




之江实验室薛贵荣谈AI科研与大语言模型发展瓶颈

12月12日,第八届GAIR全球人工智能与机器人大会在深圳正式开幕。这场为期两天的行业顶级峰会,由GAIR研究院联合主办,高文院士担任指导委员会主席,杨强院士与朱晓蕊教授共同出任大会主席。
作为洞察AI技术演进与产业生态变革的关键窗口,GAIR大会自2016年创办以来,始终与全球人工智能发展的脉搏同频共振,完整见证了技术浪潮从实验室研究涌向产业化落地的全过程。2025年,正值大模型从“技术突破”迈向“价值深耕”的关键转折点,本届GAIR大会汇聚全球顶尖智者,共同触摸AI最前沿的发展脉动,深度洞见产业发展的底层逻辑与未来趋势。
会上,之江实验室科学模型总体组技术总师、天壤智能CEO薛贵荣博士带来了深度分享。他指出,以大语言模型为代表的AI技术虽已在多个学科研究中展现出巨大潜力,但其能力本质上仍受限于“语言的边界”,难以真正理解高维度、多模态的科学数据,更无法独立完成可验证、可复现的科学发现。
基于此,薛贵荣博士系统剖析了大语言模型与科学基础模型之间的本质差异,并详细阐述了之江实验室研发的021科学基础模型在突破语言维度局限、统一科学数据表征、实现复杂科学推理与发现以及促进跨学科知识融合等方面的核心优势。同时,他也分享了对于“AI+科学”融合新范式的前沿思考:
- 大语言模型在解决复杂科学问题上仍存在显著瓶颈。在覆盖100多个学科的高难度HLE基准测试中,目前表现最优的模型准确率也仅为25.4%。
- 要真正赋能科学研究,科学基础模型必须超越文本语言空间,具备理解化学结构、天文观测、地球科学数据、生命科学序列等多类型、高维度科学知识的能力。
- 科学基础模型与当前大语言模型的核心差异在于数据根基:大语言模型以文本数据作为Token化的基础,而科学基础模型所处理与理解的Token是跨学科、多模态的科学数据。
- 实现科学数据Token化的前提是攻克OneTokenizer难题,即将光谱、化学分子式、DNA序列等异构数据结构化后,映射并统一到一个高维语义空间中。
- 科学数据完成Token化并对齐后,能够建立起不同数据类型之间的深层次关联,从而在解决跨学科、跨领域的复杂科学问题时,实现端到端的全链路解析与推理。
- 为突破大语言模型解决科学问题的固有局限,之江实验室推出了021科学基础模型。该模型旨在对科学世界形成客观、全面的认知体系,并具备快速、精准、高泛化性的科学知识问答与发现能力。
01 为什么说大语言模型不够用了?
接下来,我们聚焦之江实验室在科学基础模型领域的前沿探索。
今年,我国明确了“人工智能+”发展战略,其中首要方向便是“AI+科学技术”。那么,人工智能究竟如何深度赋能科学研究?又如何将其潜力转化为真正可用的科学基础模型?这正是我们需要深入探讨的核心议题。
“AI+科学”是一个兼具巨大挑战性与无限潜力的前沿领域。上个月,美国启动了被称为“AI曼哈顿计划”的“创世纪计划”。众所周知,历史上的曼哈顿计划集结了空前规模的工程师与科学家,完成了划时代的科技工程。而“创世纪计划”则动员了17个国家实验室、超过4万名科研人员,被视为冷战以来对联邦科技资源的最大规模动员。该计划目标清晰、阶段明确,旨在推动人工智能技术在基础科学领域产出革命性成果。

该项目相关负责人Dario Gil提出,人工智能的科学应用可以从人机对话交互开始。但AI对科研的真正价值远不止于生成文献摘要,更在于驱动形成可验证、可重复的科学结论。这需要调用强大的模型能力以及整合实验室数十年来积累的海量数据,构建高质量、可验证、可迭代的科学数据集,通过持续训练优化模型,最终将能力赋能于整个科技创新链条。
事实上,人工智能技术在科研中的应用已有较长历史。我们需重点审视当前大语言模型在其中扮演的角色与面临的挑战。

