




当SFT与RL结合时如何通过样本学习阶段实现动态策略优化

在大模型推理能力提升的后训练阶段,监督微调(SFT)与强化学习(RL)是两种核心优化范式。前者学习稳定高效,能快速吸收高质量示范数据;后者探索潜力巨大,有望驱动模型实现复杂泛化。然而,一个长期存在的挑战是:这两种信号在实际训练中往往难以有效协同,许多现有方法仅停留在将两种损失函数简单混合的层面。

为从根本上解决这一协同难题,研究团队提出了DYPO(动态策略优化)方法。其核心思考直指问题本质:SFT与RL的学习信号在统计性质上存在天然差异,那么,如何设计优化过程,才能在保留监督学习稳定性的同时,充分释放强化学习的探索潜力?
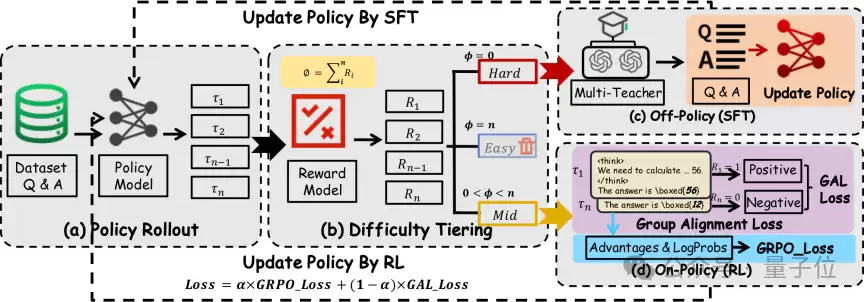
△ 图1:DYPO动态策略优化的整体框架
如图1所示,DYPO的流程始于一个关键决策:模型会先根据一组轨迹采样(rollout)的结果,动态评估每个样本所处的学习阶段,再智能地为其分配监督学习路径、强化学习路径,或选择暂时跳过。
SFT和RL协同训练的核心难点是什么
若将大模型的后训练比作“教导学生解题”,SFT和RL的特性差异便一目了然。
SFT如同老师直接讲解标准答案。其优势在于学习速度快、过程稳定、收敛可控。但弊端也随之显现:学生容易陷入“套路化”解题,一旦题目稍有变化,就可能暴露出泛化能力的不足。
RL则更像让学生自主反复尝试,再根据得分反馈不断调整策略。其长处在于探索性强,更可能引导模型从“记忆解法”迈向“掌握推理”。然而,其缺点同样突出:训练过程波动大,若奖励信号稀疏,模型极易学偏甚至变得不稳定。
从理论层面看,这对应着经典的偏差-方差权衡矛盾:
- SFT:低方差,但高偏差。 其梯度源于静态高质量数据,更新稳定、噪声小,但天然倾向于拟合示范数据的分布,从而压缩了模型的探索空间。
- RL:低偏差,但高方差。 它通过奖励驱动试错,更贴近策略优化的本质,但受采样随机性与奖励稀疏性影响,梯度方差高,训练过程易产生剧烈波动。
问题的症结正在于此。许多统一训练方法虽然同时使用了SFT和RL,却默认所有样本都适用同一种处理方式。但实际情况是,不同样本蕴含的学习信号价值差异显著:
- 简单样本: 模型已完全掌握,多次rollout均能答对,继续训练收益甚微。
- 困难样本: 模型当前完全不会,多次rollout全部失败,此时直接进行RL优化难以获得有效的正向奖励信号。
- 中等难度样本: 模型“已会一点但还不稳定”,rollout结果有对有错。这类样本最具优化价值,既表明模型已触及门槛,又保留了区分正误轨迹的宝贵学习空间。
