你观看一幅画的创作过程,起笔时分明

MOSI AI音频助手上线 语音实时翻译告别字幕时代
来自MOSI Intelligence、上海创新研究院与复旦大学的研究团队,在arXiv预印本平台发布了一项突破性研究成果(论文编号:arXiv:2602 10934v2)。这项名为MOSS-Audio-Tokenizer的技术,旨在重新定义人机语音交互与音频智能处理的未来范式。 人类听觉系统具备通

上海创新研究院联合打造5B参数轻量级AI画师DeepGen 1.0
2026年2月12日,一项由上海创新研究院联合复旦大学、中国科学技术大学、上海交通大学、西湖大学等国内顶尖科研机构共同完成的重磅研究,在计算机视觉与人工智能领域的权威预印本平台arXiv上正式发布(论文编号:arXiv:2602 12205v1)。该研究成功开发出一款名为DeepGen 1 0的“轻

西湖大学发布DICE模型 GPU核心生成专用扩散语言模型
2026年2月,一项由西湖大学、香港科技大学及罗彻斯特理工学院联合开展的研究,在AI代码生成领域取得了重要进展。其研究成果——论文arXiv:2602 11715v1——正式发布,介绍了一个名为DICE的扩散大语言模型系列。该模型专为生成高性能CUDA内核代码而设计,相当于为AI时代的“计算引擎设计

小米全能管家AI机器人发布开启能看会说会动新时代
当ChatGPT的对话能力还在刷新我们的认知时,小米机器人团队的目光已经投向了更远的地方:他们希望机器人不仅能听懂我们说什么,更能看懂我们身处的世界,并真正动手为我们解决问题。2026年2月,一项编号为arXiv:2602 12684v1的研究论文正式发布,标志着我们向科幻电影中那种全能型智能助手,








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