一份汇聚了众多科学家智慧的前沿报告,总结了当前人工智能在科学发现中能助力解决的五大类问题:多模态与多尺度学习、迁移学习、数字孪生、实验自动设计与交互式学习。
那么,当下的AI在科研工作中究竟扮演着什么角色?同一项调查显示,在1600名研究人员中,有三分之二认为AI工具显著改进了他们的数据处理方法与流程,超过一半的受访者认为AI大幅加快了计算速度,有效节省了科研成本与时间。
2024年,当今数学界最年轻的菲尔兹奖得主陶哲轩预言,到2026年,人工智能将成为数学研究中值得信赖的协作伙伴。他本人积极应用AI进行科研探索,近期便利用GPT-5 Pro成功辅助探索了微分几何领域的难题“有界曲率球体问题”的本质。有趣的是,这并非他原本擅长的研究领域。这似乎预示着一个新时代的开启:借助强大的人工智能,科研人员能够探索并攻克更多以往难以触及的科学难题。
OpenAI近期也启动了“OpenAI for Science”新倡议,旨在打造一个由AI驱动、能够加速科学发现的开放平台,并已在量子场论推导、干细胞相关蛋白质结构优化等问题上取得初步进展。最近,他们甚至招募了一位研究黑洞的天文学家亚历克斯·卢斯帕卡,以帮助定位银河系中的黑洞。此前,这位研究人员花费数日计算出的“黑洞扰动理论中新对称性”的精确数学形式,GPT-5 Pro仅用30分钟便辅助完成。
02 科学基础模型如何补齐LLM的科研短板?
尽管大语言模型在诸多科学问答和推理任务上表现出色,但要真正深度服务于严肃的科学研究,它仍面临诸多根本性挑战。
语言是人类交流思想的核心符号系统,堪称人类认知皇冠上的明珠。正如哲学家维特根斯坦所言:“语言的边界,就是世界的边界。”如今,人们希望用代表人类认知精华的语言模型来解决复杂的科学问题。然而,根据HLE发布的最新评估研究,大语言模型在深度科学知识与复杂推理方面的能力,尚未触及人类专家认知的极限。在覆盖100多个学科的高难度HLE测试中,性能最优模型的平均准确率仅为25.4%。
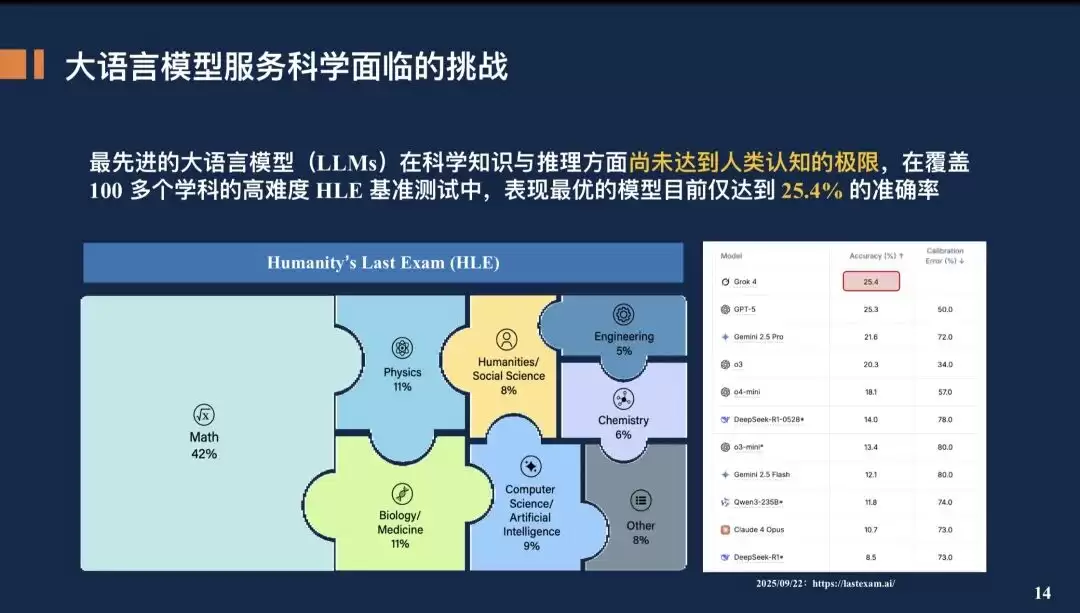
因此,当前仅依靠大语言模型来服务科学研究存在巨大鸿沟。要真正成为科学家的得力工具,模型必须跨越语言的文本边界,真正学会理解分子结构、基因序列、地震波谱、天体光谱等各种高维、复杂的科学数据。
常言道,一图胜千言。视觉图像是表达与传递信息的另一重要渠道。但在前沿科学领域,还存在更多元、更复杂的数据形式,例如光谱数据。可以说,一张精细的光谱图所蕴含的物理化学信息,其深度与广度远超千万张普通图片。
无论是在遥感观测还是在化学材料分析中,光谱仪都是关键设备,其产生的光谱数据不仅能定性揭示物质“是什么”,还能通过特征波段与强度定量反映其元素构成与状态。
另一类至关重要的科学数据来自生命科学领域——基因序列。基因信息量极其庞大,每个人类细胞核中携带的DNA序列约由30亿个碱基对组成。有分析指出,一个咖啡杯容量体积的DNA就能存储全世界当前所有的数据。如此超长的序列,其表达的生命信息维度也极高。
再看地球科学中的典型数据:地震波。它就像是地球内部活动的语言,告诉我们哪里正在或可能发生地震。当然,地震波的意义远不止于地震预警,它还能反演揭示地下岩层结构与资源分布。寻找石油与矿产,必须清晰了解地下空间构造,而地震波数据分析正是最关键的技术手段之一。与光谱类似,地震波信号也是一种极其复杂、蕴含丰富信息的数据表达形式。
根据香农信息论和经典语言学模型,自然语言本质上是一种相对低维的离散符号系统。而科学数据往往包含了时间、空间、频率、能量等多维度连续或离散的特性,其所需表达的信息维度空间,远非文本语言所能完全描述与覆盖。
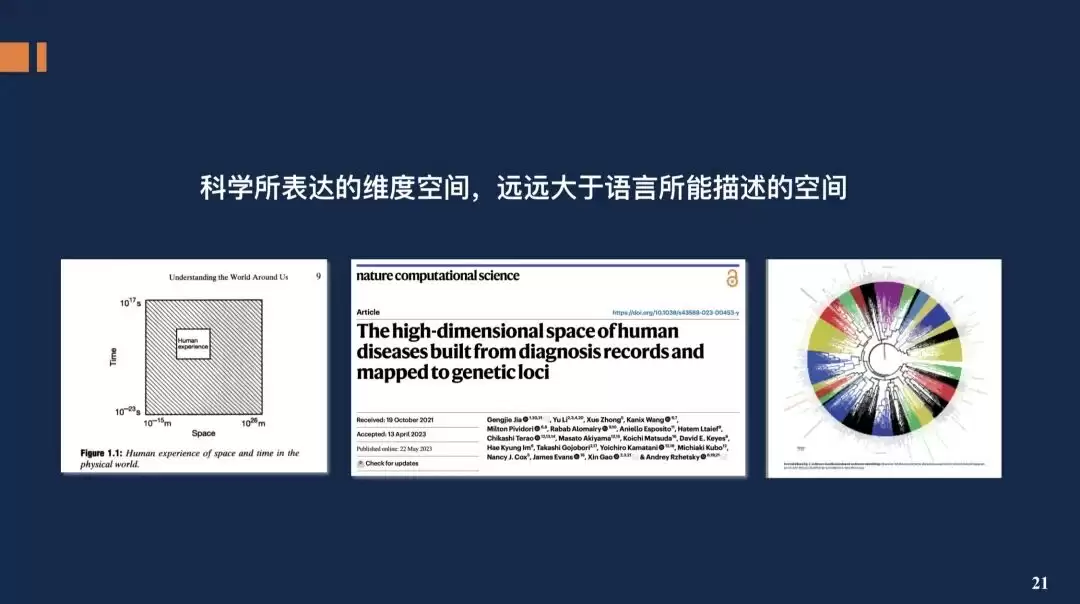
从上图可以看出,语言文本表达所能覆盖的信息维度,只是整个科学认知空间中非常有限的一部分。再看右侧,与人类疾病研究相关的所有学科知识,其数据维度高达二十几种。如果仅用文本语言来描述我们所理解的复杂科学世界,其表达空间将受到极大限制。我们希望,新一代的科学基础模型能够攻克这一核心难题。
科学基础模型与当前的大语言模型存在本质区别。
首先是数据维度的根本不同。当前的大语言模型仍以文本数据作为Token化的唯一或主要基础。而科学基础模型所要表达与处理的科学数据Token,存在于“高维科学数据空间”与“语言语义空间”的结合体中,其整体维度与复杂性远超纯文本语言空间。这里所说的空间,是跨学科、多模态、多类型的。实现这一点极具挑战,而其首要前提是如何有效地对异构科学数据进行统一Token化,即解决OneTokenizer的关键问题。
所谓的OneTokenizer,就是尽可能将我们所面对的一切科学数据表征统一起来。包括前述的光谱、化学分子式、蛋白质三维结构、DNA序列、地震波数据等,我们都希望将其转化为结构化的Token,并嵌入到同一个高维语义表征空间里。

