




CVPR 2026 3D视觉前沿:模型如何理解、生成与构建三维世界

从看懂 3D 到生成 4D
让机器真正理解三维空间,而非仅仅模仿二维图像的表面纹理,始终是3D视觉领域面临的核心挑战。其本质在于,如何引导模型超越对图像外观相似性的依赖,深入掌握深层的三维空间结构。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
近期,来自卡内基梅隆大学、Adobe研究院与哈佛大学的联合研究《E-RayZer: Self-supervised 3D Reconstruction as Spatial Visual Pre-training》,精准地瞄准了这一关键问题。他们探索了一种可能性:在不依赖任何3D标注、相机位姿或深度监督信号的情况下,仅凭同一场景的多视角图像,能否让模型自主学会理解空间几何?
答案是肯定的。他们提出的E-RayZer方法,本质上是一个自监督的3D视觉预训练框架。模型接收多张同一场景的图片后,会自主完成一系列推理:首先估计相机参数,接着利用显式的3D高斯分布来构建场景的隐式表示,然后通过可微渲染技术生成目标视角的图像。最终,渲染结果与真实图像之间的差异,便成为驱动模型优化的核心信号。这一完整流程迫使模型必须理解相机运动、三维几何关系以及多视角一致性,从而实现了真正的空间认知能力,而非停留在浅层的图像匹配层面。
不只拼生成,底层表征也在进化
当然,3D视觉的进步并不仅仅体现在“生成一个完整模型”的最终结果上。许多基础性研究工作,更关注模型能否习得可靠、稳定的底层空间表征,为后续各类3D任务(如三维重建、SLAM、新视角合成)奠定坚实的基础。
武汉大学计算机学院与小米EV团队的合作研究《From Pairs to Sequences: Track-Aware Policy Gradients for Keypoint Detection》,便聚焦于一个经典但至关重要的基础问题:3D视觉系统中的关键点检测。尤其是在运动恢复结构(SfM)、同步定位与地图构建(SLAM)等任务中,关键点能否在连续视频帧中保持稳定、具备长期可追踪性,直接决定了整个系统的鲁棒性与精度。
现有方法大多基于图像对进行训练,优化的是两张静态图像之间的匹配性能。然而,在真实的动态视频序列中,挑战远不止于此——剧烈的视角变化、复杂的光照波动、严重的运动模糊都会对关键点的稳定性造成持续冲击。这篇论文提出的TraqPoint方法,其核心思路颇具启发性:它将关键点检测视为一个序列决策问题,并引入强化学习中的策略梯度方法,直接优化关键点在长时间跨度上的可追踪性。这意味着,模型的学习目标从“匹配好当前这一对”升级为“在整个视频序列中都保持稳定可靠”。
从论文到代码,从采集到数据
任何前沿领域的技术突破,都离不开算法创新与工程基建的双轮驱动。对于3D视觉而言,一方面,我们需要更高效的工具将前沿论文快速转化为可运行的代码;另一方面,真实世界任务的推进,也亟需更高质量、更可控的数据资源作为支撑。
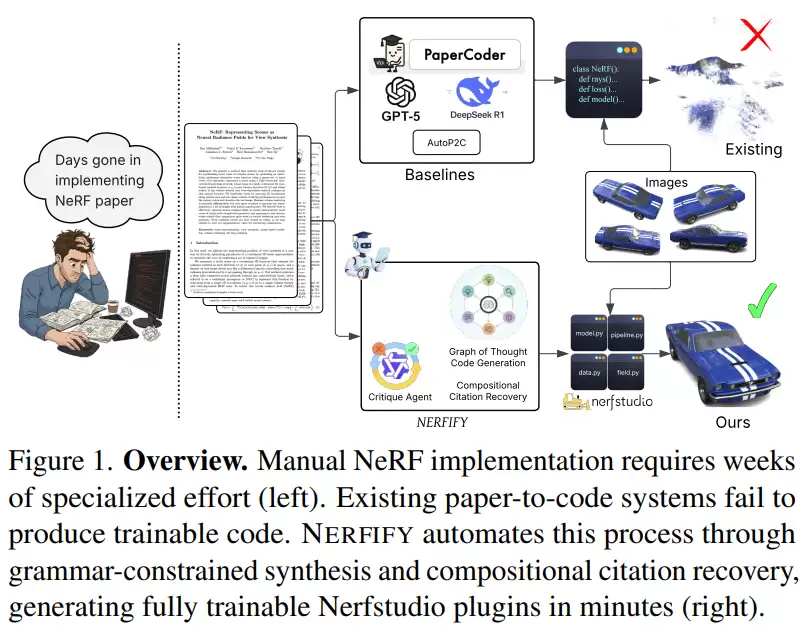
加州大学圣地亚哥分校(UCSD)提出的《NERFIFY: Multi Agent Framework for Turning NeRF Papers into code》,直击了第一个痛点。其核心目标是利用大语言模型智能体,自动将神经辐射场(NeRF)相关的研究论文,转化成能够直接嵌入Nerfstudio框架并训练运行的插件代码。
这并非天方夜谭。研究者们发现,许多NeRF论文并未开源代码,导致复现成本极高。而通用的“论文转代码”工具在面对NeRF这类复杂的视觉任务时,生成的代码往往无法运行或效果不佳。NERFIFY的巧妙之处在于,它设计了一套面向NeRF领域的自动化流水线,将论文解析、依赖恢复、代码生成和训练反馈串联起来。
具体而言,系统首先将论文内容进行结构化解析,并利用Nerfstudio的架构约束形成代码生成规则,确保生成的代码符合基本的模块接口规范。接着,通过“思维图”驱动的多智能体协作,按依赖顺序生成多个代码文件,甚至能自动追踪论文引用中隐藏的关键组件(如特定的采样器、位置编码器)。最后,系统还会根据初步训练后的渲染结果进行视觉质量评估,并自动修正代码中的问题。