因此,本研究旨在解决的,并非“是否要将SFT和RL结合”,而是更进一步:针对处于不同学习阶段的样本,应如何匹配最优的优化策略,从而在稳定性与探索性之间找到更精细的平衡?
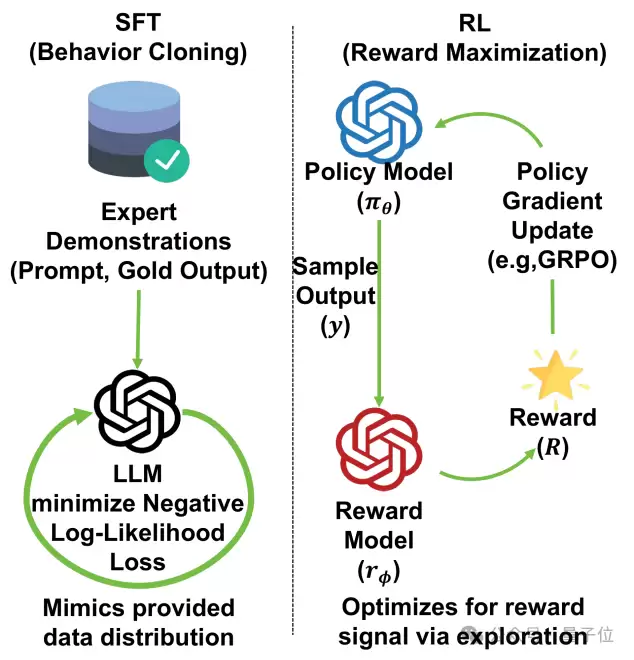
△ 图2:SFT与RL的偏差—方差矛盾示意图
SFT更稳定但偏差更大;RL偏差更低但训练波动更明显。
DYPO如何协同优化偏差与方差
基于上述洞察,DYPO应运而生。其核心思想并非堆砌复杂流程,而是先根据rollout结果判断样本的学习阶段,再为其动态匹配最适宜的优化路径。
具体而言,DYPO会让当前策略为每个问题生成一组rollout,并依据这些轨迹的成败情况,将样本智能划分为三类:
- 简单样本: 一组rollout全部成功。表明模型已掌握此类问题,直接跳过以减少无效计算。
- 困难样本: 一组rollout全部失败。说明模型缺乏必要知识基础,直接进行RL难以获得稳定信号。对此,DYPO采用多教师知识蒸馏,引入多个教师模型,让学生学习多种合理推理轨迹中的共通模式,以此减少单一教师带来的特定偏差,为模型建立可靠先验。
- 中等样本: 一组rollout有成功也有失败,这正是最具价值的“学习前沿”。这类样本适合进行RL优化。但为缓解标准RL的高方差问题,团队在GRPO基础上引入了组对齐损失(GAL)。
GAL的核心思路,是利用同一组rollout中成功与失败轨迹的差异,显式地将模型拉向正确轨迹、推离错误轨迹。这使得RL更新不再仅依赖高噪声的奖励信号,而是额外获得了一层更稳定的相对对齐约束。换言之,GAL的作用并非简单“叠加一个损失函数”,而是在RL更新过程中充当一个动态的方差抑制器。
从理论上总结DYPO的设计逻辑,它实质上是针对SFT和RL各自的核心缺陷精准施策:
- 多教师蒸馏针对困难样本,缓解SFT的高偏差问题。 多个教师的组合可以抵消个体偏差,使得整体监督偏差随教师数量增加而下降。
- GAL针对中等样本,解决RL的高方差问题。 其混合目标的梯度方差严格小于纯GRPO,并且随着模型区分轨迹能力的提升,GAL本身的方差还会进一步自然衰减。
由此可见,DYPO并非简单地将SFT和RL拼凑在一起,而是在结构上将“高偏差的监督学习”和“高方差的强化学习”分别安置在最合适的样本类型上进行处理。正因如此,它更像是一种重新组织后训练过程的方法论框架,而不仅仅是一个孤立的训练技巧。
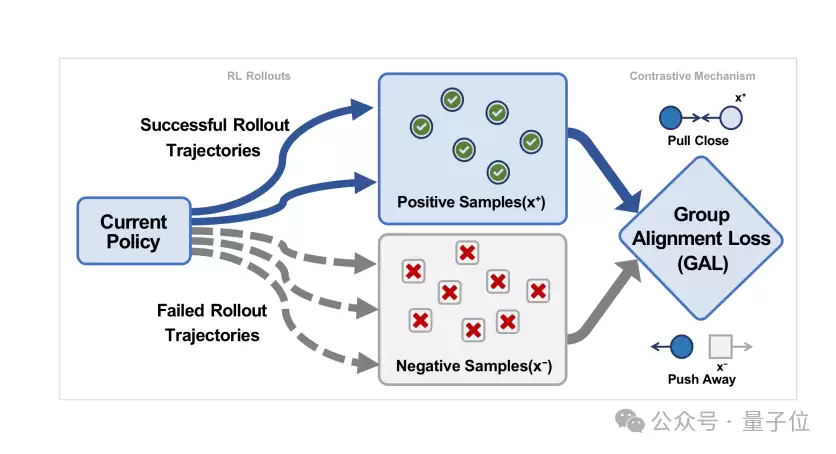