当然,这些数据本身有其特定的专业表达方式,例如化学中的分子式。我们的目标是,即便最终用文本序列来描述,也能将它们清晰地区分与表示。例如,同一个字母“C”,在分子式(代表碳原子)、蛋白质序列(可能代表半胱氨酸)、DNA序列(代表胞嘧啶)以及普通英文单词中,其含义与背后的数据结构是截然不同的。
这是一项极其复杂的系统工程,要真正做好,不仅需要人工智能科学家,还需要化学、生物、物理、地学等众多领域科学家的深度协作与知识注入。
这正是我们持续推进的核心工作:将基因组学数据、细胞组学数据、物质光谱数据、晶体材料数据、时空序列数据、三维空间结构数据等全部进行Token化,并将其表征对齐到统一的语义空间中。
其次,在完成Token化之后,许多跨模态、跨学科的数据之间就实现了“表征对齐”,这也是科学数据治理的核心环节。正如之前郑宇老师所讲,城市多源数据需要对齐,科学数据同样如此。只有完成数据对齐,真正的、可关联的科学发现才成为可能。
以下四个案例可以解释数据对齐的巨大价值:
- 动物迁移与环境变化关联分析:大雁为何南飞?仅仅是本能地随季节温度变化而飞行吗?通过对齐全球长期温度变化数据与鸟类迁徙卫星追踪轨迹数据,可以发现,鸟类的迁徙路径与时间选择与区域温度变化模式密切相关,这实际上是从生物感知与行为适应角度做出的科学解释。
- 城市住房密度与热岛效应关联:这与城市科学数据相关。如果能将人口分布、建筑密度、地表温度遥感数据很好地对齐分析,将极大助力于我们发现城市生态规律。
- 区域GDP变化与夜间灯光分布关联:太空中拍摄的夜间灯光图像亮度与分布,与地面社会经济活动(如GDP)的变化之间存在强相关性,这对宏观经济监测具有重要意义。
- 多源天文观测数据融合:不同卫星与地面望远镜对同一颗恒星或星系进行拍摄,一种图像分辨率高但视野窄,另一种视野广但分辨率低。虽然观测目标一致(已对齐),但数据质量与信息侧重不同。将这两种数据进行融合与对齐分析,可能催生新的天体物理发现。
通过将多学科数据Token化,并建立数据间的深层次关联与对齐——就像将基因型(DNA序列)、表型(蛋白质功能)与疾病临床表征对齐一样——我们便能进行贯穿“数据-知识-假设-验证”的全链路科学解析与发现。
从零到一,我们训练了021科学基础模型。这个过程异常复杂且充满挑战,不仅需要充足的算力支撑和海量的高质量科学数据,还需要设计高效的模型训练架构与流程。我们经历了大规模预训练、条件预测训练(CPT)、长序列条件预测(Long CPT)、有监督微调(SFT)、思维链微调(CoT SFT),再到基于人类反馈的强化学习(RLHF)等多个关键阶段。目前,该模型仍在内部进行严格的测试、评估与持续优化中。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