因此,它不再是简单地“读论文、写代码”,而是深度融合了领域知识、结构约束和视觉反馈的智能系统。实验表明,在30篇不同复杂度的NeRF论文上,NERFIFY对于无开源代码的论文,其生成结果在视觉质量上已接近专家手写代码的水平,同时将实现周期从数周压缩到了几分钟。这项工作的核心价值,在于显著降低了NeRF研究的复现与二次开发门槛。
如果说NERFIFY试图在工具链上提升效率,那么OLATverse则是在数据基建层面填补关键空白。由马克斯・普朗克信息学研究所和南京大学共同发布的《OLATverse: A Large-scale Real-world Object Dataset with Precise Lighting Control》,旨在为逆渲染、重光照、新视角合成等高级视觉任务提供高质量的数据支撑。
当前,许多先进方法仍严重依赖合成数据训练,或在有限的小规模真实数据上评估,这导致模型在真实场景的材质、光照泛化能力存在明显瓶颈。OLATverse的推出,正是为了破解这一困境。它是一个包含765个真实物体的大规模数据集,其核心优势在于将“大规模物体数量”与“高精度可控光照”完美结合。
数据采集在一个专业的光照舞台(lightstage)中进行,每个物体由35个经过校准的相机环绕拍摄,并受到331个独立可控光源的照射,支持OLAT(单光源)、环境光等多种精确的光照设置。与此同时,数据集还提供了相机参数、物体掩码、表面法线及漫反射反照率等丰富的辅助标注。

以往的数据集往往在“物体数量”和“光照精度”之间难以兼顾,而OLATverse成功地将二者统一。它为模型学习材质、几何与光照之间的复杂解耦关系,提供了一个更贴近真实世界的高质量资源。这不仅可用于训练更鲁棒的重光照和生成先验模型,也可作为逆渲染、法线估计等任务的综合基准测试平台。
当然,论文也坦诚指出,目前数据中的法线和反照率并非严格意义上的绝对物理真值,且未提供物体网格。但无论如何,作为一个兼具规模与精度的真实物体外观数据集,OLATverse无疑为未来的3D视觉与图形学研究提供了极具价值的底层数据燃料。


游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Perplexity订阅收据查询指南:结算中心历史账单查找方法
Perplexity订阅收据由第三方支付平台管理。iOS macOS用户请在Apple账户的“购买记录”中查找;Android用户可在GooglePlay订单历史里查询;网页端用户可通过Stripe邮件中的链接登录客户门户获取历史发票。

即梦AI图文合成教程:如何添加与排版文字
即梦AI图文合成提供多种文字排版方法。文生图阶段可在提示词中用引号嵌入文字,实现图文一体渲染。智能排版助手能自动分析内容并优化布局。艺术字生成结合剪切蒙版可实现图像填充文字的高级效果。局部重绘功能则可对已有文字进行精准的位置与样式修正。

崔汉青谈具身智能发展 筑牢仿真底座加速产业落地
当智能经济的浪潮从虚拟信息空间涌向实体物理世界,一个根本性问题被推至台前:当人工智能不再仅处理文本与图像,而是要驱动机械臂精准操作、引导农机自主巡行于田间时,高质量的“数据燃料”从何而来?物理世界中复杂多变的运行逻辑,又该如何被高保真地数字化复现? 这并非空想。大模型的蓬勃发展,得益于互联网数十年积

香港科大提出渐进式学习新方法提升深度神经网络训练稳定性
人工智能训练常被视为充满复杂数学与庞大算力的领域,但其底层的一些核心挑战,其本质往往与人类学习的基本规律相通。一项由香港科技大学、萨里大学、香港大学及英伟达合作的研究,在2026年3月发布的预印本论文(arXiv:2603 05369v1)中,揭示了一个朴素而深刻的原理:让AI模型模仿人类“循序渐进

Kodiak AI折价融资致股价暴跌 盘后重挫37%
自动驾驶卡车公司KodiakAI完成1亿美元折价融资,股价盘后暴跌37%。融资以每股6 5美元进行,较市价折价近三成。公司一季度营收180万美元,但运营亏损达3780万美元,凸显资金消耗压力。业务方面,Kodiak与多家物流公司达成合作,推进自动驾驶货运试点,并计划在2026年底前实现高速公路无人驾驶运营。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
