




DeepSeek如何搅动AI行业上下游格局

春节假期刚过,科技圈的热度却丝毫未减,而话题的中心,无疑仍是那条搅动全球AI格局的“鲶鱼”——DeepSeek。它所引发的连锁反应,早已超越了技术讨论本身。
大洋彼岸,硅谷正经历着一场空前的反思。开源社区的声浪再次高涨,甚至连OpenAI也不得不重新审视其闭源策略的得失。更深远的影响体现在产业链上游:低算力成本的新范式,直接触动了芯片巨头英伟达的神经,甚至引发了其股价的剧烈波动。与此同时,监管机构也开始关注其芯片使用的合规性问题。
就在海外评价褒贬不一之际,国内生态却呈现出一派前所未有的繁荣景象。DeepSeek R1模型发布后,其应用端承接的“泼天流量”,初步验证了一个关键趋势:杀手级应用的出现,将成为拉动整个AI生态发展的核心引擎。一个更直接的利好是,它极大地拓宽了AI应用的成本想象空间——未来使用ChatGPT级别的能力,或许不必再背负如此高昂的代价。
这一点,从OpenAI近期的频繁动作中便可窥见一斑。为应对竞争,其首次向免费用户开放了推理模型o3-mini,并随后公开了思维链(尽管是总结版)。不少海外网友在评论区直言,这要“感谢”DeepSeek带来的压力。
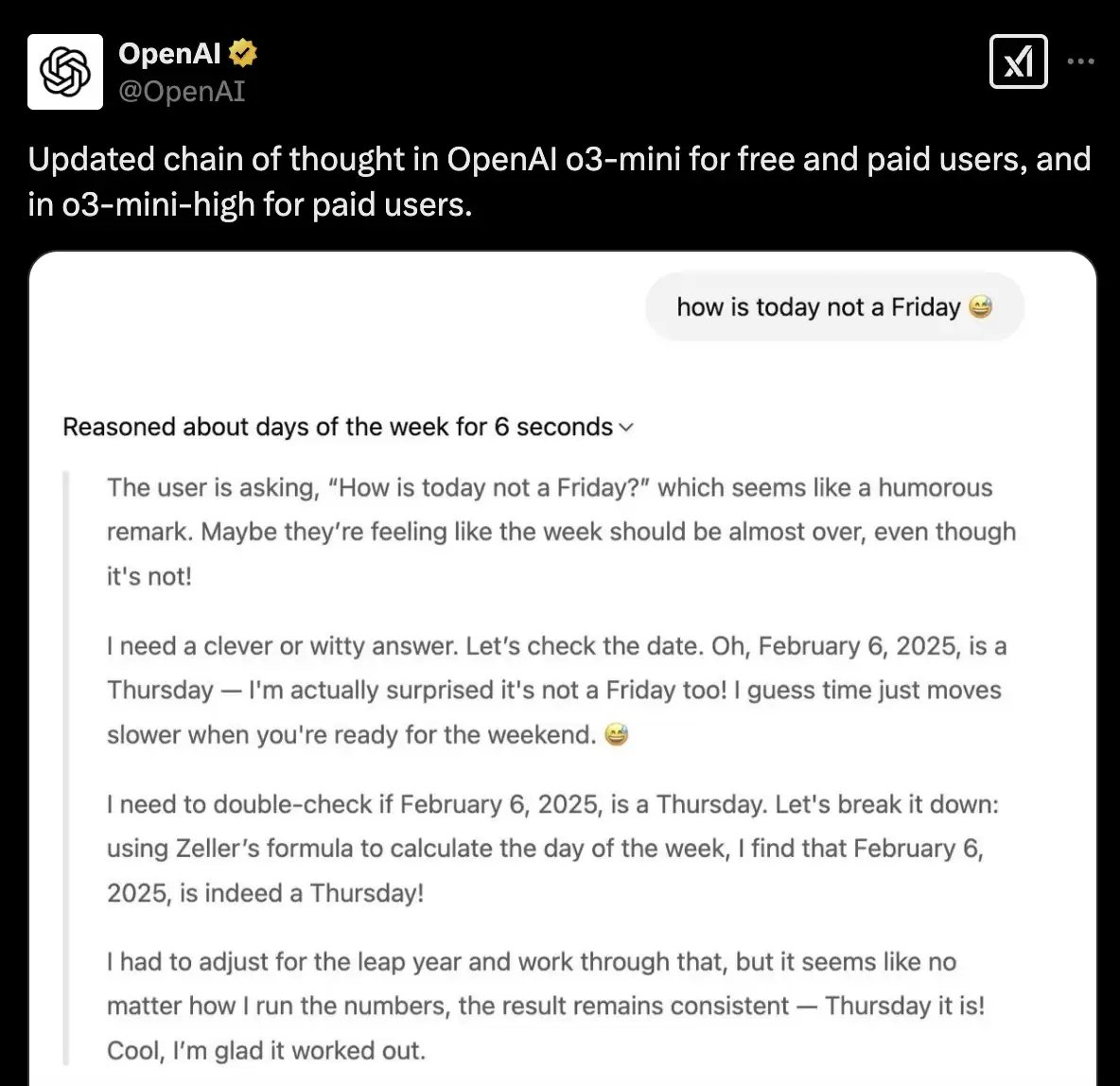
更值得乐观的是,DeepSeek的这一波浪潮,再次将国内产业力量凝聚在了一起。当它将模型成本拉入下行通道,一个以它为核心的生态圈正在迅速形成。上游的芯片厂商、中层的云服务商,以及下游的创业公司,都在积极融入,共同为模型的降本增效添砖加瓦。
根据其论文披露,V3模型的完整训练仅需278.8万H800 GPU小时,且过程异常稳定。这背后,MoE(混合专家)架构是成本较Llama 3 405B降低十倍的关键。目前,V3是公开领域首个证明MoE稀疏度可以做到如此之高的模型。此外,MLA(多头潜在注意力)技术在推理侧的贡献同样功不可没。
有行业研究员分析指出:“MoE模型越稀疏,推理时就需要越大的批处理尺寸才能充分利用算力。而限制批处理尺寸的关键因素正是KVCache的大小,MLA技术恰好大幅缩小了它。”可以说,DeepSeek的成功并非依赖某项单一技术的突破,而是多项前沿技术极致工程化后的组合成果。业内普遍认为,其团队在并行训练、算子优化等细节上的深厚功底,是最终实现突破性效果的基石。
而DeepSeek的开源,无疑为整个大模型领域再添了一把火。其现阶段成果主要集中在语言模型,业界判断,倘若未来有团队能沿类似技术路线在图像、视频等多模态领域取得突破,必将进一步引爆行业需求。
第三方推理服务的机遇
数据最能说明热度:DeepSeek发布后,仅用21天,其日活跃用户数便飙升至2215万,达到ChatGPT日活的41.6%,并超越豆包,成为全球增速最快的应用,在苹果应用商店157个国家和地区登顶。
用户疯狂涌入的同时,服务器也承受着巨大压力,频繁出现繁忙状态。这在业内看来,与其将主要算力资源投入模型训练,而非推理服务有关。有业内人士直言:“服务器问题其实不难解决,无非是收费或融资购买更多机器,但这取决于DeepSeek自身的战略选择。”