言犀人机交互平台功能详解与应用场景全解析
在数字化转型的关键时期,企业如何选择真正懂业务、能落地的智能伙伴?言犀,作为京东基于十年客户服务与营销实战经验打造的全链路智能平台,提供了一个值得深入考察的选项。它不仅仅是一套工具,更是一个深度融合行业Know-How与前沿AI技术的平台级解决方案,致力于为政务、金融、零售、教育等多行业客户,提供覆

中文自媒体大模型MediaGPT训练与应用指南
通用大模型的能力有目共睹,但在高度垂直的领域,比如自媒体创作、直播和运营,它们往往显得有些“力不从心”。究其原因,还是缺乏针对性的“专业训练”。为了填补这个空白,我们推出了MediaGPT(曾用名MediaLLaMA),一个专门为中文自媒体领域打造的大模型。 它的训练路径非常清晰:首先,我们让模型在

百贝AI企业级智能体平台赋能下一代AI应用开发
在内容为王的时代,企业如何高效产出高质量、风格统一的营销素材,同时确保数据安全,成了一个关键挑战。今天,我们来聊聊一个专注于解决这些问题的平台——百贝AI。 简单来说,百贝AI是一个为企业量身打造的AI内容生成平台。它的核心逻辑是,先深入学习企业的品牌调性、产品信息、用户画像乃至内容风格,然后基于这

山海大模型:你的AI良师益友与智能助手
在人工智能技术飞速发展的当下,大规模预训练模型已成为推动产业变革的关键引擎。云知声推出的“山海大模型”,正是面向这一趋势打造的新一代认知智能平台。它不仅是一个先进的对话系统,更被定位为覆盖多行业、多场景的通用智能基座,致力于成为用户工作与生活中可信赖的“智能伙伴”与“效率助手”。 核心优势:超越传统

BenTsao本草中文医学大语言模型详解与应用
在中文医疗健康领域,专业信息的精准获取与高效决策支持一直是核心需求。随着人工智能技术的成熟与落地,一款专为中文医学场景深度定制的大语言模型——BenTsao本草(原名:华驼)——正成为医疗从业者关注的焦点。它并非通用聊天机器人,而是一个基于大规模中文医学语料训练并经过精细指令微调的专业模型,旨在成为








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