△ 图3:组对齐损失(GAL)的直观机制
如图3所示,它利用同一组rollout中已出现的正负样本,将模型向正确轨迹拉近,同时将错误轨迹推开。
DYPO实验效果与性能分析
研究团队在数学与逻辑推理场景下进行了全面实验,基础模型涵盖Qwen2.5-Math-7B和Qwen3-4B-Base,评测任务包括AIME 2024/2025、AMC、MATH-500、Minerva,以及更侧重分布外泛化能力的ARC-c和GPQA-Diamond。
对于此类工作,最终分数固然重要,但若只看结果,容易将DYPO误解为“又一个效果更好的训练技巧”。真正值得关注的是,它究竟在哪些维度上取得了实质性优势。
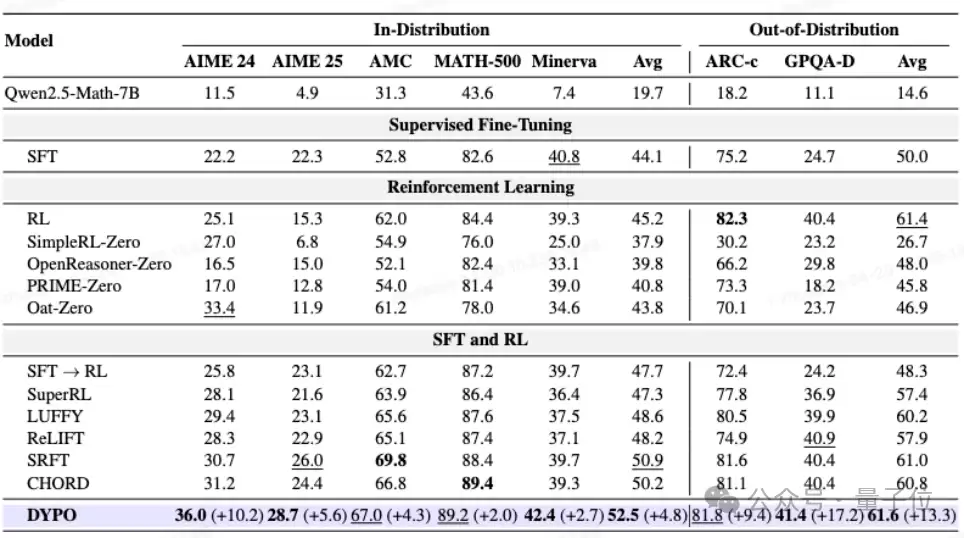
在Qwen2.5-Math-7B上,与传统的SFT→RL顺序流水线相比,DYPO的表现如下:
- 在五个复杂推理基准测试上的平均得分从47.7提升至52.5,显著提升4.8个百分点。
- 在分布外泛化任务上,平均得分从48.3大幅跃升至61.6,提升幅度高达13.3个百分点。
这一提升并非依赖单一任务冲高,而是整体表现更加稳健均衡。尤其在GPQA-Diamond这类更看重迁移与推理能力的任务上,DYPO取得了最佳结果,表明其学到的并非仅仅是更贴近训练数据分布的模板,而是更强的泛化能力。
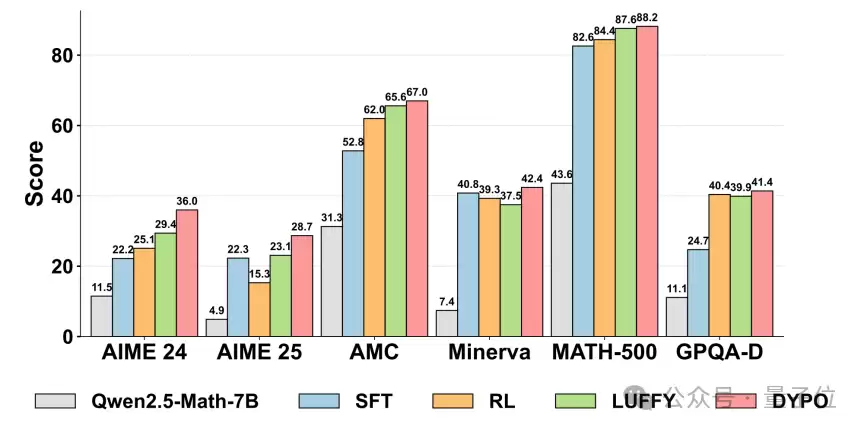
△ 图4:Qwen2.5-Math-7B上的整体结果对比
如图所示,DYPO在复杂推理和分布外任务上均表现出较强的综合优势。
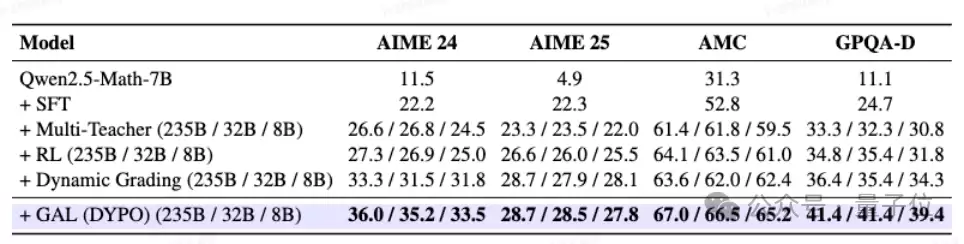
在Qwen3-4B-Base上,类似的优势趋势依然显著。DYPO:
- 在分布内任务上的平均得分达到66.9,明显高于SFT→RL的56.1。
- 在分布外任务上,平均得分达到68.5,也高于后者的52.6。
这说明其性能收益并非依赖于某个特定骨干模型,而更可能源于这套动态分流与优化机制本身。
此外,消融实验进一步验证了方法的有效性。很多时候,方法表现更强可能源于使用了更强的教师模型或更优质的数据。但在此工作中,即便将第二个教师模型替换为能力更弱的Qwen3-8B,DYPO依然能将AIME 25的得分从22.0提升到27.8,将GPQA-Diamond的得分从30.8提升到39.4。这意味着,其提升并非仅仅来自“输入了更多强教师数据”,而是其后的动态路由与低方差优化机制确实发挥了关键作用。