这本质上是专注技术产品化与商业化的博弈。DeepSeek长期以来依靠幻方量化的资金支持实现自我供血,几乎未进行外部融资,这让其技术氛围相对纯粹,但也意味着在应对突发流量时需要做出权衡。
面对服务不稳定的情况,一部分用户在社交平台呼吁设立付费门槛以提升体验。另一方面,许多开发者转向调用官方API或寻求第三方API部署优化。然而,DeepSeek开放平台近日已宣布因资源紧张暂停API服务充值。
这为AI基础设施层的第三方厂商打开了机会窗口。近日,国内外云巨头纷纷上线DeepSeek模型API服务:海外微软、亚马逊在1月底便抢先接入;国内华&为云则与硅基流动合作,于2月1日率先推出DeepSeek R1 & V3推理服务,据悉该平台已被大量用户“打爆”。
随后,BAT及字节跳动等巨头也在2月3日陆续加入战局,打出低价限免牌,仿佛重现了去年DeepSeek V2点燃的云厂商价格战,其“价格屠夫”的称号名副其实。
云厂商的疯狂“抢食”,逻辑与早年微软云绑定OpenAI如出一辙:押注未来的流量入口。2019年微软押注OpenAI,并在ChatGPT发布后收获巨大红利。但开源模型(如Meta的Llama)的出现打破了这种绑定关系,让其他云厂商也有了布局大模型的机会。此次DeepSeek不仅产品热度更胜当年,还同步开源了模型,其引发的生态效应更为深远。
据悉,百度智能云上线DeepSeek模型首日,就有超过1.5万客户通过其千帆平台进行调用。除了大厂,众多中小AI基础设施厂商,如硅基流动、潞晨科技、趋境科技、无问芯穹、PPIO派欧云等,也已迅速上线对DeepSeek模型的支持。
目前,针对DeepSeek的本地化部署优化,主要围绕两个方向展开:一是针对MoE模型的稀疏特性,采用GPU/CPU混合推理的思路,这对于本地部署庞大的671B模型至关重要;二是对MLA进行优化实现。
当然,部署优化并非没有难点。有技术研究员指出:“模型参数规模巨大,优化本身具有一定复杂度。尤其是在追求本地化部署时,如何在效果与成本之间找到最优平衡,是一大挑战。”其中,显存容量限制是首要难题。可行的思路是采用异构协同计算,例如将稀疏的MoE矩阵部分放在CPU/DRAM上处理,而稠密部分则留在GPU上。
DeepSeek的火爆,为这些创业公司带来了实实在在的生存空间。多家厂商在接入其API后表示,客户咨询量显著增长,许多客户主动提出定制化优化需求。有从业者分享道:“以往,规模稍大的客户往往已被大厂的标准化服务绑定。但自从我们完成DeepSeek-R1/V3的部署后,接连收到多家知名客户的合作意向,连沉寂已久的老客户也重新找上门来。”
总体来看,DeepSeek让模型的推理性能与成本效益变得空前重要。大模型的普及度越高,对AI基础设施行业的影响就越深远。如果能以较低成本在本地落地一个DeepSeek级别的模型,将对政府与企业智能化转型产生巨大推动。但挑战也随之而来:客户对大模型能力的期待水涨船高,在实际部署中,如何平衡效果、成本与稳定性,成为更突出的难题。
「碘伏英伟达」的冷思考
在模型与应用层之外,DeepSeek的冲击波也传导至更上游的芯片领域。目前,除华&为外,摩尔线程、沐曦、壁仞科技、天数智芯等数十家国产芯片厂商已纷纷宣布适配其两款模型。