除了最终性能,研究还深入分析了DYPO的训练稳定性。作者追踪了训练过程中离线数据占比、奖励值和策略熵的变化。一个有趣的现象是,DYPO并非一开始就将模型推向强探索,而是随着模型能力提升,逐步降低对监督信号的依赖,让训练自然地实现从“依靠教师引导”到“依赖策略自主探索”的平滑过渡。这个过程类似于一种自适应的课程学习:先稳固基础,再逐步释放探索空间。
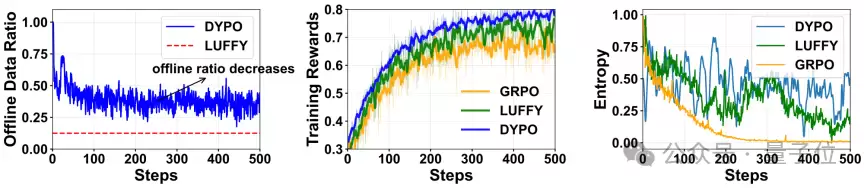
△ 图5:训练动态分析
如图所示,随着训练推进,DYPO会逐步减少对离线监督的依赖,同时保持相对健康的策略多样性。
再看梯度范数。标准GRPO的梯度曲线通常存在明显的剧烈震荡,而DYPO的曲线则平滑得多。这种差异看似是训练细节,但背后对应着一个非常实际的问题:如果梯度持续大幅摆动,训练就更易发散,也更难设置积极的学习率。DYPO在此表现出的稳定性,恰恰说明它对RL部分的高方差更新施加了有效约束。
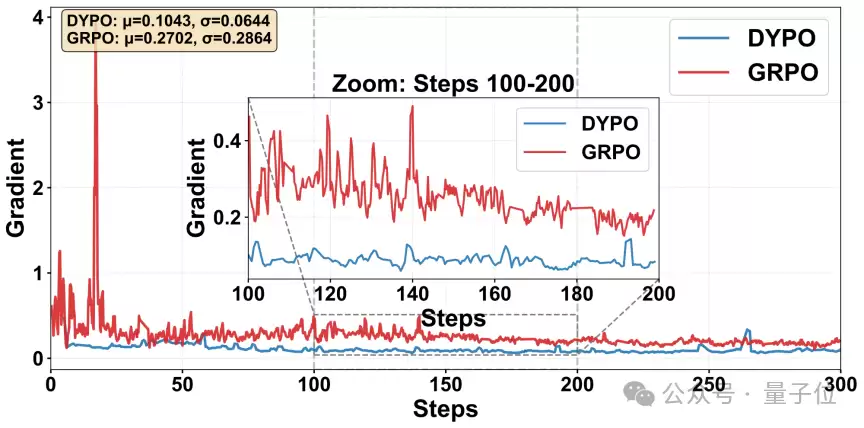
△ 图6:梯度范数对比
如图6所示,与标准GRPO相比,DYPO的更新轨迹更平滑,训练过程更易保持可控与稳定。
总结与展望
DYPO并非意在证明SFT和RL可以一起使用,而是在深入探讨它们应该怎样协同使用。它提供的,是一种更偏向“训练过程智能组织”的新范式。
过往研究已意识到,单纯依赖监督或强化学习,均不足以将大模型的推理能力推向新的高度。但核心难点并非在于设计复杂的目标函数,而在于不同阶段、不同样本所暴露出的学习信号本身存在显著差异。
DYPO的核心贡献,在于将优化逻辑决策前移:先智能判断样本的学习阶段,再动态匹配最优的优化路径。如此一来,SFT负责将模型扶稳打牢基础,RL负责推动模型向外探索未知,二者各司其职、协同增效,而非无差别地混合两种信号。
当然,这项工作也有其适用范围。目前主要验证的是数学与逻辑推理场景,对于开放式对话、创意写作等任务是否同样有效,仍需进一步探索。同时,为稳定估计样本难度,训练时每个提示词需要生成多条(如8条)rollout,这也意味着一定的额外计算开销。
对于持续提升大模型推理能力这一长远目标而言,DYPO或许不是终点,但它无疑指出了一个值得深入探索的新方向:即通过更精细化的训练过程管理,实现监督学习与强化学习的高效协同。
Arxiv Link: https://arxiv.org/pdf/2604.08926
Github Link: https://github.com/Tocci-Zhu/DYPO