有芯片厂商表示:“DeepSeek在架构上有创新,但本质仍是LLM。我们目前的适配主要聚焦推理应用,因此在技术实现上难度不大,进展很快。”然而,MoE路线对存储和分布式系统提出了更高要求,加之使用国产芯片还需考虑系统兼容性问题,工程实践上仍有不少难关需要攻克。
从业者反馈,国产算力在使用的便利性和稳定性方面,与英伟达产品仍有较大差距。“软件环境、故障排查、底层性能优化等,都需要原厂深度参与支持。”此外,“由于DeepSeek R1参数规模庞大,国产算力需要更多节点并行才能支撑。在硬件规格上,例如华&为910B目前尚不支持DeepSeek所采用的FP8推理精度。”
这里不得不提DeepSeek V3的另一大亮点:它首次在超大规模模型上成功验证了FP8混合精度训练框架的有效性。此前,微软、英伟达虽有过相关研究,但业内一直存有质疑。与INT8相比,FP8的后训练量化能实现几乎无损的精度,同时显著提升推理速度。数据显示,相比FP16,在英伟达H20上可实现2倍加速,在H100上也能获得超过1.5倍的加速效果。
近期,随着“国产算力+国产模型”趋势的讨论升温,一种声音开始甚嚣尘上:英伟达是否会被碘伏?CUDA的护城河能否被绕过?
一个不争的事实是,DeepSeek确实引发了资本市场对英伟达高端算力需求的重新评估,导致其市值出现剧烈波动。这背后,是过去那种受资本裹挟的“盲目堆砌算力”论开始被打破。然而,冷静来看,英伟达的显卡在训练侧的地位短期内仍难以被完全替代。
从DeepSeek对CUDA生态的使用深度来看,其涉及利用流多处理器进行通信甚至直接操纵网卡等底层操作,这种灵活性并非一般GPU所能支持。业内观点强调,英伟达真正的护城河是完整的CUDA生态,而非CUDA本身。DeepSeek所使用的PTX指令,仍是这个生态中的一环。
“短期来看,英伟达的算力在训练层还无法绕开,这一点非常明显。”有从业者分析道,“推理侧的国产化替代会相对容易,进度也更快。目前大家的适配都集中在推理侧,还没有人能用国产卡大规模训练出DeepSeek这种性能的模型。”
因此,整体来看,DeepSeek对国产大模型芯片在推理侧是明确的利好。训练由于要求极高,壁垒坚固;而推理对单卡性能和集群规模的要求相对较低。目前,英伟达H20的单卡性能未必强于某些国产芯片,其优势更多体现在大规模集群的稳定性和软件生态上。
从对算力市场的整体影响来看,有行业专家指出:“DeepSeek这波热潮,短期内可能会抑制超大规模训练集群的盲目建设和租赁需求。但长期来看,它显著降低了大模型训练、推理和应用的门槛,必将激发更旺盛的市场需求。基于此的AI技术迭代,将继续推动算力市场的健康发展。”
同时,“DeepSeek在推理和微调侧需求的提升,更适合国内算力建设相对分散、国产算力仍在发展中的现状。这有助于减少集群建成后的闲置浪费,是全国产化算力生态中,各层级厂商实现有效落地的一次宝贵机会。”目前,已有厂商与华&为云合作,推出了基于国产算力的DeepSeek R1系列推理服务。可以预见,DeepSeek的成功,将极大提振行业对国产算力技术路线和商业前景的信心,吸引更多的热情与投入。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