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

AI语言模型纽约街头实测:哥本哈根大学研究揭示人机交互安全挑战
这项由哥本哈根大学、IIIT兰契、ISI加尔各答、NIT安得拉邦、IGDTUW、IIT卡拉格普尔、谷歌DeepMind、谷歌以及南卡罗来纳大学AI研究所联合开展的研究,以预印本形式于2026年4月10日发布,论文编号为arXiv:2604 09746。 人工智能助手的能力日益强大,从撰写报告到规划行

字节跳动GRN模型革新AI绘画实现边生成边修改新方法
在探讨AI图像与视频生成技术时,我们通常会想到扩散模型——它如同修复一张被雨水浸湿的照片,通过反复“去噪”从混沌中逐步显现清晰画面。尽管这种方法效果显著,却存在一个根本的效率瓶颈:无论生成内容的复杂程度如何,模型都需要执行固定且繁重的计算步骤,无法智能地分配算力资源。 另一条主流技术路径是自回归模型

斯坦福AI诊断师可自我评估短板并针对性优化
这项由斯坦福大学主导的研究以预印本形式于2026年4月发表,论文编号为arXiv:2604 05336v1。研究提出了一个名为TRACE的系统,全称是“Turning Recurrent Agent failures into Capability-targeted training Environ

Meta AI新研究揭示旧数据复用如何提升40%训练效率
一项由Meta基础人工智能研究团队与纽约大学柯朗研究所联合开展的研究,于2026年4月9日以预印本形式发布,论文编号为arXiv:2604 08706v1。这项研究颠覆了AI训练领域一个长期被视为“金科玉律”的常识。 一、一个反直觉的发现:旧数据“回炉重造”,效果更佳? 在AI模型训练中,数据如同食

AI能否记住你?Kenotic Labs评估体系重新定义人工智能记忆边界
这项由Kenotic Labs开发的研究成果发表于2026年4月的第39届神经信息处理系统大会(NeurIPS 2025),论文编号为arXiv:2604 06710v1。 不知道你有没有过这样的体验:和一位朋友促膝长谈,分享了近期的压力、生活的变动,甚至一些私密的感受。可下次见面,对方却仿佛失忆了








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