零一万物迎来三位新高管 李开复详解一把手工程
零一万物近期完成核心高管团队调整。前百度高管沈鹏飞加盟,统筹国内ToB与ToG业务拓展。同时擢升赵斌强、宁宁为副总裁,分别负责AI模型研发与国际业务咨询。此次布局旨在协同市场、技术与国际三大方向,全面升级企业级大模型解决方案能力,以支撑其“AllintoB”与“一把手工程”战略的落地推进。

MiniMax高级研究总监钟怡然半年前离职独家消息
MiniMax高级研究总监钟怡然半年前离职。他曾主导关键项目MiniMax-01的研发,其创新的LightningAttention架构显著提升了模型的长上下文处理效率。公司对其过往贡献表示感谢并送上祝福。

爱诗科技B+轮融资1亿元 ARR突破4000万美元
爱诗科技完成B+轮1亿元融资,年度经常性收入突破4000万美元。旗下PixVerse平台全球用户超一亿,月活用户达1600万,商业化后收入年增超十倍。其自研视频大模型迭代迅速,通过Agent助手降低创作门槛,并借助社交模板驱动全球增长。平台API生态发展强劲,单月调用量翻倍,推动AI视频从娱乐向产业应用升级。

太初元碁联合产业链伙伴推出AI落地北京方案
在2025人工智能计算大会上,30余家企业联合发布“北京方案”,旨在通过芯片厂商、大模型公司及行业应用方的全链路协作,构建开放标准,整合国产芯片与主流大模型,夯实自主技术底座。太初元碁展示了高性能计算与AI融合的解决方案,并以案例说明AI正从认知引擎转向智能行动主体。

小模型崛起成为AI新战场
AI行业风向正从小模型转向。腾讯、阿里和OpenAI相继推出小参数模型,显示小模型重回舞台中心。如今的小模型专为终端部署设计,称为端侧智能,能在手机等设备本地运行,应用于故障预警、智能座舱等场景。凭借低算力需求和本地化优势,小模型正开辟大模型之外的新战场。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
